搭建多节点Hadoop集群,并对NameNode和SecondaryNameNode进程进行分离操作
主机环境:
Centos7.3(自定义台数,此处举例使用3台)
安装前准备:
JDK:
jdk-8u144-linux-x64.tar.gz
Hadoop:
http://archive.cloudera.com/cdh5/cdh/5/hadoop-2.6.0-cdh5.7.0.tar.gz
在单机模式及小节点集群的Hadoop集群配置,往往NameNode和SecondaryNameNode进程在同一主机上,在企业运营环境中,一旦发生主机宕机等问题,那么整个Hadoop都会瘫痪,对整个大数据的集群会造成极大损失,为此,当节点数大于等于2之后,便可以进行配置,将NameNode和SecondaryNameNode进行分离,使SecondaryNameNode分配到从节点上,降低业务差错。
安装步骤:
配置涉及到Linux操作中配置hosts映射、关闭防火墙、节点间ssh免密认证,需要使用root账户登录各节点,对系统的配置参考前篇博文《Centos7下安装Cloudera Manager5.7.0》,步骤直接跳过,修改映射添加master(作为主节点),slave1,slave2,并直接开始对Hadoop进行配置:
1.下载并解压:
hadoop-2.6.0-cdh5.7.0.tar.gz
[root@master]# tar -zxvf hadoop-2.6.0-cdh5.7.0.tar.gz -C /opt
2.对hadoop配置环境变量并生效:
[root@master]# vim /etc/profile
export HADOOP_HOME=/opt/hadoop-2.6.0-cdh5.7.0
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME:$PATH
source /etc/profile
3.修改hadoop配置文件:
[root@master hadoop]# cd /app/hadoop-2.6.0-cdh5.7.0/etc/hadoop
[root@master hadoop]# vim core-site.xml

[root@master hadoop]# vim hadoop-env.sh
export JAVA_HOME=/usr/jvm/jdk1.8.0
export HADOOP_LOG_DIR=/opt/hadoop-2.6.0-cdh5.7.0/logs

[root@master hadoop]# vim hdfs-site.xml

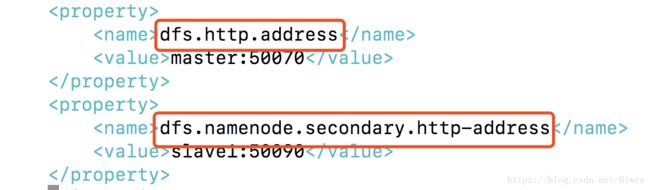
在常规配置之后,添加SecondaryNameNode的http端口,修改为需要放置该进程的节点,如:slave1
[root@master hadoop]# vim mapred-site.xml
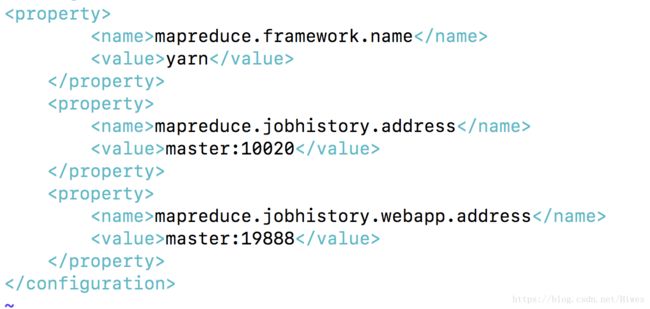
[root@master hadoop]# vim slaves
master
slave1
slave2

[root@master]$ vim yarn-site.xml


常规配置结束,但是还需要增加一个masters文件,作为SecondaryNameNode的节点,此处设置为slave1:
[root@master hadoop]# vim masters
slave1

到此,所有配置已经完毕,初始化HDFS并启动Hadoop,并连接到slave1查看进程:
[root@master hadoop-2.6.0-cdh5.7.0]# bin/hadoop namenode -format
[root@master hadoop-2.6.0-cdh5.7.0]# sbin/start-all.sh
[root@master hadoop-2.6.0-cdh5.7.0]# ssh slave1
[root@slave1 ~]# jps

配置完成。