【小白学爬虫连载(8)】--scrapy框架入门教程
欢迎大家关注公众号【哈希大数据】
欢迎大家关注公众号【哈希大数据】
【小白学爬虫连载(1)】-爬虫框架简介
【小白学爬虫连载(2)】--Requests库介绍
【小白学爬虫连载(3)】--正则表达式详细介绍
【小白学爬虫连载(4)】-如何使用chrome分析目标网站
【小白学爬虫连载(5)】--Beautiful Soup库详解
【小白学爬虫连载(6)】--Selenium库详解
【小白学爬虫连载(7)】--scrapy框架的安装
【小白学爬虫连载(8)】--scrapy框架入门教程
【小白学爬虫连载(9)】--scrapy构架设计分析
【小白学爬虫连载(10)】--如何用Python实现模拟登陆网站
【小白学爬虫连载(11)】--获取免费高匿代理IP
【小白学爬虫连载(11)】--pyquery库详解
【小白学爬虫连载(13)】--Scrapy如何突破反爬虫
爬取流程分析
目标网站:http://quotes.toscrape.com/
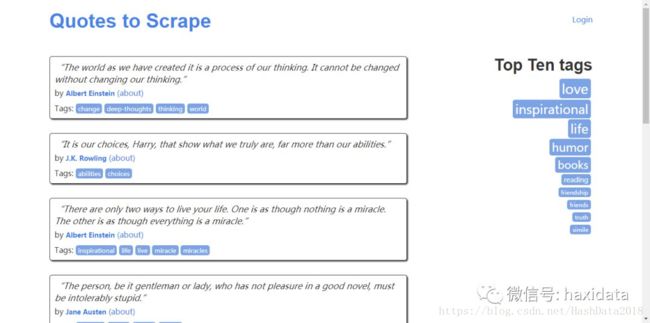
爬取目标:获取所有名言、其作者和标签
爬取流程:首先获取首页目标信息,其次注意到页面中存在下一页的链接,采用递归调用的方式进行翻页爬取,最后保存爬取信息。
接下来介绍如何用scrapy框架实现以上流程。
创建项目
在开始爬取之前,您必须创建一个新的Scrapy项目。 在命令窗口中进入您打算存储代码的目录中,运行下列命令:
scrapy startproject tutorial quotes.toscrape.com该命令将会创建包含下列内容的 tutorial 目录:
tutorial/ scrapy.cfg tutorial/ __init__.py items.py pipelines.py settings.py spiders/ __init__.py ...
这些文件分别是:
scrapy.cfg: 项目的配置文件
tutorial/: 该项目的python模块。之后您将在此加入代码。
tutorial/items.py: 项目中的item文件.
tutorial/pipelines.py: 项目中的pipelines文件.
tutorial/settings.py: 项目的设置文件.
tutorial/spiders/: 放置spider代码的目录.
定义Item
Item 是保存爬取到的数据的容器;其使用方法和python字典类似, 并且提供了额外保护机制来避免拼写错误导致的未定义字段错误。
类似在ORM中做的一样,您可以通过创建一个 scrapy.Item 类, 并且定义类型为 scrapy.Field 的类属性来定义一个Item。 (如果不了解ORM, 不用担心,您会发现这个步骤非常简单)
首先根据需要从quotes.toscrape获取到的数据对item进行建模。 我们需要从quotes.toscrape中获取名言,作者以及标签。 对此,在item中定义相应的字段。编辑 tutorial 目录中的 items.py 文件:
import scrapy
class QuoteItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
text = scrapy.Field()
author = scrapy.Field()
tags = scrapy.Field()
一开始这看起来可能有点复杂,但是通过定义item,您可以很方便的使用Scrapy的其他方法。而这些方法需要知道您的item的定义。
编写第一个爬虫(Spider)
命令窗口中,在 tutorial/spiders 目录下,输入命令:
scrapy genspider quotes quotes.toscrape.com
在该目录下得到quotes.py文件,初始代码如下:
# -*- coding: utf-8 -*-
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
allowed_domains = ["quotes.toscrape.com"]
start_urls = ['http://quotes.toscrape.com/']
def parse(self, response):
pass完成爬取任务的完整代码如下:
# -*- coding: utf-8 -*-
import scrapy
from quotetutorial.items import QuoteItem
class QuotesSpider(scrapy.Spider):
# spider的名字,该名字必须是唯一的,您不可以为不同的Spider设定相同的名字。
name = "quotes"
allowed_domains = ["quotes.toscrape.com"]
# 包含了Spider在启动时进行爬取的url列表。 因此,第一个被获取到的页面将是其中之一。 后续的URL则从初始的URL获取到的数据中提取。
start_urls = ['http://quotes.toscrape.com/']
# parse() 是spider的一个方法。 被调用时,每个初始URL完成下载后生成的 Response 对象将会作为唯一的参数传递给该函数。 该方法负责解析返回的数据(response data),提取数据(生成item)以及生成需要进一步处理的URL的 Request 对象。
def parse(self, response):
# 从网页中提取数据有很多方法。Scrapy使用了一种基于 XPath 和 CSS 表达式机制,有以下四个基本方法:
#1. xpath(): 传入xpath表达式,返回该表达式所对应的所有节点的selector list列表 。
#2. css(): 传入CSS表达式,返回该表达式所对应的所有节点的selector list列表.
#3. extract(): 序列化该节点为unicode字符串并返回list。
#4. re(): 根据传入的正则表达式对数据进行提取,返回unicode字符串list列表。
quotes = response.css('.quote')
for quote in quotes:
item = QuoteItem()
text = quote.css('.text::text').extract_first()
author = quote.css('.author::text').extract_first()
tags = quote.css('.tags .tag::text').extract()
item['text'] = text
item['author'] = author
item['tags'] = tags
yield item
# 获取下一页的链接
next = response.css('.pager .next a::attr(href)').extract_first()
# 补全链接
url = response.urljoin(next)
# 利用Request函数实现递归调用parse解析下一页内容
yield scrapy.Request(url=url, callback=self.pars提取数据
从网页中提取数据有很多方法。Scrapy使用了一种基于 XPath 和 CSS 表达式机制,有以下四个基本方法:
xpath(): 传入xpath表达式,返回该表达式所对应的所有节点的selector list列表 。
css(): 传入CSS表达式,返回该表达式所对应的所有节点的selector list列表.
extract(): 序列化该节点为unicode字符串并返回list。
re(): 根据传入的正则表达式对数据进行提取,返回unicode字符串list列表。
具体的用法及语法格式可查看:http://scrapy-chs.readthedocs.io/zh_CN/0.24/topics/selectors.html#topics-selectors
爬取并保存爬取到的数据
进入项目根目录,执行以下命令启动爬虫:
scrapy crawl quotes -o items.json #保存为json格式
scrapy crawl quotes -o items.jl #保存为json格式
scrapy crawl quotes -o items.csv #保存为json格式
这是简单的保存几种数据的方法,后面分享如何将数据保存到MongoDB数据库中。
小结
本次分享简单介绍Python重要的爬虫框架scrapy如何入门,如何创建项目,编写第一个爬虫,提取数据,保存数据,后面会用scrapy框架编写一个爬取新闻的爬虫,届时将分享如何将数据保存到MongoDB数据库中。