Flume 使用exec及avro方式实现数据收集
导读:
本篇博客笔者主要介绍如何使用exec实现数据收集到HDFS、使用avro方式实现数据收集及整合exec和avro实现数据收集。
Flume 官方文档:http://flume.apache.org/FlumeUserGuide.html
1.使用exec实现数据收集到HDFS
需求:监控一个文件,将文件中新增的内容收集到HDFS
Agent选型:exec source + memory channel + hdfs sink
编写flume-exec-hdfs.conf文件,内容如下
# Name the components on this agent
exec-hdfs-agent.sources = exec-source
exec-hdfs-agent.sinks = hdfs-sink
exec-hdfs-agent.channels = memory-channel
# Describe/configure the source
exec-hdfs-agent.sources.exec-source.type = exec
exec-hdfs-agent.sources.exec-source.command = tail -F ~/data/data.log
exec-hdfs-agent.sources.exec-source.shell = /bin/bash -c
# Describe the sink
exec-hdfs-agent.sinks.hdfs-sink.type = hdfs
exec-hdfs-agent.sinks.hdfs-sink.path = hdfs://Master:9000/data/flume/tail
exec-hdfs-agent.sinks.hdfs-sink.hdfs.fileType=DataStream
exec-hdfs-agent.sinks.hdfs-sink.hdfs.writeFormat=Text
exec-hdfs-agent.sinks.hdfs-sink.hdfs.batchSize=10
# Use a channel which buffers events in memory
exec-hdfs-agent.channels.memory-channel.type = memory
# Bind the source and sink to the channel
exec-hdfs-agent.sources.exec-source.channels = memory-channel
exec-hdfs-agent.sinks.hdfs-sink.channel = memory-channel创建文件及目录
$ mkdir -p ~/data/data.log启动hdfs
[hadoop@Master ~]$ start-dfs.sh
[hadoop@Master ~]$ jps
3728 NameNode
3920 SecondaryNameNode
4035 Jps在hdfs中创建目录,用于存储flume日志数据
$ hadoop fs -mkdir -p /data/flume/tail目前data.log文件及hdfs中的/data/flume/tail目录下是没有任何数据和文件的
启动Agent
flume-ng agent \
--name exec-hdfs-agent \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/config/flume-exec-hdfs.conf \
-Dflume.root.logger=INFO,console向data.log中写入数据
[hadoop@Master data]$ echo aaa >> data.log
[hadoop@Master data]$ echo bbb >> data.log
[hadoop@Master data]$ echo ccc >> data.log
[hadoop@Master data]$ echo eee >> data.log
[hadoop@Master data]$ echo fff >> data.log
[hadoop@Master data]$ cat data.log
aaa
bbb
ccc
eee
fff查看hdfs中/data/flume/tail中是否有日志文件产生(会生成一个名为FlumeData.1508875804298的文件,该文件在正在使用的时候是一个以tmp结尾的文件,默认文件名的前缀为FlumeData)
[hadoop@Master ~]$ hadoop fs -ls /data/flume/tail
Found 1 items
-rw-r--r-- 1 hadoop supergroup 20 2017-9-25 04:10 /data/flume/tail/FlumeData.1508875804298FlumeData.1508875804298文件内容
[hadoop@Master ~]$ hadoop fs -text /data/flume/tail/FlumeData.1508875804298
aaa
bbb
ccc
eee
fff现在我们已经完成了监控一个文件,将文件中新增的内容收集到HDFS的需求,但是存在一个问题,就是小文件过多,namenode是按照块来存储,每一个文件就是一个block,每个block在namenode中都会存储它的元数据信息,导致namenode的压力较大。那么如果解决呐?
官网中hdfs-sink提供了三个参数,如下
![]()
hdfs.rollInterval:以指定的时间作为提交的标准,0表示不以时间作为提交的标准
hdfs.rollSize:block数量,笔者使用的hadoop版本是2.x,block的大小为128M,在这写的是134217728
hdfs.rollCount:文件内容的行数,以行数为基准作为提交,在这写的是1000000
注意:如果这三个参数都配置了,那么只要有一个达到就会提交
在flume-exec-hdfs.conf文件中添加如下三项配置,重新启动Agent
exec-hdfs-agent.sinks.hdfs-sink.hdfs.rollInterval = 0
exec-hdfs-agent.sinks.hdfs-sink.hdfs.rollSize = 134217728
exec-hdfs-agent.sinks.hdfs-sink.hdfs.rollCount = 1000000测试:将test.log文件中的内容写入到data.log中3次(test.log文件内容的行数为30多万)
[hadoop@Master data]$ wc -l test.log
338030 test.log
[hadoop@Master data]$ cat test.log >> data.log
[hadoop@Master data]$ cat test.log >> data.log
[hadoop@Master data]$ cat test.log >> data.log
[hadoop@Master data]$ wc -l data.log
1014095 data.log查看日志是否收集到了hdfs(满足100万行且文件大小超过128M时写入到一个block文件)
[hadoop@Master config]$ hadoop fs -ls /data/flume/tail
Found 3 items
-rw-r--r-- 1 hadoop supergroup 20 2017-9-25 07:10 /data/flume/tail/FlumeData.1508875804298
-rw-r--r-- 1 hadoop supergroup 134246595 2017-9-25 07:49 /data/flume/tail/FlumeData.1508877550270
-rw-r--r-- 1 hadoop supergroup 3808 2017-9-25 07:49 /data/flume/tail/FlumeData.1508877550271.tmp2.使用avro方式实现数据收集
需求:使用avro-client方式实现一台机器到另一台的avro文件传输
Agent选型:avro client => avro-source
问题:avro-client仅限于一次将文件发送,而不能实时进行传递新增的内容
avro 介绍
avro 是序列化的一种,实现了RPC(Remote Procedure Call),RPC是一种远程调用协议,我们先通过一张图来看下RPC的调用过程

说明:
根据用户id来获取用户,首先在客户端发送请求,然后将参数序列化,通过网络传输到服务端,服务端进行反序列化,调用服务返回结果并将结果序列化后传输到客户端,客户端再反序列化后获得结果。
实现一台机器到另一台的avro文件传输,需要使用avro-client命令,flume-ng help 查看该命令
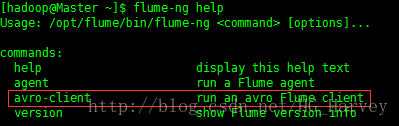
我们还是通过一张图来看下avro数据传输的流程图
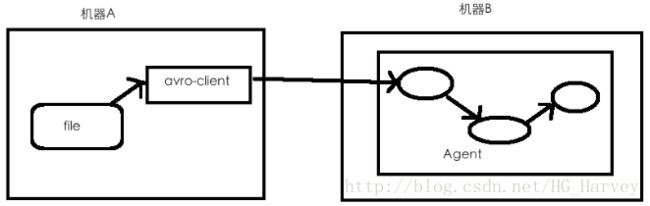
说明:机器A通过avro-client将文件传输到机器B,机器B中的Agent的组件Source收集数据,Channel缓冲数据,Sink最终将数据写入到机器B
需求实现
编写flume-avroclient.conf(机器B)
# Name the components on this agent
avroclient-agent.sources = avro-source
avroclient-agent.sinks = logger-sink
avroclient-agent.channels = memory-channel
# Describe/configure the source
avroclient-agent.sources.avro-source.type = avro
avroclient-agent.sources.avro-source.bind = Master
avroclient-agent.sources.avro-source.port = 44444
# Describe the sink
avroclient-agent.sinks.logger-sink.type = logger
# Use a channel which buffers events in memory
avroclient-agent.channels.memory-channel.type = memory
# Bind the source and sink to the channel
avroclient-agent.sources.avro-source.channels = memory-channel
avroclient-agent.sinks.logger-sink.channel = memory-channel启动Agent(机器B)
flume-ng agent \
--name avroclient-agent \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/config/flume-avroclient.conf \
-Dflume.root.logger=INFO,console在机器A中创建一个文件avro-access.log,添加几行内容
[hadoop@Master data]$ touch avro-access.log
[hadoop@Master data]$ echo hello >> avro-access.log
[hadoop@Master data]$ echo world >> avro-access.log
[hadoop@Master data]$ echo hello flume >> avro-access.log
[hadoop@Master data]$ cat avro-access.log
hello
world
hello flume使用avro-client命令发送文件到机器B,如果不知道avro-client如何使用,使用如下命令查看命令帮助
[hadoop@Master ~]$ flume-ng avro-client --help
usage: flume-ng avro-client [--dirname ] [-F ] [-H ] [-h]
[-P ] [-p ] [-R ]
--dirname directory to stream to avro source
-F,--filename file to stream to avro source
-H,--host hostname of the avro source
-h,--help display help text
-P,--rpcProps RPC client properties file with server connection
params
-p,--port port of the avro source
-R,--headerFile file containing headers as key/value pairs on
each new line
The --dirname option assumes that a spooling directory exists where
immutable log files are dropped. 机器A中输入如下命令,发送文件avro-access.log到机器B
flume-ng avro-client \
-H Master -p 44444 \
--conf $FLUME_HOME/conf \
-F ~/data/avro-access.log机器B的控制台打印的信息中可以看到我们在机器A文件avro-access.log中的内容
Event: { headers:{} body: 68 65 6C 6C 6F hello }
Event: { headers:{} body: 77 6F 72 6C 64 world }
Event: { headers:{} body: 68 65 6C 6C 6F 20 66 6C 75 6D 65 hello flume }3.整合exec和avro实现数据收集
需求说明
需求:将A服务器上的日志实时传输到B服务器
Agent 选型:
A 机器:exec source => mc channel => avro sink
B 机器:avro source => mc channel => logger sink
针对这个需求,我们需要使用两个Apent,也就是Agent的串联使用,下面是官网中给出的一个Agent串联使用的一个图

配置机器A和机器B的Agent(参照上图)
注意:机器A和机器B之间如果要进行数据交互,那么必须满足监听者和发送者的hostname+port对应上
机器A(Master) Agent编写
# Name the components on this agent
flume-avro-sink-agent.sources = exec-source
flume-avro-sink-agent.sinks = avro-sink
flume-avro-sink-agent.channels = memory-channel
# Describe/configure the source
flume-avro-sink-agent.sources.exec-source.type = exec
flume-avro-sink-agent.sources.exec-source.command = tail -F ~/data/data.log
flume-avro-sink-agent.sources.exec-source.shell = /bin/bash -c
# Describe the sink
flume-avro-sink-agent.sinks.avro-sink.type = avro
flume-avro-sink-agent.sinks.avro-sink.hostname = dn1
flume-avro-sink-agent.sinks.avro-sink.port = 44444
# Use a channel which buffers events in memory
flume-avro-sink-agent.channels.memory-channel.type = memory
# Bind the source and sink to the channel
flume-avro-sink-agent.sources.exec-source.channels = memory-channel
flume-avro-sink-agent.sinks.avro-sink.channel = memory-channel机器B(dn1) Agent编写
# Name the components on this agent
flume-avro-source-agent.sources = avro-source
flume-avro-source-agent.sinks = logger-sink
flume-avro-source-agent.channels = memory-channel
# Describe/configure the source
flume-avro-source-agent.sources.avro-source.type = avro
flume-avro-source-agent.sources.avro-source.bind = dn1
flume-avro-source-agent.sources.avro-source.port = 44444
# Describe the sink
flume-avro-source-agent.sinks.logger-sink.type = logger
# Use a channel which buffers events in memory
flume-avro-source-agent.channels.memory-channel.type = memory
# Bind the source and sink to the channel
flume-avro-source-agent.sources.avro-source.channels = memory-channel
flume-avro-source-agent.sinks.logger-sink.channel = memory-channel启动Agent
先启动B机器的Agent
flume-ng agent \
--name flume-avro-source-agent \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/config/flume-avro-source-agent.conf \
-Dflume.root.logger=INFO,console再启动A机器的Agent
flume-ng agent \
--name flume-avro-sink-agent \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/config/flume-avro-sink-agent.conf \
-Dflume.root.logger=INFO,console笔者在启动机器A上的Agent时遇到一个问题,如下(卡在这个地方不动了)
异常信息:
Post-validation flume configuration contains configuration for agents: [flume-avro-agent]
No configuration found for this host:flume-avro-sink-agent
原因:Agent的名字写错误
解决:flume-ng命令中的参数–name所指定的Agent名称要与配置文件中的Agent名称一致
测试
清空文件内容,向data.log文件中写入数据,观察B机器控制台打印的日志信息(也可以将这些信息收集到HDFS)
[hadoop@Master data]$ echo "" > data.log
[hadoop@Master data]$ echo hello flume >> data.log
[hadoop@Master data]$ echo hello spark >> data.log在机器B的Agent控制台中可以看到如下信息
Event: { headers:{} body: 68 65 6C 6C 6F 20 66 6C 75 6D 65 hello flume }
Event: { headers:{} body: 68 65 6C 6C 6F 20 73 70 61 72 6B hello spark }