最小二乘法、梯度下降法以及最大似然法之间区别整理
一、最小二乘法(least square method)
转自https://blog.csdn.net/suibianshen2012/article/details/51532003
1.背景
先看下百度百科的介绍:最小二乘法(又称最小平方法)是一种数学优化技术。它通过最小化误差的平方和寻找数据的最佳函数匹配。利用最小二乘法可以简便地求得未知的数据,并使得这些求得的数据与实际数据之间误差的平方和为最小。最小二乘法还可用于曲线拟合。其他一些优化问题也可通过最小化能量或最大化熵用最小二乘法来表达。
通过这段描述可以看出来,最小二乘法也是一种优化方法,求得目标函数的最优值。并且也可以用于曲线拟合,来解决回归问题。难怪《统计学习方法》中提到,回归学习最常用的损失函数是平方损失函数,在此情况下,回归问题可以著名的最小二乘法来解决。看来最小二乘法果然是机器学习领域做有名和有效的算法之一。
2.最小二乘法原理
我们以最简单的一元线性模型来解释最小二乘法。什么是一元线性模型呢? 监督学习中,如果预测的变量是离散的,我们称其为分类(如决策树,支持向量机等),如果预测的变量是连续的,我们称其为回归。回归分析中,如果只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析。对于二维空间线性是一条直线;对于三维空间线性是一个平面,对于多维空间线性是一个超平面...
对于一元线性回归模型, 假设从总体中获取了n组观察值(X1,Y1),(X2,Y2), …,(Xn,Yn)。对于平面中的这n个点,可以使用无数条曲线来拟合。要求样本回归函数尽可能好地拟合这组值。综合起来看,这条直线处于样本数据的中心位置最合理。 选择最佳拟合曲线的标准可以确定为:使总的拟合误差(即总残差)达到最小。有以下三个标准可以选择:
(1)用“残差和最小”确定直线位置是一个途径。但很快发现计算“残差和”存在相互抵消的问题。
(2)用“残差绝对值和最小”确定直线位置也是一个途径。但绝对值的计算比较麻烦。
(3)最小二乘法的原则是以“残差平方和最小”确定直线位置。用最小二乘法除了计算比较方便外,得到的估计量还具有优良特性。这种方法对异常值非常敏感。
最常用的是普通最小二乘法( Ordinary Least Square,OLS):所选择的回归模型应该使所有观察值的残差平方和达到最小。(Q为残差平方和)- 即采用平方损失函数。
样本回归模型:
 其中ei为样本(Xi, Yi)的误差
其中ei为样本(Xi, Yi)的误差
平方损失函数:
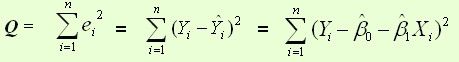
则通过Q最小确定这条直线,即确定![]() ,以
,以![]() 为变量,把它们看作是Q的函数,就变成了一个求极值的问题,可以通过求导数得到。求Q对两个待估参数的偏导数:
为变量,把它们看作是Q的函数,就变成了一个求极值的问题,可以通过求导数得到。求Q对两个待估参数的偏导数:
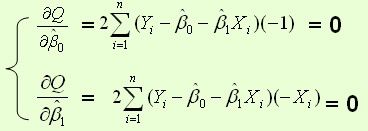
根据数学知识我们知道,函数的极值点为偏导为0的点。
解得:
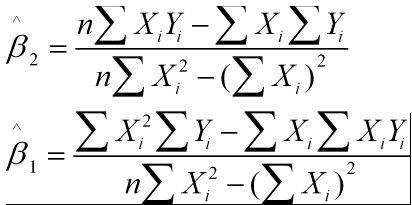
这就是最小二乘法的解法,就是求得平方损失函数的极值点。
二、最大似然法(maximum likelihood function)
转自 https://blog.csdn.net/zengxiantao1994/article/details/72787849
1.原理
极大似然估计的原理,用一张图片来说明,如下图所示:

总结起来,最大似然估计的目的就是:利用已知的样本结果,反推最有可能(最大概率)导致这样结果的参数值。
原理:极大似然估计是建立在极大似然原理的基础上的一个统计方法,是概率论在统计学中的应用。极大似然估计提供了一种给定观察数据来评估模型参数的方法,即:“模型已定,参数未知”。通过若干次试验,观察其结果,利用试验结果得到某个参数值能够使样本出现的概率为最大,则称为极大似然估计。
由于样本集中的样本都是独立同分布,可以只考虑一类样本集D,来估计参数向量θ。记已知的样本集为:

似然函数(linkehood function):联合概率密度函数![]() 称为相对于
称为相对于![]() 的θ的似然函数。
的θ的似然函数。

如果![]() 是参数空间中能使似然函数
是参数空间中能使似然函数![]() 最大的θ值,则
最大的θ值,则![]() 应该是“最可能”的参数值,那么
应该是“最可能”的参数值,那么![]() 就是θ的极大似然估计量。它是样本集的函数,记作:
就是θ的极大似然估计量。它是样本集的函数,记作:

2.求解极大似然函数
ML估计:求使得出现该组样本的概率最大的θ值。

实际中为了便于分析,定义了对数似然函数:
![]()

1. 未知参数只有一个(θ为标量)
在似然函数满足连续、可微的正则条件下,极大似然估计量是下面微分方程的解:

2.未知参数有多个(θ为向量)
则θ可表示为具有S个分量的未知向量:
![]()
记梯度算子:

若似然函数满足连续可导的条件,则最大似然估计量就是如下方程的解。

方程的解只是一个估计值,只有在样本数趋于无限多的时候,它才会接近于真实值。
3.极大似然估计的例子
例1:设样本服从正态分布![]() ,则似然函数为:
,则似然函数为:
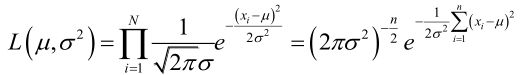
它的对数:

求导,得方程组:

联合解得:
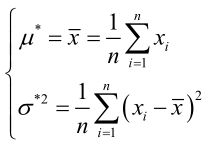
似然方程有唯一解 :,而且它一定是最大值点,这是因为当
:,而且它一定是最大值点,这是因为当![]() 或
或![]() 时,非负函数
时,非负函数![]() 。于是U和
。于是U和![]() 的极大似然估计为。
的极大似然估计为。
例2:设样本服从均匀分布[a, b]。则X的概率密度函数:
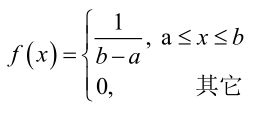
对样本![]() :
:

很显然,L(a,b)作为a和b的二元函数是不连续的,这时不能用导数来求解。而必须从极大似然估计的定义出发,求L(a,b)的最大值,为使L(a,b)达到最大,b-a应该尽可能地小,但b又不能小于![]() ,否则,L(a,b)=0。类似地a不能大过
,否则,L(a,b)=0。类似地a不能大过![]() ,因此,a和b的极大似然估计:
,因此,a和b的极大似然估计:

4.总结
求最大似然估计量![]() 的一般步骤:
的一般步骤:
(1)写出似然函数;
(2)对似然函数取对数,并整理;
(3)求导数;
(4)解似然方程。
最大似然估计的特点:
1.比其他估计方法更加简单;
2.收敛性:无偏或者渐近无偏,当样本数目增加时,收敛性质会更好;
3.如果假设的类条件概率模型正确,则通常能获得较好的结果。但如果假设模型出现偏差,将导致非常差的估计结果。
三、区别
1.最小二乘法VS梯度下降
转自 https://blog.csdn.net/suibianshen2012/article/details/51532003
最小二乘法跟梯度下降法都是通过求导来求损失函数的最小值,那它们有什么区别呢。
- 相同
1.本质相同:两种方法都是在给定已知数据(independent & dependent variables)的前提下对dependent variables算出出一个一般性的估值函数。然后对给定新数据的dependent variables进行估算。
2.目标相同:都是在已知数据的框架内,使得估算值与实际值的总平方差尽量更小(事实上未必一定要使用平方),估算值与实际值的总平方差的公式为:
其中为第i组数据的independent variable,为第i组数据的dependent variable,为系数向量。
- 不同
1.实现方法和结果不同:最小二乘法是直接对求导找出全局最小,是非迭代法。而梯度下降法是一种迭代法,先给定一个,然后向下降最快的方向调整,在若干次迭代之后找到局部最小。梯度下降法的缺点是到最小点的时候收敛速度变慢,并且对初始点的选择极为敏感,其改进大多是在这两方面下功夫。
2.最小二乘法VS最大似然估计
转自 https://blog.csdn.net/lu597203933/article/details/45032607
- 不同
对于最小二乘法,当从模型总体随机抽取n组样本观测值后,最合理的参数估计量应该使模型最好地拟合样本数据,也就是使估计值和观测值之差的平方和最小。而对于最大似然法,当从模型中随机抽取n组样本观测值之后,最合理的参数估计量应该使得从模型中抽取的该n组样本观测值的概率最大。显然,这是从不同的原理出发的两种参数估计方法。
- 相同
在最大似然法中,通过选择参数,使已知数据在某种意义下最有可能出现,而某种意义通常指似然函数最大,而似然函数又往往指数据的概率分布函数。与最小二乘法不同的是,最大似然法需要已知这个概率分布函数,这在实践中是很困难的。一般假设其满足正态分布函数的特性,在这种情况下,最大似然估计和最小二乘估计相同。最小二乘法以估计值与观测值的差的平方和作为损失函数,极大似然法则是以最大化目标值的似然概率函数为目标函数,从概率统计的角度处理线性回归并在似然概率函数为高斯函数的假设下同最小二乘建立了的联系。