【Mysql进阶】这就是索引优化!
前言:
一个优秀开发的必备技能:性能优化,包括:JVM调优、缓存、Sql性能优化等。本文主要讲基于Mysql的索引优化。
首先我们需要了解执行一条查询SQL时Mysql的处理过程:

其次我们需要知道,我们写的SQL在Mysql的执行顺序是怎么样的?sql的执行顺序对sql的性能优化很有帮助,很重要。在建立复合索引的时候需要考虑到这点。

例:
在tb_dept中建立一个复合索引 idx_parent_id_code:
然后看下两个sql 解释的结果:
1)在当前索引下,哪一个sql索引利用率高?
借助于上文中查询SQL的执行顺序,是先执行 WHERE再执行 GROUP BY 的,即:
第一个sql执行的顺序是先执行了 where后的 school_id 然后执行了 group by 后的 grade_id,顺序是和索引的顺序是一致的,type等级为ref,扫描行数rows为 4;
而第二个sql是先执行了 where后的 grade_id 然后执行了 group by 后的 school_id,顺序是和索引的顺序是不一致的,type等级为index,扫描行数rows为 19;
从解释结果看,第一条的sql索引利用率高于第二条的。(后文后讲到:索引type从优到差:System-->const-->eq_ref-->ref-->ref_or_null-->index_merge-->unique_subquery-->index_subquery-->range-->index-->all.)
或者从扫描的行数rows对比数据源也可直观的看出,两个语句的性能:
2)怎么优化?
如果业务中用到第二个sql,那么就需要调整索引的顺序和sql执行顺序一致。
或者两个sql都用到了,那么就再建一个复合索引 (idx_code_parent_id)
然后再看下第二条的执行计划:



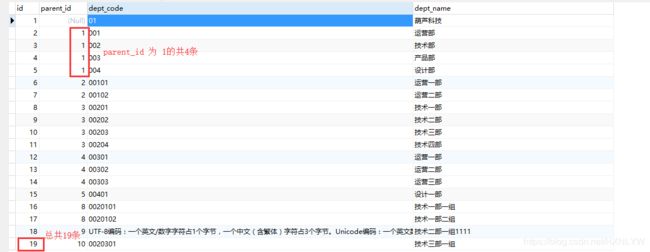


执行计划分析(下面就是本文的重点内容了):
通过explain可以知道mysql是如何处理语句的,并分析出查询或是表结构的性能瓶颈,其实就是在干查询优化器的事,通过expalin可以得到:
1. 表的读取顺序
2.表的读取操作的操作类型
3.哪些索引可以使用
4. 哪些索引被实际使用
5.表之间的引用
6.每张表有多少行被优化器查询
从上文的例子中我们可以看到执行explain时,结果会有一个表格,这个表格就是分析结果,下面我们来一个一个说明下这个表的表头:
![]()
Id: MySQL QueryOptimizer 选定的执行计划中查询的序列号。表示查询中执行select 子句或操作表的顺序,id 值越大优先级越高,越先被执行。id 相同,执行顺序由上至下。
Select_type: 一共有9中类型,只介绍常用的4种:
SIMPLE: 简单的 select 查询,不使用 union 及子查询
PRIMARY: 最外层的 select 查询
UNION: UNION 中的第二个或随后的 select 查询,不 依赖于外部查询的结果集
DERIVED: 用于 from 子句里有子查询的情况。 MySQL 会 递归执行这些子查询, 把结果放在临时表里。
Table: 输出行所引用的表
Type: 从有到差的顺序如下:(红色标识的是常见的级别。)
system-->const-->eq_ref-->ref-->ref_or_null-->index_merge-->unique_subquery-->index_subquery-->range-->index-->all.
各自的含义如下:
system: 表仅有一行。这是 const 连接类型的一个特例。
const: const 用于用常数值比较 PRIMARY KEY 时。
eq_ref: 查询使用了索引为主键或唯一键的全部时使用。即:通过索引关键字可能查找到一个符合条件的行。
ref: 通过索引关键字可能查找到多个符合条件的行。
ref_or_null: 如同 ref, 但是 MySQL 必须在初次查找的结果里找出 null 条目,然后进行二次查找。
index_merge: 说明索引合并优化被使用了。
unique_subquery: 在某些 IN 查询中使用此种类型,而不是常规的 ref:valueIN (SELECT primary_key FROM single_table WHERE some_expr)
index_subquery: 在 某 些 IN 查 询 中 使 用 此 种 类 型 , 与unique_subquery 类似,但是查询的是非唯一 性索引
range: 检索给定范围的行。当使用 <>、>、>=、<、<=、BETWEEN 或者 IN 操作符时,会使用到range。
index: 全表扫描,只是扫描表的时候按照索引次序进行而不是行。主要优点就是避免了排序, 但是开销仍然非常大。
all: 最坏的情况,从头到尾全表扫描。
possible_keys : 哪些索引可能有助于查询。如果为空,说明没有可用的索引。
key: 实际从 possible_key 选择使用的索引,如果为 NULL,则没有使用索引。很少的情况 下,MYSQL 会选择优化不足的索引。这种情 况下,可以在 SELECT语句中使用 USE INDEX (indexname)来强制使用一个索引或者用IGNORE INDEX(indexname)来强制 MYSQL 忽略索引
key_len: 使用的索引的长度。在不损失精确性的情况 下,长度越短越好。
ref: 显示索引的哪一列被使用了
rows: 请求数据返回的大概行数
extra: 其他信息,出现Using filesort、Using temporary 意味着不能使用索引,效率会受到重大影响。应尽可能对此进行优化。
Using filesort: 没有办法利用现有索引进行排序,需要额外排序,建议:根据排序需要,创建相应合适的索引
Using temporary: 需要用临时表存储结果集,通常是因为group by的列列上没有索引。也有可能是因为同
时有group by和order by,但group by和order by的列又不一样Using index : 利用覆盖索引,无需回表即可取得结果数据(即数据直接从索引文件中读取),这种结果是好的。
其中重要的几个就是 key、type 、rows、extra,其中key为null、all 、index时,需要调整、优化索引。一般需要达到 ref、eq_ref 级别,范围查找需要达到 range,extra有Using filesort、Using temporary 的一定需要优化,根据rows可以直观看出优化结果。
优化手段:
① SQL优化
- 避免 SELECT *,只查询需要的字段。
- 小表驱动大表,即小的数据集驱动大的数据集:
当B表的数据集比A表小时,用in优化 exist两表执行顺序是先查B表再查A表查询语句:SELECT * FROM tb_dept WHERE id in (SELECT id FROM tb_dept) ;
当A表的数据集比B表小时,用exist优化in ,两表执行顺序是先查A表,再查B表,查询语句:SELECT * FROM A WHERE EXISTS (SELECT id FROM B WHERE A.id = B.ID) ;- 尽量使用连接代替子查询,因为使用 join 时,MySQL 不会在内存中创建临时表。
② 优化索引的使用
- 尽量使用主键查询,而非其他索引,因为主键查询不会触发回表查询。
- 不做列运算,把计算都放入各个业务系统实现
- 查询语句尽可能简单,大语句拆小语句,减少锁时间
- or 查询改写成 union 查询
- 不用函数和触发器
- 避免 %xx 查询,可以使用:select * from t where reverse(f) like reverse('%abc');
- 少用 join 查询
- 使用同类型比较,比如 '123' 和 '123'、123 和 123
- 尽量避免在 where 子句中使用 != 或者 <> 操作符,查询引用会放弃索引而进行全表扫描
- 列表数据使用分页查询,每页数据量不要太大
- 避免在索引列上使用 is null 和 is not null
③ 表结构设计优化
- 使用可以存下数据最小的数据类型。
- 尽量使用 tinyint、smallint、mediumint 作为整数类型而非 int。
- 尽可能使用 not null 定义字段,因为 null 占用 4 字节空间。数字可以默认 0 ,字符串默认 “”
- 尽量少用 text 类型,非用不可时最好独立出一张表。
- 尽量使用 timestamp,而非 datetime。
- 单表不要有太多字段,建议在 20 个字段以内。
Mysql常用数据类型存储大小及范围:https://blog.csdn.net/HXNLYW/article/details/100104768
3.如果以上优化还是有问题,可以使用show profiles 分析sql 性能
show profiles
show profile for query [queryId]
具体请查看:https://blog.csdn.net/aeolus_pu/article/details/7818498
结尾:
本文是最近学习Mysql索引优化的一些总结和记录,如有不对的地方,欢迎评论吐槽。
附:
索引相关知识:
———— 查看表索引:
show index from 【table】———— 直接创建索引
CREATE INDEX indexName ON table(column(length))———— 修改表结构的方式添加索引
ALTER tableADD INDEX indexName ON (column(length))
---主键索引
ALTER TABLE `table_name` ADD PRIMARY KEY ( `column` )
---唯一索引
ALTER TABLE `table_name` ADD UNIQUE (`column` )
---普通索引
ALTER TABLE `table_name` ADD INDEX index_name ( `column`(length) )
---复合索引
ALTER TABLE `table_name` ADD INDEX index_name ( `column1`, `column2`, `column3` )length的确定:
如果索引列长度过长,这种列索引时将会产生很大的索引文件,不便于操作,可以使用前缀索引方式进行索引,前缀索引应该控制在一个合适的点,控制在0.31黄金值即可(大于这个值就可以创建)。
SELECT COUNT(DISTINCT(LEFT(`title`,10)))/COUNT(*) FROM Arctic; -- 这个值大于0.31就可以创建前缀索引,Distinct去重复———— 删除索引:
1)ALTER TABLE table_name DROP INDEX index_name
2)DROP INDEX index_name ON table_name;
MyISAM 和 InnoBD区别:
| |
MyISAM |
InnoDB |
| 主键 | 允许没有任何索引和主键的表存在, myisam的索引都是保存行的地址。 |
如果没有设定主键或者非空唯一索引,就会自动生成一个6字节的主键(用户不可见) innodb的数据是主索引的一部分,其他索引保存的是主索引的值。 |
| 事务处理上方面: |
MyISAM类型的表强调的是性能,其执行数度比InnoDB类型更快,但是不提供事务支持、不支持外键 | InnoDB提供事务支持事务,外部键(foreign key)等高级数据库功能 |
| DML操作 |
如果执行大量的SELECT,MyISAM是更好的选择 |
1.如果你的数据执行大量的INSERT或UPDATE,出于性能方面的考虑,应该使用InnoDB表 2.DELETE FROM table时,InnoDB不会重新建立表,而是一行一行的删除。 |
| 自动增长 |
myisam引擎的自动增长列必须是索引,如果是组合索引,自动增长可以不是第一列,他可以根据前面几列进行排序后递增。 |
innodb引擎的自动增长必须是索引,如果是组合索引也必须是组合索引的第一列。 |
| count()函数 | myisam保存有表的总行数,如果select count(*) from table;会直接取出出该值 | innodb没有保存表的总行数,如果使用select count(*) from table;就会遍历整个表,消耗相当大,但是在加了wehre 条件后,myisam和innodb处理的方式都一样。 |
| 锁 |
表锁 |
提供行锁,另外,InnoDB表的行锁也不是绝对的,如果在执行一个SQL语句时MySQL不能确定要扫描的范围,InnoDB表同样会锁全表, 例如update table set num=1 where name like "%aaa%" |
mysql相关配置参数优化:
• sort-buffer-size/join-buffer-size / read-rnd-buffer-size,4~8MB为宜
• optimizer_switch=“index_condition_pushdown=on,mrr=on,mrr_cost
_based=off,batched_key_access=on”
• tmp-table-size = max-heap-table-size,100MB左右为宜
• log-queries-not-using-indexes & log_throttle_queries_not_using_indexes