Java 集合框架(5)---- Map 相关类解析(中)
本文标题大纲:
文章目录
- 前言
- HashMap
- TreeMap
- 指定 TreeMap 的元素排序方式
前言
还是先上那张图吧,我又偷懒了,还是只关注 Map 接口下的类就行了:

在上上篇文章中我们一起看了一下 Map 接口下一个抽象类 AbstractMap 和一个接口 SortedMap 的声明和相关方法。那么接下来我们就开始着手于 Map 接口下的一些具体类的分析。先从 HashMap 开始:
HashMap
HashMap 应该是 Java 集合框架中我们在开发中最常用的容器类之一了,它提供了保存多个键值对的能力,并对其保存的键值对提供获取和操作的相关 API,相信小伙伴们对这个类的用法已经很熟悉了,那么我们从源码入手,来一起看看 HashMap 是怎么实现的:
public class HashMap extends AbstractMap
implements Map, Cloneable, Serializable {
// ...
// 默认的初始化容量(16),HashMap 的容量必须是 2 的次幂
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
// HashMap 的最大容量
static final int MAXIMUM_CAPACITY = 1 << 30;
// 默认的负载因子(用于计算出下一次进行扩容时的容量)
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* 将链表树化的最小长度,当有多个 key 的 hashCode 相同时,
* 先采用链地址法处理冲突,即将多个相同的元素按先后顺序排成一条链表,
* 当这个链表的元素不小于当前字段的值时,为了保证效率,
* 将这一部分链表转换成平衡二叉树
*/
static final int TREEIFY_THRESHOLD = 8;
// 在调整 HashMap 容量时取消树化链表的长度阀值
static final int UNTREEIFY_THRESHOLD = 6;
// 树化一个链表时要求 HashMap 的最小容量
static final int MIN_TREEIFY_CAPACITY = 64;
在上面的代码中,有一个 DEFAULT_LOAD_FACTOR 常量,意为负载因子,这个值用于计算出下一次需要对 HashMap 进行扩容时 HashMap 中包含的最大元素(即键值对,下同)数,即可以理解为对 HashMap 对象进行下一次扩容的容量阀值,这个阀值也由一个名为 threshold 的成员变量保存。举个例子:
假当前设置的 HashMap 对象的容量为默认容量,即 16 ,那么当前的 threshold 值为 16 * 0.75 = 12,那么如果当前 HashMap 中装的元素个数到达了 12 个时,就要进行下一次扩容了。可能有小伙伴会问了,为什么要这么做呢?这样不是浪费内存吗?确实,这样做确实会浪费一部分内存,但是主要目的是为了减少元素冲突:当当前的 HashMap 容量越大的时候,给元素的 key 计算出来的 hashCode 的选择也就越多,这样就越不容易产生冲突。举个例子:如果当前 HashMap 还剩下 16 个空位置,我们要存 10 个元素,那么平均下来每个元素有 1.6 个位置,可能产生冲突,但如果当前 HashMap 只有 8 个位置,那么把 10 个元素存进去,必然产生冲突,这样的话就增加了插入和查询元素的时间复杂度。一个可能产生冲突,一个必然产生冲突,而 HashMap 的任务其实主要是致力于保证在尽可能低的时间复杂度(O(1))中插入和查询元素。所以从这个角度上来说牺牲一点内存是值得的。
需要注意的是,我们在创建 HashMap 对象的时候可以自己定义这个负载因子,但是我们很难去准确的找到一个最适用我们程序中的负载因子,如果太小,那么会浪费太多的内存空间,如果太大,又可能会在插入元素时产生较多冲突,提高了插入和查询操作的时间复杂度,因此除非你很有把握,否则的话我们可以直接用默认的值,无需特殊指定。
下面来看一下 HashMap 是用哪个类来表示每个元素(键值对)的:
// 描述 HashMap 元素的键值对
static class Node implements Map.Entry {
final int hash; // 元素的键的 hash 值
final K key; // 元素的键
V value; // 元素的值
Node next; // 下一个元素的引用(用于处理冲突)
Node(int hash, K key, V value, Node next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
// 获取当前元素 “键” 的 hashCode 值
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
// 判断对象 o 是否和当前对象在值上相等
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry e = (Map.Entry)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
我们在 Java 集合框架 (1)— 概述 中已经介绍过了 Map.Entry 接口,它是一个描述了 HashMap 中键值对元素信息并提供了一些方法来获取这些信息,在 HashMap 中通过一个名为 Node 的静态内部类来实现这个接口并实现接口中的方法。整个 HashMap 实际上是通过一个 Node 类型的数组来保存元素信息的,来看看相关的字段定义:
// 保存所有键值对元素信息的表,其长度必须为 2 的次幂
transient Node[] table;
// 当前 HashMap 对象包含的键值对元素集合
transient Set> entrySet;
// 当前 HashMap 对象中包含的元素(键值对)的数目
transient int size;
// 记录当前 HashMap 对象已经更改的次数(重新分配尺寸、添加、删除元素...)
transient int modCount;
// 下一次进行重新分配当前 HashMap 容量时 HashMap 中存在的最大元素数目 (capacity * loadFactor).
int threshold;
// 当前 HashMap 的负载因子
final float loadFactor;
相关字段看完了,也算是为了下面的内容打基础,下面就开始分析一下相关的方法,首先从构造方法开始:
// 构造一个带有 initialCapacity 初始容量和 loadFactor 负载因子的 HashMap 对象
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
// 指定的初始容量不能大于 HashMap 允许的最大容量
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
// 如果当前指定的负载因子小于 0 或者是一个非数字(0.0/0.0 的情况)
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
// 通过 tableSizeFor 方法得到下一次要进行扩容时 HashMap 对象包含的元素数目(这个是第一次的)
this.threshold = tableSizeFor(initialCapacity);
}
在这个方法里有两个方法可能有点不太熟悉,我们来看一下,首先是 Float.isNaN ,这个方法在 Float.java 中定义:
// 判断一个数字是否是非数字值(not a number),如果是,返回 true,否则返回 false
public static boolean isNaN(float v) {
return (v != v);
}
这是一个 Float 类中的静态方法,为了判断出一个值是否为 “非数字” 值,可能有小伙伴会问了,这句话怎么说的通呢?其实这里说的 “非数字” 值指的是类似于 0.0 / 0.0 得到的值。是的,在 Java 中,小数除以 0 不会抛出 ArithmeticException 异常,但是每次 0.0 / 0.0 得到的结果都是不同的值(对象),我们来做个小实验:
public static void main(String[] args) {
System.out.println(0.0/0.0 == 0.0/0.0);
}
看到这个程序,可能有些小伙伴第一反应是:这个输出肯定是 true ,那么我们来看看结果:

很遗憾,它输出的是 false,因为每次表达式 0.0/0.0 得到的值都不一样,回到我们的上面的代码,isNaN 方法直接返回的是 (v != v),我们也就可以理解这段代码的含义了,如果 v 不是某次 0.0/0.0 的结果,那么 (v != v) 的值肯定为 false (自己怎么会不等于自己呢?),否则,根据我们上面做的实验,它会返回 true,那么再回到上面的 HashMap 的构造方法中,我们已经知道第一个方法的作用,下面来看看下一个方法:TableSizeFor:
// 对当前 cap 指定的容量进行操作,返回第一个大于等于 cap 的 2 的次幂值
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
这个方法用到了位运算,| 为按位或,而 >>> 为无符号右移,和 >> (有符号右移)的区别在于无符号右移在左边填充的是 0,而有符号右移在左边填充的是符号位(正数为 0,负数为 1)。而所有位运算均是争对二进制而言,这个方法的作用是什么呢?我们用一个具体的数值带进去走一遍流程,假设当前 cap 为 6:
n = cap - 1 = 5
n 的二进制:000..00(29个0) 101,之后省略前导零
n |= n >>> 1 = (101) | (010) = 111
n |= n >>> 2 = (111) | (001) = 111
n |= n >>> 4 = (0) | (111) = 111
n |= n >>> 8 = (0) | (111) = 111
n |= n >>> 16 = (0) | (111) = 111
看到这可能有小伙伴已经反应过来了:这个其实就是把 n 的二进制数中最左边的那一位 1 之后的 0 全变为 1。接下来在 return 语句中如果 n 的值正常,那么返回 n + 1,这样经过进位将左边所有的 1 变为 0 ,并将最左边的 1 的前一位 0 变为 1,比如当前得到了 n 为 7(111),那么 n + 1 就为 8 (1000)得到的值就是 2 的次幂,那在开始为什么要将 n 赋值为 cap - 1 呢?其实是为了防止当前 cap 值本身就是 2 的次幂的情况会使得得到的值为 cap * 2。整个过程 n 向右移动的位数为(1+2+4+8+16 = 31,正好是 int 类型的位数(32)- 1)。这里说个题外话:如果操作数的类型是 long 呢?该如何改进?
小伙伴如果对这段代码还不是很清楚的话,我们来看一下这段代码在程序中的表现:
static final int tableSizeFor(int cap) {
int maxValue = Integer.MAX_VALUE - 8;
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= maxValue) ? maxValue : n + 1;
}
public static void main(String[] args) {
for (int i = 0; i < 33; i++) {
System.out.println("i: " + i + ", value: " + tableSizeFor(i));
}
}
我把这段代码复制到了程序中,并将 MAXIMUM_CAPACITY 值用 Integer.MAX_VALUE - 8 代替了,值本身不变,我们来看看结果:
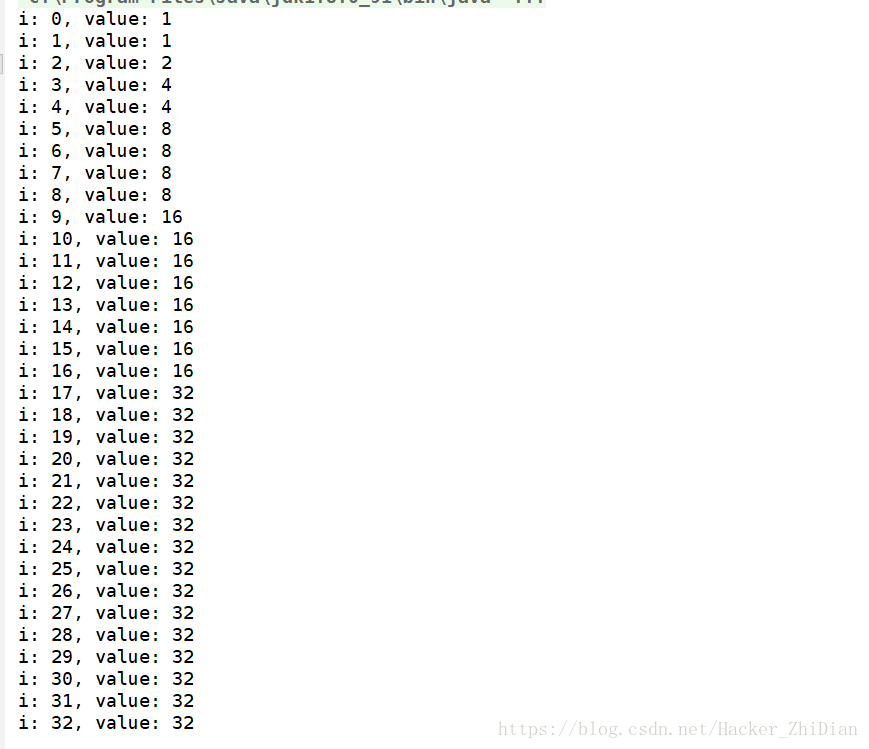
对比结果,这个结论也很容易理解。
好了,回到我们最初的构造方法,构造方法执行完这个方法所在的代码行就结束了,但是我们并没有看到其为 table 字段(储存键值对元素的数组)申请内存空间,我们看看别的构造方法:
// 创建一个具有指定的初始容量和默认负载因子(0.75)的 HashMap 对象
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
// 创建一个没有任何元素并带有默认容量(16)和默认负载因子(0.75)的 HashMap 对象
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
/**
* 创建一个具有默认负载因子的 HashMap 对象,并将 Map 类型的参数 m 中的元素存入这个对象中,
* 如果 m 为 null,抛出一个 NullpointException 异常
*/
public HashMap(Map m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}
前面两个构造方法也没看到其为 table 字段申请内存空间,但是第三个构造方法中我们看到了一个 putMapEntries 方法,那么我们跟进去看一下:
/**
* Implements Map.putAll and Map constructor
* @param m the map
* @param evict false when initially constructing this map, else
* true (relayed to method afterNodeInsertion).
*/
final void putMapEntries(Map m, boolean evict) {
int s = m.size();
if (s > 0) {
if (table == null) { // pre-size
float ft = ((float)s / loadFactor) + 1.0F;
int t = ((ft < (float)MAXIMUM_CAPACITY) ?
(int)ft : MAXIMUM_CAPACITY);
if (t > threshold)
threshold = tableSizeFor(t);
}
else if (s > threshold)
resize();
for (Map.Entry e : m.entrySet()) {
K key = e.getKey();
V value = e.getValue();
putVal(hash(key), key, value, false, evict);
}
}
}
在这里,我们看到了两个新的方法:resize 和 putVal,而且不管如何这个方法最后都会调用 putVal 方法,我们很容易猜到这个方法是存放键值对进入当前 HashMap 的方法,但是我们平时都是用 put 方法来存放键值对的,我们看看 put 方法的源码:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
原来 put 方法就是直接调用了 putVal 方法,那么我们来看看这个 putVal 方法:
/**
* Implements Map.put and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node[] tab; Node p; int n, i;
// 如果当前的 table 为 null,证明还未给 table 申请内存空间,
// 那么通过 resize 方法申请并调整 table 容量
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 如果当前存入的键值对中 (“键” 的 hash 值 % table.length 得到的结果),
// 为什么可以用 & 运算符来模拟 % 操作?
// 上文已经说过,HashMap 的容量必须是 2 的次幂,所以其容量 n 转换成二进制中必然只有一位是 1,
// 那么 n - 1,就是将最左边的那一位 1 变为 0,并且将其右边的 0 变成 1 ,
// 再将得到的值和 hash 通过 & 按位相与,这样的话得到的结果必然不会大于 n-1,
// 即通过位运算达到了 % 操作的目的,还减小了 CPU 资源的消耗(位操作速度一般的操作符快多了)
// 如果得到的结果作为下标在 table 数组所代表的数组元素为 null,
// 即 table[hash(key) % table.length] = null
// 证明这个下标可用(不会产生冲突),那么直接赋值
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
// 产生冲突
else {
Node e; K k;
// 如果插入的键值对的 “键” 和冲突的键值对的 “键” 等价,那么先记录产生冲突的元素,到后面更新值
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 如果产生已存在的键值对元素为 TreeNode 类型,证明当前链表已经被树化(变成一颗红黑树),
// 那么把节点(键值对元素)插入树中,(涉及到红黑树的维护)
else if (p instanceof TreeNode)
e = ((TreeNode)p).putTreeVal(this, tab, hash, key, value);
else {
// 遍历整个冲突链表
for (int binCount = 0; ; ++binCount) {
// 如果当前已经到达链表尾部,那么把元素节点插入到链表尾部
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// 如果当前链表长度不小于 TREEIFY_THRESHOLD(8),那么树化链表(变成一颗红黑树)
// 注意 bitCount 从 0 开始
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
// 同样的,如果插入的键值对元素的 “键” 和某个已经存在的键值对的 “键” 等价,
// 那么直接跳出循环,之后会更新这个等价的键值对的值
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
// 如果 e 不为 null,证明有某个键值对的 “键” 和插入的键值对的 “键” 是等价的,
// 更新已经存在的那个键值对的值
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
// 回调方法,供子类实现
afterNodeAccess(e);
// 返回被替换得 “值”
return oldValue;
}
}
++modCount;
// 如果插入键值对后元素数目大于重新分配 HashMap 容量的阀值,那么再次分配 HashMap 容量
if (++size > threshold)
resize();
// 回调方法,供子类实现
afterNodeInsertion(evict);
// 如果没有更新任何键值对的值,证明成功插入了一个新的键值对,此时返回 null
return null;
}
这个方法实际上为在 HashMap 中插入新元素的核心方法,在上面的代码注释中涉及到一些新的概念,首先是冲突,这里的冲突是指两个键值对元素的 “键” 的 hashCode 相同,这种情况下有两种情况:
1、要插入的键值对的 “键” 和冲突的键值对的 “键” 等价(两个引用指向一个对象或者两个引用指向的对象的 equals 方法返回 true)。此时,记录这个键值对,到后面更新一下它的值即可
2、要插入的键值对的 “键” 和冲突的键值对的 “键” 不等价(两个引用指向的对象的 equals 方法返回 false)。这种情况下就需要进行特殊处理(链化或者树化节点),来看张图:
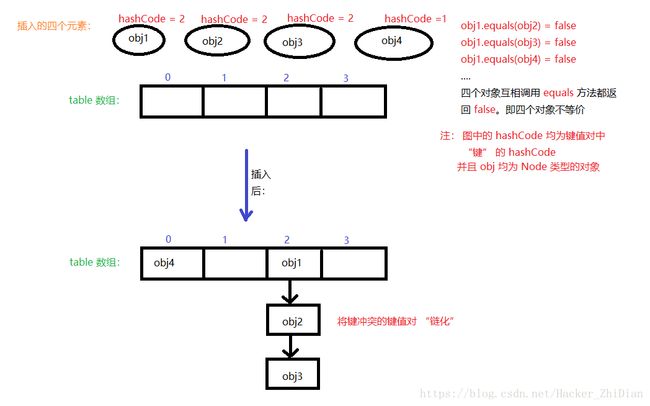
这是处理冲突的第一种方式,将键的 hashCode 值冲突但键本身又不等价的键值对按插入先后顺序链化,那么还有 “树化” 呢?树化其实是将链化的链表转成一颗红黑树(一种平衡二叉树的实现,节点的左子树节点值都小于该节点值,右子树节点值都大于该节点值,并且每个节点的左右子树高度差不超过 1 ),可能有些小伙伴对红黑树不太熟悉,但是红黑树的相关操作(主要是节点的旋转比较麻烦)并不是一两句话能够说清楚的,我们这里就不深入讨论了,在这里我们知道红黑树最主要的用途就可以了:在红黑树中插入和查询操作的时间复杂度都是 O(logn),即为树的高度,这里 n 为树的节点总数,我们知道在一个链表中查找某个节点的时间复杂度为 O(n),这样的话如果节点数很多的话就会造成插入和查询节点过于耗时的情况,而 HashMap 本身就是用来提供对象和对象之间的映射关系的,即减小通过对象来查询对象的时间复杂度,当我们上面链化的节点过多的时候,链表太长就会影响 HashMap 的插入和查询操作的时间复杂度,因此在上面的代码中,如果冲突的元素组成的链表长度不小于 TREEIFY_THRESHOLD(8) 时,就需要将链表树化,以减小相关操作的时间复杂度(O(n) -> O(logn))。还是简单用一张图来看一下树化的过程:
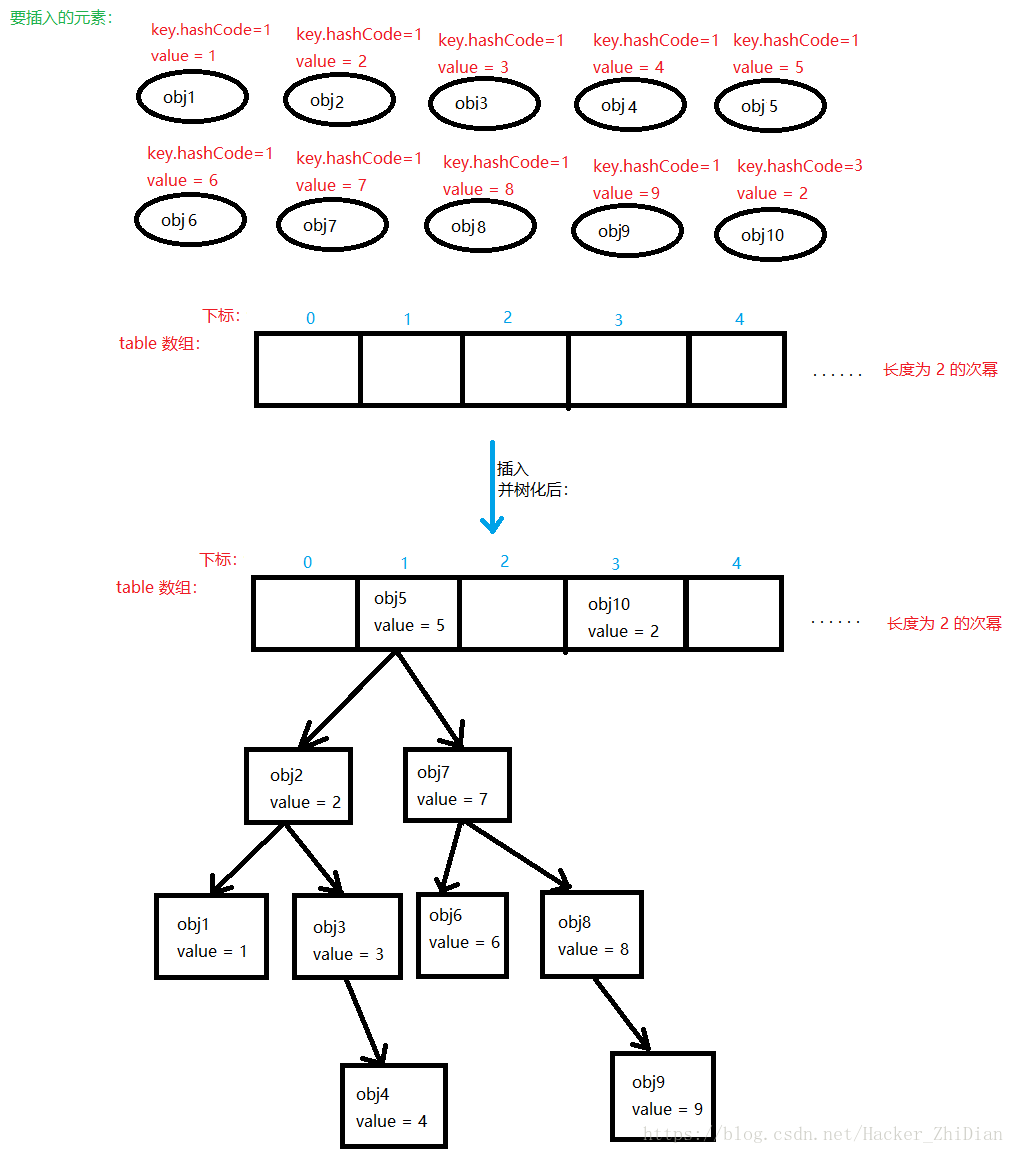
这个过程其实就相当于构建了一颗红黑树,关于红黑树,有兴趣的小伙伴可以查看相关资料。
好了,我们把向 HashMap 中插入元素的流程看完了,还剩下一个 resize 方法,我们从方法名就可以知道这个方法是为了给 HashMap 扩容的方法,我们来看看这个方法的实现:
/**
* Initializes or doubles table size. If null, allocates in
* accord with initial capacity target held in field threshold.
* Otherwise, because we are using power-of-two expansion, the
* elements from each bin must either stay at same index, or move
* with a power of two offset in the new table.
*
* @return the table
*/
final Node[] resize() {
Node[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
// 如果当前 HashMap 的元素数目已经达到最大,那么直接返回
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 如果当前 HashMap 容量不小于默认容量(16)并且其 * 2 小于允许的最大容量,
// 那么将 HashMap 容量变成原来的两倍,并且容量分配阀值 * 2
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
// 如果当前 HashMap 的容量为 0,并且容量分配阀值大于 0,
// 证明是在构造方法中指定了 HashMap 的初始容量,直接分配
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
// 否则的哈采用默认容量,并更新容量分配阀值
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// 如果新的容量分配阀值为 0,证明在构造方法啊中指定了 HashMap 的初始容量,
// 负载因子有可能被指定,为了正确性,直接使用 loadFactor 字段计算出新的容量分配阀值
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
// 为 table 申请内存空间
Node[] newTab = (Node[])new Node[newCap];
table = newTab;
if (oldTab != null) {
// 将旧数组中的元素复制到新数组中
for (int j = 0; j < oldCap; ++j) {
Node e;
if ((e = oldTab[j]) != null) {
// 原数组元素引用赋值为 null,防止内存泄露
oldTab[j] = null;
// 如果这个元素没有 next 节点,证明没有元素和它产生冲突。直接赋值
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
// 有冲突,处理树节点
else if (e instanceof TreeNode)
((TreeNode)e).split(this, newTab, j, oldCap);
// 有冲突,处理链表节点
else { // preserve order
Node loHead = null, loTail = null;
Node hiHead = null, hiTail = null;
Node next;
do {
next = e.next;
// 如果元素的键的 hashCode 和 旧数组容量按位与等于 0,
// 证明其 hashCode 小于 oldCap(oldCap)一定是 2 的次幂,
// 把它添加到 “低” 链表部分
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
// 否则添加到 “高” 链表部分
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// 如果 “低” 链表尾节点不为 null,将其 next 赋值为 null,
// 并将其头结点赋值给新数组对应下标的元素
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
// 如果 “高” 链表尾节点不为 null,将其 next 赋值为 null,
// 并将其头结点赋值给新数组对应下标的元素
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
// 返回新数组
return newTab;
}
好了,到这里我们已经把 HashMap 中插入元素的流程分析完了,下面来看看取键值对 “值” 的方法(即 get 方法):
public V get(Object key) {
Node e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
好吧,get 方法通过调用 getNode 方法来得到对应的键值对元素,如果为 null,那么返回 null,否则返回对应的值,我们来看看 getNode 方法:
/**
* Implements Map.get and related methods
*
* @param hash hash for key
* @param key the key
* @return the node, or null if none
*/
final Node getNode(int hash, Object key) {
Node[] tab; Node first, e; int n; K k;
// 如果当前 HashMap 的 table 数组不为 null 并且处理 hash 值得到的结果(hash %= n)作为下标,
// 所指向的数组元素不为 null,那么证明这个 hash 值存在对应的键值对
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// 如果第一个键值对的键就和要查询的键等价,那么直接返回键值对元素
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
// 如果第一个键值对元素的 next 不为 null,证明这个键值对和别的键值对产生冲突
if ((e = first.next) != null) {
// 如果是树节点,那么从红黑树中获取键值对元素
if (first instanceof TreeNode)
return ((TreeNode)first).getTreeNode(hash, key);
do {
// 如果是链表并且键值对的键和当前要查询的键等价,那么返回这个键值对
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
// 没有查询到证明当前要查询的 key 不和任何一个键值对的键等价,则返回 null
return null;
}
OK,get 方法的流程我们也知道了,下面看看移除一个键值对元素的方法 remove:
public V remove(Object key) {
Node e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
同样的,调用了 removeNode 方法来进行移除,我们赶紧看看这个方法:
/**
* Implements Map.remove and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to match if matchValue, else ignored
* @param matchValue if true only remove if value is equal
* @param movable if false do not move other nodes while removing
* @return the node, or null if none
*/
final Node removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node[] tab; Node p; int n, index;
// 同样的,先确保 table 不为 null,并且处理后的 hash 作为下标所指向的元素不为 null
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node node = null, e; K k; V v;
// 这里的逻辑和上面 getNode 方法的逻辑很相似,先得取到要移除的键值对元素
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
else if ((e = p.next) != null) {
// 从红黑树中取键值对元素
if (p instanceof TreeNode)
node = ((TreeNode)p).getTreeNode(hash, key);
else {
// 从链表中取键值对元素
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
// 如果上面得到的要移除的键值对元素不为 null,那么进行移除
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
// 如果是树节点,那么从红黑树中移除元素(涉及到红黑树的维护)
if (node instanceof TreeNode)
((TreeNode)node).removeTreeNode(this, tab, movable);
// 移除的是链表中的头节点元素,直接将数组下标对应的元素引用赋值为头结点的下一个节点元素
else if (node == p)
tab[index] = node.next;
// 移除的不是链表头结点元素,
// 将 node 的上一个节点元素(即为 p)的 next 字段赋值为 node.next
else
p.next = node.next;
++modCount;
--size;
// 供子类实现的回调方法
afterNodeRemoval(node);
// 返回被移除的元素
return node;
}
}
// 没有找到要移除的键值对元素,返回 null
return null;
}
看完了移除键值对元素的操作,最后来看一下遍历元素的方法:
// 1、通过 entrySet() 方法得到 HashMap 的键值对集合,再通过集合提供的迭代器来遍历元素,
// 这个遍历过程其实就是顺序遍历 HashMap 中的 table 数组
public Set> entrySet() {
Set> es;
return (es = entrySet) == null ? (entrySet = new EntrySet()) : es;
}
// 2、通过得到 HashMap 的所有键值对中 “键” 的集合,然后通过 get() 方法得到值来遍历元素
public Set keySet() {
Set ks;
return (ks = keySet) == null ? (keySet = new KeySet()) : ks;
}
// 3、通过 forEach 方法来实现 HashMap 中的元素遍历(JDK 1.8 以上支持)
@Override
public void forEach(BiConsumer action) {
Node[] tab;
if (action == null)
throw new NullPointerException();
if (size > 0 && (tab = table) != null) {
int mc = modCount;
for (int i = 0; i < tab.length; ++i) {
for (Node e = tab[i]; e != null; e = e.next)
action.accept(e.key, e.value);
}
if (modCount != mc)
throw new ConcurrentModificationException();
}
}
HashMap 虽然是通过提供集合(entrySet)的形式来对外提供遍历元素的接口,但实际上这个集合(entrySet)遍历元素的顺序就是直接顺序遍历其 HashMap 对象的 table 数组,关于这点,可以参考以下源码:
final class EntrySet extends AbstractSet> {
public final int size() { return size; }
public final void clear() { HashMap.this.clear(); }
public final Iterator> iterator() {
return new EntryIterator();
}
// ...
}
这个 EntrySet 类是 HashMap 的一个内部类,而 HashMap 的 entrySet 方法中返回的也是一个 EntrySet 对象,也就是说我们通过 entrySet 方法得到的其实是一个 EntrySet 对象,我们对 Set 进行遍历时是通过其提供的迭代器进行的,所以我们重点关注其 iterator 方法,发现其返回的是一个 EntryIterator 对象,我们看看这个类:
final class EntryIterator extends HashIterator
implements Iterator> {
public final Map.Entry next() { return nextNode(); }
}
同样是一个 HashMap 的内部类,继承自 HashIterator 类,其 next 方法直接返回了其父类对象 HashIterator 的 nextNode 方法的调用结果,我们继续跟进这个方法:
final Node nextNode() {
Node[] t;
// 当前要返回的元素为上一次调用 nextNode 方法后的 next 引用指向的元素对象
Node e = next;
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
// 如果当前要返回的元素为 null,抛出一个异常
if (e == null)
throw new NoSuchElementException();
// 如果当前元素的下一个元素为 null,并且当前 HashMap 对象的 table 数组不为 null,
// 则进入循环,这里其实是为了下一个元素做准备,next 引用指向下一个要返回的元素对象
if ((next = (current = e).next) == null && (t = table) != null) {
// 这里循环为了排除 table 数组的 null 元素,index 下标一直++,
// 直到遇到一个不为 null 的元素时结束循环,
do {} while (index < t.length && (next = t[index++]) == null);
}
return e;
}
这个方法在 HashIterator 类中声明,方法的作用在注释中已经写的很清楚了,我们再来看看 HashIterator 类的其他信息:
abstract class HashIterator {
Node next; // next entry to return
Nodecurrent; // current entry
int expectedModCount; // for fast-fail
int index; // current slot
HashIterator() {
expectedModCount = modCount;
// HashMap 对象的 table 数组
Node[] t = table;
current = next = null;
index = 0;
// 在构造方法中初始化 next 引用为 table 数组中第一个不为 null 的元素
if (t != null && size > 0) { // advance to first entry
do {} while (index < t.length && (next = t[index++]) == null);
}
}
// ...
}
通过 entrySet 方法来遍历元素的关键代码就是这些。其他的元素遍历方式小伙伴们可以自己参考源码,通过上面的分析我们应该知道,HashMap 中元素的遍历顺序和元素的插入顺序是没有任何关系的,因为插入元素时主要依据的是元素的键的 hashCode 值,而每个元素的键的 hashCode 没有什么规则(根据键所属的类的实现而定),所以我们并不能试图按照插入元素的顺序来取出元素。如果需要使得取出的元素顺序是按照插入元素的先后顺序排序的话,请使用 LinkedHashMap 。关于 LinkedHashMap,我们将会在之后的文章中再次见到它。
好了,到这里,我们终于把 HashMap 的相关操作分析完了,这里面主要涉及到:
HashMap 的构造(提供 4 个构造方法);
容量(默认为 16,如果自定义初始容量,那么会处理成最小的不小于指定的容量的 2 的次幂数,注意 HashMap 的容量一定会是 2 的次幂数);
扩容机制(每次扩容变成上一次容量的 2 倍,如果当前元素数目达到扩容阀值(负载因子 * 当前 HashMap 总容量),进行扩容);
负载因子(默认 0.75 );
最大容量(Integer.MAX_VALUE - 8);
可以指定的最小容量(1(2^0))。
下面来看另一个 Map 具体类:TreeMap:
TreeMap
这个类名字里面有个 “Tree”,难道又是和树相关?没错,这个具体类就是依赖于红黑树构建的,可能有小伙伴会说了,怎么又是红黑树啊,其实红黑树是一种很有用的数据结构,只是维护的时候比一般的二叉搜索树复杂一点(主要是为了维护高度平衡以保证较高的查找效率),关于代码中怎么去维护它的高度我们就不去深追究了,为了篇幅简洁,同 HashMap 一样,我们在这里主要分析对键值对元素的相关操作原理和一些 TreeMap 特有的性质。先看看它的源码声明:
public class TreeMap
extends AbstractMap
implements NavigableMap, Cloneable, java.io.Serializable {
// ...
}
TreeMap 本身继承自 AbstractMap 抽象类,实现了 NavigableMap 接口,这个 NavigableMap 接口实际上是继承了 SortedMap 接口,并声明了几个额外的方法,下面看看 TreeMap 的相关字段属性:
/**
* The comparator used to maintain order in this tree map, or
* null if it uses the natural ordering of its keys.
*
* @serial
*/
private final Comparator comparator;
// 红黑树的根结点
private transient Entry root;
// 当前 TreeMap 中节点(即键值对元素,下同)的数目
private transient int size = 0;
// 当前 TreeMap 结构化修改(插入、删除元素...)的次数
private transient int modCount = 0;
这里再说一下 comparator 属性,我们知道:TreeMap 的实现原理是红黑树,即为一种二叉搜索树,为了简单起见,我们后面就把它当成二叉搜索树处理,二叉搜索树本身有一个特点:节点的左子树中的节点值都小于该节点值,而节点的右子树节点值都大于该节点值,那么我们在插入元素的时候如何判断插入的节点值和当前的节点值的大小呢?其实就是利用这个 comparator 字段,说白了,这个对象的任务就是为了判断出两个节点的大小关系的,Comparator 是提供了一个泛型参数的接口,我们来看看这个接口的定义:
public interface Comparator {
/**
* @param o1 the first object to be compared.
* @param o2 the second object to be compared.
* @return a negative integer, zero, or a positive integer as the
* first argument is less than, equal to, or greater than the
* second.
* 比较两个对象的大小,如果 o1 大于 o2,返回大于 0 的值,如果 o1 等于 o2,返回 0,
* 如果 o1 小于 o2,返回小于 0 的值
*/
int compare(T o1, T o2);
// ...
}
这个接口正好提供了一个方法,用于比较两个对象的大小。
接下来看看 TreeMap 是用什么数据结构来描述键值对元素的:
static final class Entry implements Map.Entry {
K key;
V value;
// 左右子节点和父节点
Entry left;
Entry right;
Entry parent;
// 当前节点是否为红色节点(任意一个节点颜色要么红色要么黑色,因此叫红黑树),默认为黑色
boolean color = BLACK;
/**
* Make a new cell with given key, value, and parent, and with
* {@code null} child links, and BLACK color.
*/
Entry(K key, V value, Entry parent) {
this.key = key;
this.value = value;
this.parent = parent;
}
public K getKey() {
return key;
}
public V getValue() {
return value;
}
public V setValue(V value) {
V oldValue = this.value;
this.value = value;
return oldValue;
}
public boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry e = (Map.Entry)o;
return valEquals(key,e.getKey()) && valEquals(value,e.getValue());
}
public int hashCode() {
int keyHash = (key==null ? 0 : key.hashCode());
int valueHash = (value==null ? 0 : value.hashCode());
return keyHash ^ valueHash;
}
public String toString() {
return key + "=" + value;
}
}
我们上面已经说过了 TreeMap 是基于红黑树的原理实现的,类比树节点的所需的字段,我们很好理解这个 Entry 类。下面来看看 TreeMap 的构造方法:
public TreeMap() {
comparator = null;
}
public TreeMap(Comparator comparator) {
this.comparator = comparator;
}
public TreeMap(SortedMap m) {
// 遵从指定的 SortedMap 的排序规则
comparator = m.comparator();
try {
buildFromSorted(m.size(), m.entrySet().iterator(), null, null);
} catch (java.io.IOException cannotHappen) {
} catch (ClassNotFoundException cannotHappen) {
}
}
public TreeMap(Map m) {
comparator = null;
putAll(m);
}
仍然是 4 个构造方法,第一个和第二个构造方法没有什么讲的,我们先看看第三个构造方法,很明显这个构造方法用于创建一个具有和参数指定的 SortedMap 相同元素的 TreeMap 对象,实现上主要是通过调用 buildFromSorted 方法,我们来看看这个方法:
private void buildFromSorted(int size, Iterator it,
java.io.ObjectInputStream str,
V defaultVal)
throws java.io.IOException, ClassNotFoundException {
this.size = size;
root = buildFromSorted(0, 0, size-1, computeRedLevel(size),
it, str, defaultVal);
}
这里调用了 buildFromSorted 参数重载的一个方法,并把返回值赋值给了 root,可以猜到这个是一个构建二叉树(其实就是构建红黑树)的过程,我们继续跟进去:
private final Entry buildFromSorted(int level, int lo, int hi,
int redLevel,
Iterator it,
java.io.ObjectInputStream str,
V defaultVal)
throws java.io.IOException, ClassNotFoundException {
/**
* 1、这其实是一个递归构建平衡二叉树(红黑树)的过程,
* 在这个过程中,我们先需要构建出左子树并建立当前节点与左子树的父子关系,
* 然后再构建出右子树并建立当前节点与右子树的父子关系系,
* 最后再返回这个节点,显然,第一次调用这个方法时返回的节点即为整个树的根节点 root。
* 2、我们已经知道这个方法调用的时候传入的是一个 SortedMap 的元素集合的迭代器,
* 而本身 SortedMap 中的元素按照迭代器访问的时候是按照某种规则排好序的,即这个序列是有序的,
* 那么我们在构建平衡二叉树(红黑树)的时候自然要将当前节点的左右子树的高度差不超过 1 ,
* 即在构造的时候我们应该取中间元素作为当前的树的根结点,对于左右子树亦是如此
*/
if (hi < lo) return null;
// 选取中间节点作为左右子树的根结点
int mid = (lo + hi) >>> 1;
Entry left = null;
if (lo < mid)
// 如果中间节点的左边有节点,那么先递归构造左子树
left = buildFromSorted(level+1, lo, mid - 1, redLevel,
it, str, defaultVal);
// extract key and/or value from iterator or stream
// 取迭代器元素的键和值用于创建节点
K key;
V value;
// 从迭代器中取
if (it != null) {
if (defaultVal==null) {
Map.Entry entry = (Map.Entry)it.next();
key = (K)entry.getKey();
value = (V)entry.getValue();
} else {
key = (K)it.next();
value = defaultVal;
}
// 从流中读取
} else { // use stream
key = (K) str.readObject();
value = (defaultVal != null ? defaultVal : (V) str.readObject());
}
// 利用取到的键和值创建当前树的根结点(中间节点)
Entry middle = new Entry<>(key, value, null);
// color nodes in non-full bottommost level red
if (level == redLevel)
middle.color = RED;
// 如果构造出来的左子树不为 null,那么建立当前根结点和左子树的父子关系
if (left != null) {
middle.left = left;
left.parent = middle;
}
if (mid < hi) {
// 如果中间节点的右边有节点,那么递归构造右子树
Entry right = buildFromSorted(level+1, mid+1, hi, redLevel,
it, str, defaultVal);
// 建立当前根结点和右子树的父子关系
middle.right = right;
right.parent = middle;
}
// 返回建立的树的根结点
return middle;
}
OK,我们将递归构造平衡二叉树的过程捋了一遍,第三个构造方法也就结束了,最后是第四个构造方法,可以看到直接调用了 putAll 方法:
public void putAll(Map map) {
int mapSize = map.size();
// 如果当前 map 对象是 SortedMap 类型的对象,
// 证明通过迭代器访问它的元素可以得到一个有序的元素序列,
// 同样的使用 buildFromSorted 方法创建红黑树
if (size==0 && mapSize!=0 && map instanceof SortedMap) {
Comparator c = ((SortedMap)map).comparator();
if (c == comparator || (c != null && c.equals(comparator))) {
++modCount;
try {
buildFromSorted(mapSize, map.entrySet().iterator(),
null, null);
} catch (java.io.IOException cannotHappen) {
} catch (ClassNotFoundException cannotHappen) {
}
return;
}
}
// 否则利用调用父类的 putAll 方法
super.putAll(map);
}
我们再一次看看其父类( AbstractMap )的 putAll 方法:
public void putAll(Map m) {
for (Map.Entry e : m.entrySet())
put(e.getKey(), e.getValue());
}
很简单的逻辑,对每个元素调用了 put 方法,由于多态的特性,它会调用子类(即 TreeMap )的 put 方法,那么我们再在 TreeMap 中看一下其 put 方法:
public V put(K key, V value) {
Entry t = root;
if (t == null) {
// 这一句是为了防止 key 为 null 的情况
compare(key, key); // type (and possibly null) check
// 如果当前 root 字段为 null,那么先创建 root 节点
root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
}
int cmp;
Entry parent;
// split comparator and comparable paths
Comparator cpr = comparator;
// 如果当前 TreeMap 指定的 Comparator 对象不为 null,
// 那么使用 TreeMap 的 Comparator 进行比较
if (cpr != null) {
do {
parent = t;
cmp = cpr.compare(key, t.key);
// 结果小于 0 则作为左子结点
if (cmp < 0)
t = t.left;
// 大于 0 则作为右子节点
else if (cmp > 0)
t = t.right;
// 等于 0 则认为是键冲突,直接更新值并返回旧值
else
return t.setValue(value);
} while (t != null);
}
// 否则则调用 key 对象的 compareTo 方法比较(key 的类型必须实现 Comparable 接口)
else {
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable k = (Comparable) key;
do {
parent = t;
cmp = k.compareTo(t.key);
// 小于 0 则作为左子结点,大于 0 则作为右子节点,等于 0 则直接更新值并返回旧值
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
// 新建节点来储存这个键值信息
Entry e = new Entry<>(key, value, parent);
// 建立父子关系
if (cmp < 0)
parent.left = e;
else
parent.right = e;
// 调整红黑树,保证其高度平衡
fixAfterInsertion(e);
size++;
modCount++;
return null;
}
好了,看完了这个方法意味着我们把 TreeMap 的构造方法看完了,下面来看看 get 方法吧,其实如果你熟悉红黑树的话,基本上就能猜到 get 方法是怎么实现的了:
public V get(Object key) {
Entry p = getEntry(key);
return (p==null ? null : p.value);
}
看来是通过 getEntry 方法实现的,那么继续跟进:
final Entry getEntry(Object key) {
// Offload comparator-based version for sake of performance
if (comparator != null)
// 如果当前 TreeMap 指定的 Comparator 对象不为 null,
// 那么通过当前 Treemap 的 Comparator 对象来进行元素大小比较
return getEntryUsingComparator(key);
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable k = (Comparable) key;
Entry p = root;
// 循环向下查找,如果要查找的 key 小于当前节点,
// 那么向左子树继续查找,如果要查找的 key 大于当前节点,
// 那么向右子树继续查找,否则的话证明找到了,返回当前节点
while (p != null) {
int cmp = k.compareTo(p.key);
if (cmp < 0)
p = p.left;
else if (cmp > 0)
p = p.right;
else
return p;
}
// 没找到返回 null
return null;
}
当 TreeMap 的 Comparator 对象不为 null 的时候是通过 getEntryUsingComparator 方法查找的,那么继续看一下这个方法:
final Entry getEntryUsingComparator(Object key) {
@SuppressWarnings("unchecked")
K k = (K) key;
Comparator cpr = comparator;
if (cpr != null) {
Entry p = root;
// 同样的,小于向左子树找,大于向右子树找,等于证明找到了,直接返回
while (p != null) {
int cmp = cpr.compare(k, p.key);
if (cmp < 0)
p = p.left;
else if (cmp > 0)
p = p.right;
else
return p;
}
}
// 没找到返回 null
return null;
}
到了这里,我们把 get 方法也看完了,我想你也明白了为什么 get 方法查找值的时间复杂度为 O(logn) 了,因为 get 方法的时间复杂度主要取决于 while 循环的执行次数,很明显,这里的 while 循环的执行次数为树的高度,即 logn。最后,来看一下移除元素的方法:
public V remove(Object key) {
// 现寻找要删除的节点,找到了进行删除,没找到就直接返回
Entry p = getEntry(key);
if (p == null)
return null;
V oldValue = p.value;
// 进行节点的删除并调整树的结构以保证红黑树的高度平衡
deleteEntry(p);
// 返回删除的节点的 “值”
return oldValue;
}
好了,remove 方法的流程上就到这里了,这里就不过细的介绍红黑树平衡的维护具体过程了。
在元素遍历方面, TreeMap 和 HashMap 提供的遍历元素的方法还是差不多的:通过 entrySet、keySet、forEach(JDK 1.8) 方法,这里就不列举了,有兴趣的小伙伴参考一下 HashMap 部分的元素遍历,或者是看看相关源码。
整体看来,TreeMap 最大的特点是能根据插入的键值对的键来对键值对元素节点进行排序,而当我们遍历 TreeMap 对象的时候取得的元素顺序是按照某个规则来进行排序的,具体规则我们可以在创建 TreeMap 对象的实现传入一个 Comparator 对象的参数来进行指定。需要注意的是:如果没有指定 TreeMap 的 Comparator 对象,那么需要保证 TreeMap 储存的键值对元素的 “键” 是实现了 Comparable 接口的,否则会报类型转换异常(ClassCastException),这一点在源码的分析中已经提到了。
而相对于 HashMap 来说,TreeMap 没有什么初始容量和负载因子的概念,因为它是用的是红黑树这种数据结构,即为动态申请内存空间(插入一个元素就申请一个元素的内存空间),也因为如此,其插入元素和查询元素的时间复杂度均为 O(logn),即为树的高度,n 为 TreeMap 中节点数。下面我们来看一个小小的应用场景:如何指定 TreeMap 的排序方式为对值进行排序?
指定 TreeMap 的元素排序方式
我们已经知道 TreeMap 默认会依据键值对元素的键来对元素进行排序。我们也可以通过自定义的 Comparator 接口对象来指定其对键的排序方式,那么可不可以通过指定对元素的值的排序方式来对元素进行排序呢?答案是可以的,不过需要动一点脑筋:我们可以利用 TreeMap 会利用键来对键值对元素进行排序的特点,来自定义一个“键的包装类”来作为新的键,我们就叫它 KeyWrap 吧,这个 KeyWrap 内部有两个引用,分别指向原本的 Key 和 Value 两个属性,我们使得这个类实现 Comparable 接口,并且重写其 compareTo 方法,这个方法直接调用 Value 的 compareTo 方法作为返回值。同时,因为 TreeMap 本身需要用到 Key 的 equals 方法来进行键的等价比较,因此我们实现这两个方法并且调用对应键的方法来作为返回值。好了,思路就到这里了,下面来看看代码:
import java.util.Map;
import java.util.TreeMap;
public class CustomTreeMapSortMethod {
// 自定义的描述键的类
static class MyKey {
int i;
MyKey(int i) {
this.i = i;
}
@Override
public int hashCode() {
return i;
}
@Override
public boolean equals(Object obj) {
return obj == this || obj instanceof MyKey && ((MyKey) obj).i == i;
}
@Override
public String toString() {
return String.valueOf(i);
}
}
// 自定义的描述值的类,实现 Comparable 接口来自定义排序方式
static class MyValue implements Comparable<MyValue> {
char c;
MyValue(char c) {
this.c = c;
}
// 按属性 c 的值从小到大排序
@Override
public int compareTo(MyValue o) {
if (o == null) {
throw new IllegalArgumentException("The argument other can not be null!");
}
return c - o.c;
}
@Override
public String toString() {
return String.valueOf(c);
}
}
// 自定义的 KeyWrap 类,实现 Comparable 接口来自定义排序方式
static class KeyWrap implements Comparable<KeyWrap> {
// 指向 key 的引用,这里也可以采用直接继承 MyKey 类的方法,
// 这样的可以不用重写 equals 方法
MyKey key;
MyValue val; // 指向 value 的引用
KeyWrap(MyKey key, MyValue val) {
this.key = key;
this.val = val;
}
int compare(KeyWrap other) {
if (other == null) {
throw new IllegalArgumentException("The argument other can not be null!");
}
// 因为要依据“值”来进行排序,所以返回 “值”比较的结果
return val.compareTo(other.val);
}
@Override
public int compareTo(KeyWrap o) {
return compare(o);
}
// 因为是自定义的 KeyWrap ,真正的 key 还是 MyKey 类对象,
// 所以 equals 方法还得用 MyKey 类的对象来进行比较,即 key 属性
@Override
public boolean equals(Object obj) {
return obj == this || obj instanceof KeyWrap && ((KeyWrap) obj).key.equals(key);
}
}
public static void main(String[] args) {
int eleLen = 10;
// 注意这里使用的 KeyWrap 类型来作为键
TreeMap<KeyWrap, MyValue> map = new TreeMap<>();
MyKey[] keys = new MyKey[eleLen];
MyValue[] values = new MyValue[eleLen];
KeyWrap[] keyWraps = new KeyWrap[eleLen];
for (int i = 0; i < eleLen; i++) {
keys[i] = new MyKey(eleLen - 1 - i);
values[i] = new MyValue((char) (i + '0'));
keyWraps[i] = new KeyWrap(keys[i], values[i]);
map.put(keyWraps[i], values[i]);
}
for (Map.Entry<KeyWrap, MyValue> entry : map.entrySet()) {
System.out.println("key: " + entry.getKey().key + ", value: " + entry.getValue());
}
}
}
来看看结果:
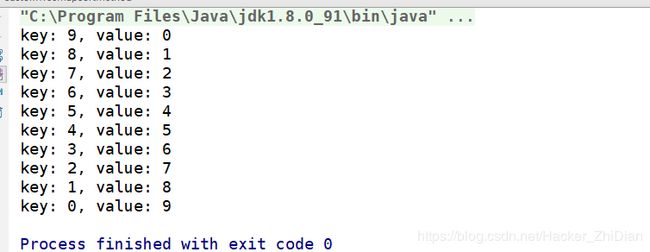
OK,成功的验证了我们的想法,代码中也给出了详细的注释,借助这个思想,我们完全可以通过继承 TreeMap 来封装一个按照值来对元素进行排序的 ValueSortTreeMap,有兴趣的小伙伴们可以自己尝试实现一下。
好了,这篇文章中我们一起从源码的角度上看了一下 HashMap 和 TreeMap 的具体实现,并总结了一下他们各自的特点。同时介绍了如何使得 TreeMap 按照值来对元素进行排序。下篇文章我们将一起来看一下 IdentityHashMap 、WeakHashMap 等具体类的实现。
如果博客中有什么不正确的地方,还请多多指点。如果这篇文章对您有帮助,请不要吝啬您的赞,欢迎继续关注本专栏。
谢谢观看。。。