利用python进行数据分析(1)
利用python进行数据分析(1)
一、NumPy基础:数组和⽮量计算
NumPy(Numerical Python的简称)是Python数值计算最重要的基础包。⼤多数提供科学计算的包都是⽤NumPy的数组作为构建基础。
import numpy as np #使用Numpy
1.1 NumPy的ndarray:⼀种多维数组对象
NumPy最重要的⼀个特点就是其N维数组对象(即ndarray),该对象是⼀个快速⽽灵活的⼤数据集容器。你可以利⽤这种数组对整块数据执⾏⼀些数学运算,其语法跟标量元素之间的运算⼀样。
创建ndarray:
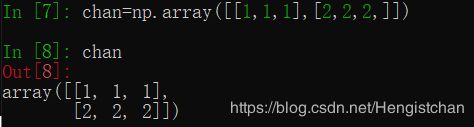
array函数接受⼀切序列型的对象(包括其他数组),然后产⽣⼀个新的含有传⼊数据的
NumPy数组。


嵌套序列将会被转换为⼀个多维数组:
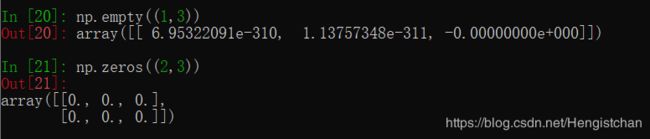
zeros和ones分别可以创建指定⻓度或形状的全0或全1数组。empty可以创建⼀个没有任何具体值的数组。要⽤这些⽅法创建多维数组,只需传⼊⼀个表示形状的元组即可:
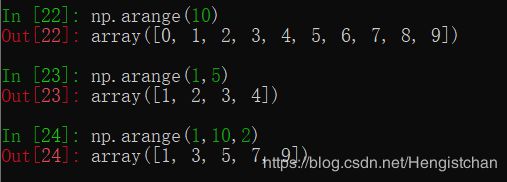
arange是Python内置函数range的数组版:
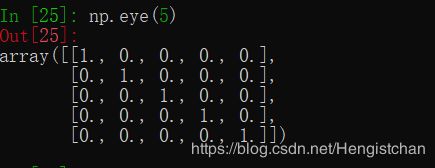
eye()创建一个对角线为 1 ,其余为 0 的矩形数组
ndarray的数据类型
dtype(数据类型)是⼀个特殊的对象,它含有ndarray将⼀块内存解释为特定数据类型所需的信息:

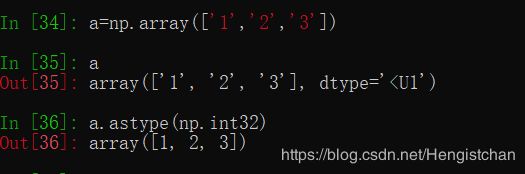
通过ndarray的astype⽅法明确地将⼀个数组从⼀个dtype转换成另⼀个dtype:

如果将浮点数转换成整数,则⼩数部分将会被截取删除。
如果某字符串数组表示的全是数字,也可以⽤astype将其转换为数值形式:
NumPy数组的运算

基本的索引和切片
- 索引
一维数组的索引和python的相似

当将⼀个标量值赋值给⼀个切⽚时(如arr[3:6]=10),该值会⾃动传播(也就说后⾯将会讲 到的“⼴播”)到整个选区。
在⼀个⼆维数组中,各索引位置上的元素不再是标量⽽是⼀维数组:
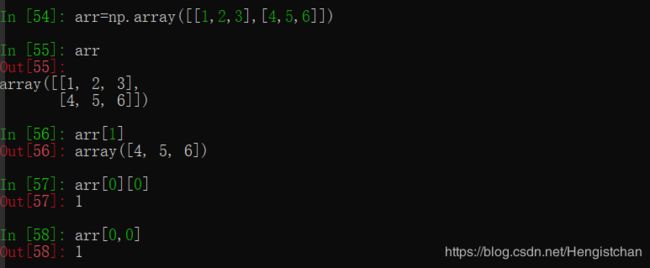
相似地,在多维数组中,如果省略了后⾯的索引,则返回对象会是⼀个维度低⼀点的ndarray(它含有⾼⼀级维度上的所有数据。
- 切片
ndarray的切⽚语法跟Python列表这样的⼀维对象差不多,对于之前的⼆维数组arr2d,其切⽚⽅式稍显不同:
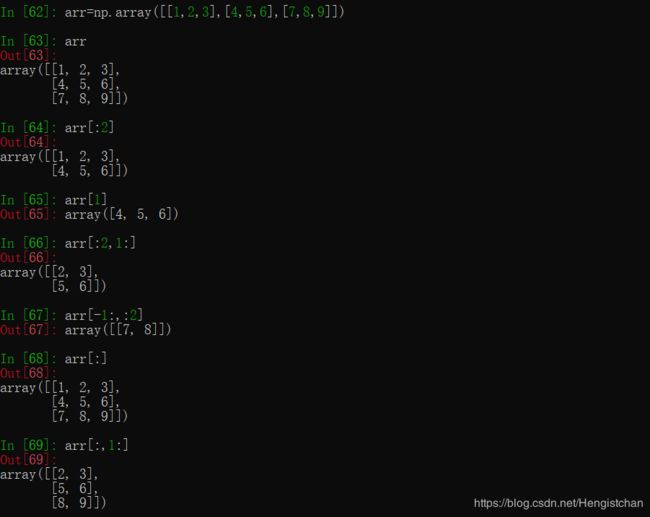
- 切⽚是沿着⼀个轴向选取元素的,表达式
arr2d[:2]可以被认为是“选取arr2d的前两⾏”。 - “只有冒号”表示选取整个轴
- 对切⽚表达式的赋值操作也会被扩散到整个选区

布尔型索引
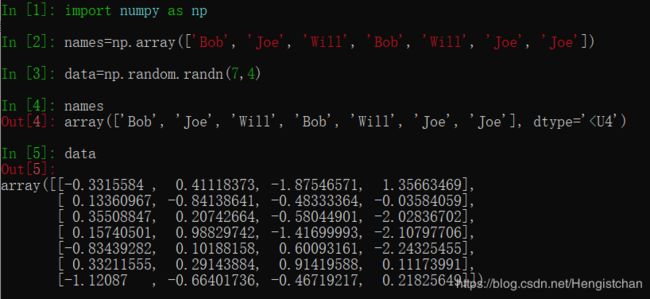
假设有一个用于存储数据的数组以及一个存储姓名的数组(含有重复项)且使用numpy.random中的randn函数生成一些正态分布的随机数据:
假设每个名字都对应data数组中的一行,而我们想要选出对应于名字"Bob"的所有行。跟算术运算一样,数组的比较运算(如==)也是矢量化的。因此,对names和字符串"Bob"的比较运算将会产生一个布尔型数组:

这个布尔型数组可用于数组索引:
布尔型数组的长度必须跟被索引的轴长度一致。如果布尔型数组的长度不对,布尔型选择就会出错,因此一定要小心。

此外,还可以将布尔型数组跟切片、整数(或整数序列,稍后将对此进行详细讲解)混合使用:

要选择除"Bob"以外的其他值,既可以使用不等于符号(!=),也可以通过~对条件进行否定:


将data中的所有负值都设置为0:
data[data < 0] = 0

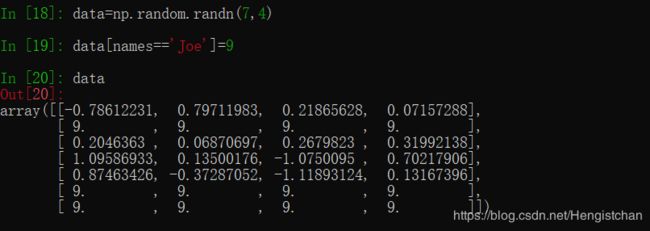
通过一维布尔数组设置整行或列的值:
花式索引
数组转置和轴对换
数组不仅有transpose方法,还有一个特殊的T属性: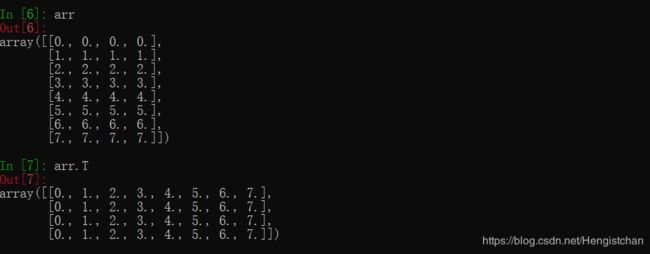
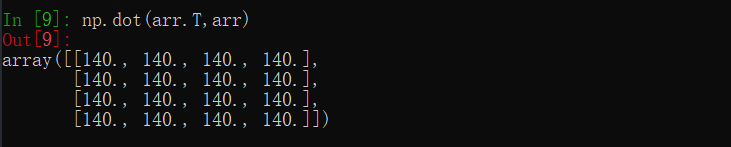
利用np.dot计算矩阵内积:
1.2 通用函数:快速的元素级数组函数
**通用函数(即ufunc)**是一种对ndarray中的数据执行元素级运算的函数。你可以将其看做简单函数(接受一个或多个标量值,并产生一个或多个标量值)的矢量化包装器。
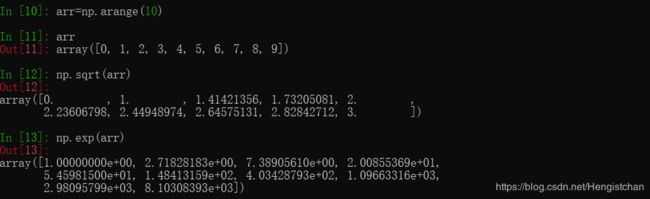
许多ufunc都是简单的元素级变体,如sqrt和exp:
二元ufunc返回一个结果数组:
numpy.maximum(x,y)计算了x和y中元素级别最大的元素。
1.3 利用数组进行数据处理
NumPy数组使你可以将许多种数据处理任务表述为简洁的数组表达式(否则需要编写循环)。用数组表达式代替循环的做法,通常被称为矢量化。
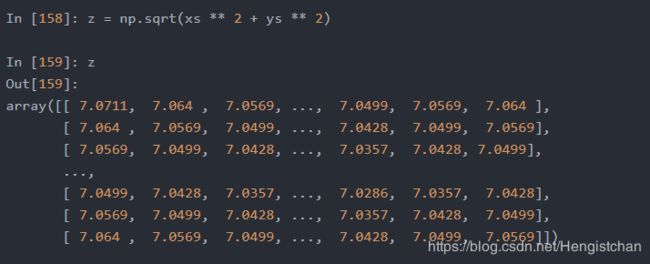
在一组值(网格型)上计算函数sqrt(x2+y2),np.meshgrid函数接受两个一维数组,并产生两个二维矩阵(对应于两个数组中所有的(x,y)对):
将条件逻辑表述为数组运算
numpy.where函数是三元表达式x if condition else y的矢量化版本。
eg: 把4 X 4数组中的正数换成1,负数换成0
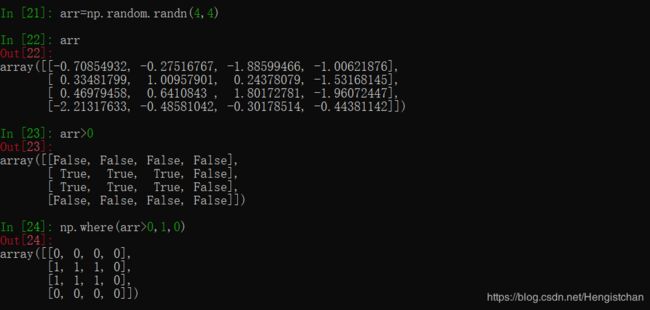
传递给where的数组大小可以不相等,甚至可以是标量值。
数学和统计方法


用于布尔型数组的方法
在上面这些方法中,布尔值会被强制转换为1(True)和0(False)。还有两个方法any和all,它们对布尔型数组非常有用。any用于测试数组中是否存在一个或多个True,而all则检查数组中所有值是否都是True 。
排序
通过 np.sort()进行就地排序
唯一化以及其它的集合逻辑

用于数组的文件输入输出
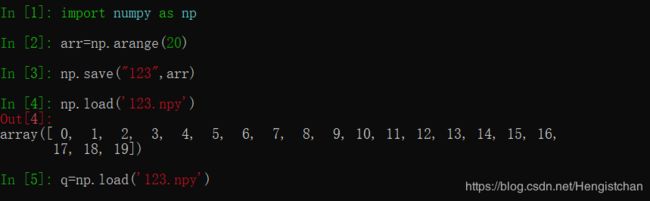
np.save和np.load是读写磁盘数组数据的两个主要函数。
默认情况下,数组是以未压缩的原始二进制格式保存在扩展名为.npy的文件中的:
线性代数
- 用于矩阵乘法的
x.dot(y),等价于np.dot(x,y)
伪随机数生成
numpy.random模块增加了一些用于高效生成数组样本值的函数。
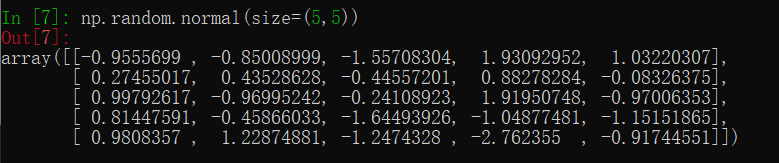
np.random.normal:生成标准正态分布的样本数组
np.random.seed更改随机数种子np.random.RandomState创建一个与其他种子隔离的随机数生成器