用gensim库训练word2vec踩过的坑
最近在进行毕设,也用tensorflow写了一个skip-gram算法的embedding
由于是论文复现,需要的embedding matrix(skip-gram,dimension = 400,negative samples =10) 和网上现有的训练好的词向量不太一样,于是开始尝试自己训练
整个过程分为两部分
1.训练demo: text8.zip
先贴代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from gensim.models import word2vec
import logging
# 主程序
logging.basicConfig(
format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
sentences = word2vec.Text8Corpus(r"C:\Users\CJ17\Desktop\text8")
model = word2vec.Word2Vec(sentences, size=100, sg=1)
主要的坑在于word2vec.Text8Corpus这个函数
仔细阅读这个函数的源码,看到smart_open()函数,
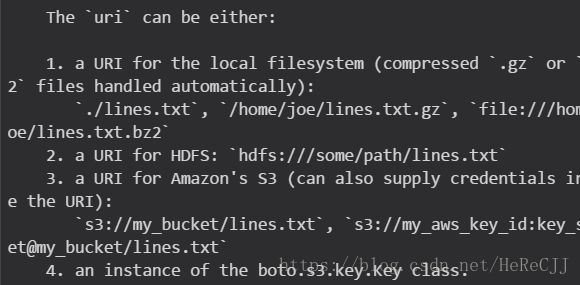
也就是说在这个函数里可以传入4种链接。
在尝试了('./text8') ('text8')之后都失败,看到stackoverflow上查到相关问题,应该是没有链接到资源,资源不存在
尝试了一些解决办法,最后进行了这几步:
1.下载text8.zip文档 (http://mattmahoney.net/dc/text8.zip )
2.解压(一开始我也没有解压,但就是提示文件不存在,后来看到有博主将文件解压后成功的于是尝试)
3.将其path传入函数
然后有个python3的编码问题又来了(真是天大的编码问题!!!)
加了两行
#!/usr/bin/env python
# -*- coding: utf-8 -*-
并且将文件的字符串添加r,后来成功!
2.用wiki语料库进行训练
https://dumps.wikimedia.org/enwiki/latest/enwiki-latest-pages-articles.xml.bz2(dump下载,约13.9G,2018年3月)
参考 中英文维基百科语料上的word2vec实验
分为两个部分,一部分是将xml解析为txt文档(process_wiki.py)。python3下编码问题的原因让我跑了五个小时之后依然失败
认真地看(xue xi)encode 和 decode 之后( python3的decode()与encode())把原来代码里的decode()删除
就采用output.write(space.join(text) + "\n")就可以写入文档,而不需要像博主写的那样
第二部分就是进行word2vec的过程(train_word2vec_model.py),主要注意Word2Vec函数的使用,以及各个参数的含义和作用
word2vec词向量训练及gensim的使用 这篇文章讲得很清楚,以下是我采用的各个参数(真的好久啊 TAT 为什么我不去服务器上跑)
model = Word2Vec(LineSentence(inp),sg=1, size=400, window=10, min_count=5,
negative = 10,workers=multiprocessing.cpu_count())

测试出的200维的词向量结果~~