Hibernate 总结
Hibernate
Hibernate是什么?
- Hibernate是一个框架(framework)
- Hibernate是一个orm框架
- Orm(object relation mapping)对象关系映射 框架
- Hibernate处于项目的持久层,正因为如此,所以有人又把hibernate称为持久层框架
- hibernate实际上是对jdbc轻量级的封装
总结:hibernate是对jdbc进行轻量级封装的orm框架,充当项目的持久层
Hibernate Core
就是Hibernate的核心,使用HQL检索方式进行查询,也可以使用本地的sql语句
Hibernate标注(hibernate Annotations)
通过使用Hibernate Annotations 标注,减少XML描述符的使用,在编译期间进行检查,减少配置工作
Hibernate EntityManager
它在core基础上实现了符合JPA规范持久化提供者(Hibernate Java Persistence)
Hibernate 可以应用于任何Java ee 5 应用服务器,或者EJB3.0容器
也可以用在Java Se中
除了Hibernate 这个ORM框架外还有:
apache ojb
toplink
ibatis
ejb cmp
为什么需要hibernate?
Adobe Reader
>快速入门案例
>hibernate开发有三种方式:
*Domain object ->mapping->db
*db->用工具生成mapping和Domain
*由映射文件开始
1.创建项目
2.引入开发包
3.开发domain对象
4.开发关系映射文件,作用是用于指定domain对象和表的关系,该文件的取名规范:
domain对象名称.hbm.xml 一般放在和domain对象同一个文件夹下
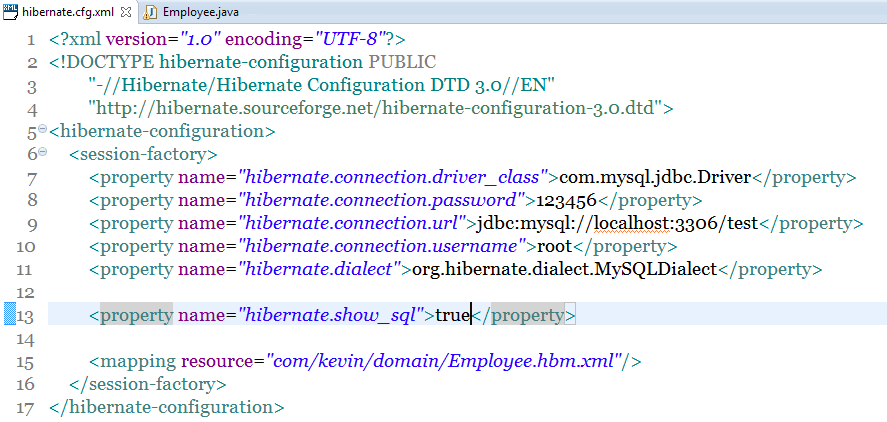
- 配置 hibernate.cfg.xml文件 放在src下 ,该文件用于配置连接的数据库类型,用户名,密码,url
hibernate对service提供的接口和类
数据持久化层:Configuration
SessionFactory
Session
Transaction
使用步骤:
- 创建 Configuration 该对象用于读取habernate.cfg.xml文件
- Configuration config = new Configuration().configure();//加载配置文件
- 创建SessionFactory[这是一个会话工厂,是一个重量级的类]
SessionFactory sessionFactoy = configuration.buildSessionFactory();
- 创建Session 相当于是jdbc的connection
Session session = sessionFactory.openSession();
- 对于hibernate而言,在增删修改操作时候,必须用事务,否则不生效
(类似于我用过的JdbcUtils)
Transation transaction = session.beginTransactioj();
transaction.commit();//提交事务
这次让hibernate自动完成 domain->映射文件->表的工作
pojo类要求
- pojo类是和一张表对应
- pojo需要一个主键属性(属于标识一个Pojo对象):最好是无业务意义的
- 除了主键属性外,它应当还有其他的属性,同时要提供set和get方法
- 需要提供默认的构造方法
pojo其实就是一个javabean pojo主要是区别ejb
- pojo / domain对象中的属性只有在hbm.xml文件中配置才会被hibernate管理
如果hbm.xml中多配了属性,会报错
- 属性一般是private修饰
- 对象关系映射文件有些属性是可以不用配置的,hibernate有默认值
比如class中table如果不配,则以类名开头小写作为表名
property 中的type如果不配,hibernate会根据类中的属性类型,选择一个适当的类型
细节

Configuration:
>负责管理hibernate的配置信息
>读取hibernate.cfg.xml
>加载hibernate.cfg.xml配置文件中配置的驱动,url,用户名,密码,连接池
>管理 *.hbm.xml对象关系文件
如果hibernate.cfg.xml已经移动或者修改了名字,
Configuration c = new Configuration().config(new File(“”));
SessionFactory:
>缓存sql语句和某些数据
>在应用程序初始化的时候创建,是一个重量级的类,一般使用单例模式
>如果某个应用访问多个数据库,则应使用多个会话工厂
>通过session工厂得到session
session = factory.openSession();
session = factory.getCurrentSession();
这两个方法获得session经常被问?
open方法: 创建一个新的session
current方法:获取和当前线程绑定的session,换言之,获取的session是关于当前线程的。
*注意:如果希望使用getCurrentSession()我们需要配置:
hibernate.cfg.xml中配置:
*如何选择使用哪个方法获得session?如果在同一个线程中需要使用同一个session,则用getcurrent方法,如果需要使用不同的session,则使用openSession();
*使用getCurrent方法获得的session,在事务提交后或者回滚后,session会自动关闭。。。
通过openSession方法获得的session,必须手动关闭!
*在查询的时候,如果使用的是currentSession(),必须使用事务
*局部事务(thread):一个应用程序操作一个数据库,针对一个数据库的事务
*全局事物(jta):跨数据库的事务
*如何确定session有没有及时关闭?
window: netstat -an 查端口
openSession()和getCurrentSession()深入
在SessionFactory启动时候,Hibernate会根据配置创建相应的CurentSessionContext,
getCurrentSession()被调用时,实际调用的是currentSessionContext.currentSession();
在上述方法被调用的时候,如果当前Session为空,currentSession会调用openSession();
Session
get()和load()的区别
1.get()方法直接返回实体类,如果查询不到则返回null.
load()会返回一个代理对象;当代理对象被掉用时,如果数据不存在,就会抛出
org.hibernate.ObjectNotFoundException异常
2.load先到缓存中去查,如果没有则返回一个代理对象(不马上到DB中去查),等后面使用这个代理对象操作的时候,才去DB中查询,这就是我们常说的load在默认情况下支持延迟加载 ( lazy ),如果需要禁用懒加载:lazy=”false”
3.get()方法先到缓存中去查,如果没有就到DB中去查,总之,如果你确定DB中有这个对象就用load(),不确定就用get()
缓存:
| 当查询时先到缓存中去查询,如果查询不到,到数据库中查询,然后把结果可能放到2级缓存,再一次查询时,可能在2级缓存中查询到,放到1级缓存; |
Query
query接口类型的对象可以对数据库操作,它可以使用HQL, QBC, QBE
和原生的SQL(native Sql)对数据库操作;
query = session.createQuery(“hql”);
Criteria
crit = session.createCriteria(Customer.class);
cirt.setMaxResults(30);//限制30条
List
HQL 语句
面向对象的查询语句,与SQL不同,HQL中对象名是区分大小写的(除了java类和数学其他不区分大小写);hql中查询的是对象而不是表,并且支持多态;HQL主要通过Query来操作,Query的创建方式:
Query query = session.createQuery(hql);
- from Person
- from User user where user.name=:name
- from User user where user.name=:name and user.birthday < :birthday
取出部分属性
hibernate建议我们,如果需要某个字段,可以把整个对象的所有属性都查询出来;
但这里还是要学习一下如何取出部分属性:(hql 项目中)
query = session.createQuery(“select sid,sname from Student ”);
List list = query.list();
for(int i = 0;i < list.size();i++) {
Object[]objs = (Object[]) list.get(i);
System.out.println(objs[0]+":"+objs[1]);
}
取出类的全部属性,只需修改hql语句即可,同时list中的对象是该对象
Query 的 uniqueResult()方法
如果确认查询的结果只有一条数据,使用这个方法可以增加效率
过滤重复值/between..and
- 当要过滤重复的数据时,可以使用distinct关键字:
比如,显示所有学生的性别和年龄。
session.createQuery(“select distinct sage,ssex from Student”);
如果没有加distinct 可能会出现重复的数据
加上之后,没有重复数据
- 计算年龄在20-22的学生(包含20和22)
hql = “from Student where sage between 20 and 22”;
- in 和 not in
查询计算机系和外语系的学生信息
hql = “from Student where sdept in (‘计算机系’,’外语系’)”;
group by 和 having 和分页
- group by 使用
查询各个系的学生的平均年龄
select avg(sage), sdept from Student group by sdept
- having的使用
人数大于3的系
select count(*), sdept from Student group by sdept having count(*)>3
查询女生少于200人的系
select count(*),sdept from Student group by sdept having count(*)<200 and ssex=’F’
select sage from Student where sdept=’计算机系’;
select count(*) from Student where sdept=’计算机系’ group by sdept;
如果返回的结果只有一列,那么list中的是Object而不是obj数组
查询11号课程的最高分和最低分
select max(grade), min(grade) from StudCourse where
显示各科考试不及格学生的名字,科目和分数
select count(*),course.cname from Studcourse where grade<60 group by course.cid
按照学生年龄,从小到大 取出第一个到第三个学生
from Student order by sage query.setFirstResult(0).setMaxResult(3);
参数绑定
好处:可读性提高,效率提高,防止sql注入漏洞
| session.createQuery(“from Student where sdept=:dept and sage>:age”); |
query.setParameter(“age”,30);
query.setParameter(参数名,值);
注意:如果参数是 :dept 形式,则参数绑定应该:setParameter(“dept”,xx);
如果使用 ? 形式,则参数设置应该:setParameter(0,xx);
从映射文件中得到hql语句
例子:在Student.hbm.xml 文件中,
22]]>
使用:
List list = session.getNamedQuery(“myquerytest”).list();
使用子查询
hibernate对象中存在三种关系
- 一对一
- 一对多
- 多对多
模糊查询
和sql的用法一样;from Student where sname like ’刘%’
Criteria
Criteria是一种比HQL更加面向对象的查询方式,Criteria的创建方式:
Criteria criteria = session.createCriteria(Student.class);
简单属性条件如:criteria.add(Restrictions.eq(propertyName, value));
criteria.add(Restrictions.eqProperty(propertyName,otherPropertyName));
配置
[create][update][create-drop][vaildate]
domain--映射文件(主要) --àà 数据库表
如果需要自动创建,需要配置这个属性
create:当应用程序加载hibernate.cfg.xml时自动创建表,如果原先存在,则删除再创建
update:当表不存在,创建;如果映射文件有变化,则更新(诡异);表中的数据还在;
create-drop: 在显示关闭sessionFactory时,就drop掉数据库的表
validate:相当于每次插入数据之前都会验证数据库中的表结构和hbm文件结构是否一致
many-to-one
one-to-many
cascade=”[save-updat]” 级联保存更新
one-to-one
(1)基于主键的one – to—one
IdCard的映射文件
如果没有constrained true idCard的主键将不会生成外键约束
Person的映射文件
(2)基于外键的One-to-one
IdCard的映射文件
Person的映射文件
many-to-many
多对多实际使用是转换成一对多的对象模型,转换成两个一对多
详情在eclipse –o many2many 项目
学生-课程
顾客-商品
级联操作
cascade (Employee – Department) bbs()
Cascade 用来说明当对主对象进行某种操作时是否对其关联的从对象也作类似的操作,
常见的Cascade:
none all save-update delete lock refresh evict replicate persist
merge delete-orphan(one-to-many) 。一般many-to-one,many-to-many 不设置级联,
在
- 在集合属性和普通属性中都能使用cascade
- 一般讲cascade配置在one-to-many( One 的一方,比如Employee-Department)
和one – to- one (主对象一方)
*级联操作
所谓级联操作就是说,当你进行某个操作时,另一个操作有Hibernate给你自动完成
比如:Department---Employee 但我删除一个部门的时候,那个就自动的删除属于该部门的所有员工。
lazy 和 fetch的配置
1、当lazy="true" fetch = "select" 的时候 , 这个时候是使用了延迟策略,开始只查询出一端实体,多端的不会查询,只有当用到的时候才会发出sql语句去查询 ;
2、当lazy="false" fetch = "select" 的时候 , 这个时候是使没有用延迟策略,同时查询出一端和多端,同时产生1+n条sql.
3、当lazy="true"/lazy="false" fetch = "join"的时候,自己认为这个时候延迟已经没有什么用了,因为采用的是外连接查询,同时把一端和多端都查询出来了,延迟没有起作用。
这里配置lazy=’false’ 使用Load时候,返回的domain对象已经查询好了数据
相当于使用get方法
如果没有配置,使用load方法加载一个雇员时,返回的是domain的代理对象,
并没有查询出结果,当要使用该对象的属性时,才去数据库查询
主键增长策略
- increment 自增长
- indentity db2,mysql, sql server, 内置标识字段提供支持,自增,返回的标识符是long,short,或者int类型
- sequence db2,oracle, 使用序列,long , short, int
- hilo 使用一个高低位算法生成Long,short,int,
hilo标识符生成器由hibernate按照一种high/low 算法生成标识符,他从数据库中特定表的字段中获取High值,因此不依赖于底层数据库,OID类型是数字类型
配置文件:
my_hi_value
next_value
- native
可以根据底层数据库的类型,自动选择合适的标识符生成器,(identity,hilo,sequence)中的一种,返回的ID类型是 long,short,int
- assigned 自己指定ID
- uuid
- foreign
对象状态
瞬时:Transient
数据库中没有数据与之对应,超过作用域会被jvm垃圾回收器回收,一般是New出来且与session没有关联的对象
持久:Persistent
数据库中有数据与之对应,当前与session有关连;并且相关联的session没有关闭,事务没有提交;持久对象状态发生改变,在事务提交时会影响到数据库(hibernate能检测到)
脱管/游离:Detached
数据库中有数据与之对应,但当前没有session与之关联;托管对象状态发生改变,Hibernate无法检测到
| Transient |
new
| garbage |
save()
saveOrUpdate() delete()
| Persistent |
| 回收 |
evict() update
close saveOrUpdate
clear lock
| Detached |
| garbage |
判断一个对象处于那种状态,主要的依据是:看该对象是否处于session管理
看数据库中有没有对应的记录
缓存
缓存的作用:主要用于提高性能,可以简单的理解成一个Map,使用缓存涉及到三个操作:把数据放入缓存,从缓存中获取数据,删除缓存中无效数据。
一级缓存:Session级缓存
save,update,saveOrUpdate,load,get,list,iterate,lock这些方法都会将对象放在一级缓存中,一级缓存不能控制缓存的数量,所以要注意大批量操作数据时可能造成的内存溢出;可以用 evict,clear方法清除缓存中的内容。
- 什么操作会向一级缓存中存入数据
save,update,saveOrUpdate,load,get,list,iterate,lock
- 什么操作会向一级缓存中存取数据
List()不会 uniqueResult()不会
get/load会
注意:一级缓存不能控制缓存的数量,注意使用;
可以通过clear 和 evict 手动清除;
session缓存会随着session的关闭而消亡;
二级缓存:SessionFactory级缓存
由于一级缓存的有限(生命周期很短),所以我们需要二级缓存
| DB |
| 查询 |
| 一级缓存 |
| 二级缓存 |
先在1级缓存查询,
没找到就去2级查询;
2级没有,到数据库查询,
查到之后放入2级缓存,在放入1级缓存;
使用二级缓存:
- 配置
|
|
| 二级缓存提供商 |
hibernate.generate_statistics true 启用统计工具,计算命中率
Statistics statistics = sessionFactory.getStatistics();//得到一个统计对象
可以查看命中率高不高???
xx.hbm.xml中配置cache
class-cache 指定那个对象需要缓存
usage=”read-write”:二级缓存策略
*read-only 只读
*read-write 读写
*nonstrict-read-write不严格读写缓存
*transactional 事务缓存
注意:hibernate.cache.provider_class 在hibernate4.0之后不建议使用
可以用 : hibernate.cache.region.factory_class
org.hibernate.cache.ehcache.EhCacheRegionFactory
- 引入jar包
- 复制ehcache.xml文件到src目录
二级缓存是交给第三方处理,常见的有
Hashtable OSCache EHCache
Eclipse使用Hibernate tools
- 进入 http://jboss.org/tools/download/stable/3_1_GA.thml
选择jbsstool …下载
- 下载完ok了
- 创建一个web项目
- 引入数据库连接的包和hibernate的包
- 创建 hibernate.cfg.xml文件
- 创建 控制台
- 添加hibernate控制台配置
右键项目-New-other,搜索hibernate,选择Hibernate Console Configuration,点击Next,如下:
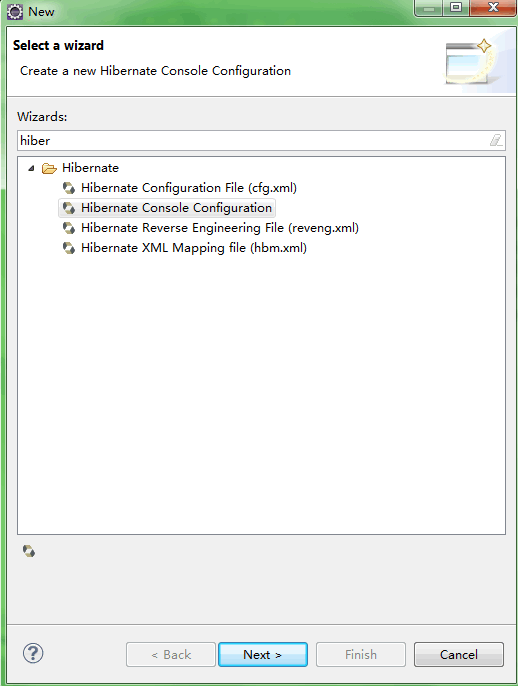
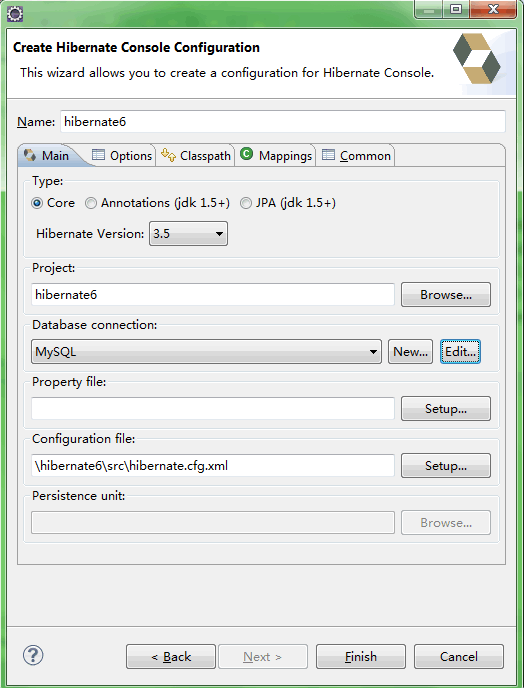
在Name中指定该hibernate console configuration的名称,在Project中选择项目,在Database Connection中选择前面配置的数据库连接,在Configuration file中选择前面自动生成的hibernate.cfg.xml文件,点击Finish,如下:
3.自动生成hibernate.reveng.xml文件
右键项目-New-other,搜索hibernate,选择Hibernate Reverse Engineering File,点击Next,如下:
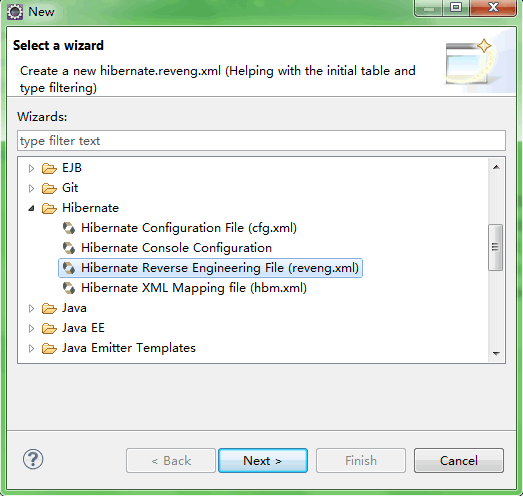
在Console configuration中选择上一步配置的名字(即hibernate console configuration中输入的Name),点击Refresh刷新出前面连接的数据库中的全部Schema,点击Include会将指定的数据库或表添加到Table filters中,这里我们不过滤任何表,如下:

点击Finish,在项目下会有一个hibernate.reveng.xml文件,打开该文件,点击Table&Columns标签页,点击Add,选择刚才配置的hibernate console configuration的名称,点击OK,选择要映射的表,如下:

4.自动生成*.hbm.xml文件
点击Run-Hibernate Code Generation-Hibernate Code Genration Configurations,如下:

Main标签页中,在Console configuration中选择前面的hibernate console configuration中配置的名称,在Output directory中选择自动生成的domain类放置的位置,这里我们需要事先在src目录下建一个包(com.kevin.domain)用来存放domain类,勾选Reverse engineer from JDBC Connection,在reveng.xml中选择刚才自动生成的hibernate.reveng.xml文件,如下:
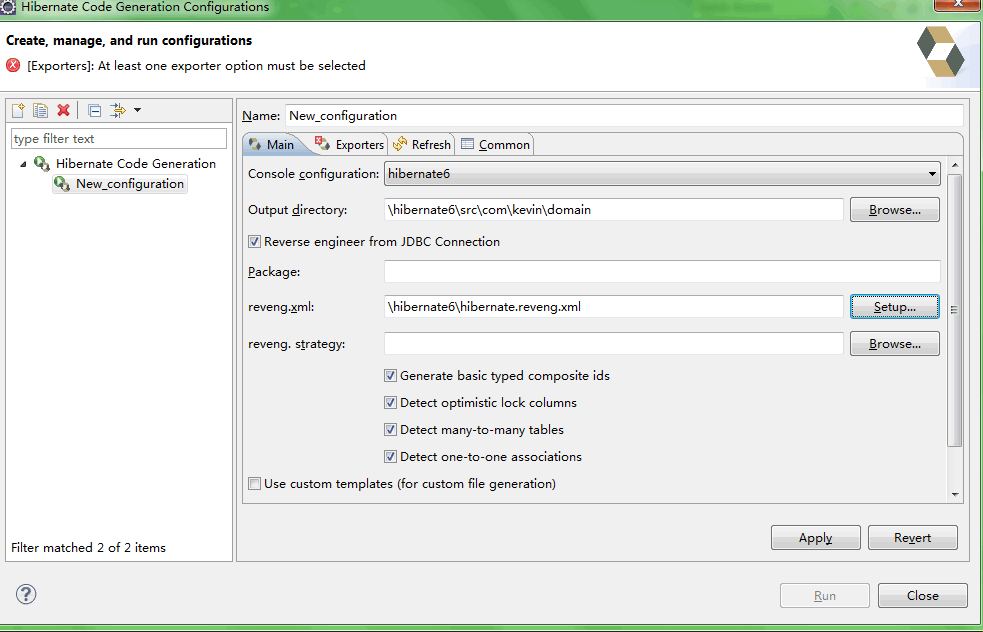
Exporters标签页中,勾选Domain code(.java)和Hibernate XML Mappings(.hbm.xml),如下:
点击Run,在指定目录下就可以看到自动生成的domain类和*.hbm.xml文件了,如下:
注:
由于此时没有自动更新hibernate.cfg.xml文件,因此我们需要手动在其中添加需要管理的对象关系映射文件,如下:
异常
NoInitialContextException
javax.naming.NoInitialContextException: Need to specify class name in environment or system property, or as an applet parameter, or in an application resource file:
解决方案:去除sessionFactory标签的Name属性
TypeMismatchException
org.hibernate.TypeMismatchException: Provided id of the wrong type for class com.domain.Student. Expected: class java.lang.Integer, got class java.lang.String
解决方案:仔细核查get()或者Load方法中的参数类型是否错误???
DocumentException(没网络不能用hibernate问题)
org.dom4j.DocumentException: www.hibernate.org Nested exception: www.hibernate.org
解决方案:见hibernate.cfg.xml的头该成下面那样:
|
"-//Hibernate/Hibernate Configuration DTD 3.0//EN" "http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd"> |
org/apache/commons/logging/LogFactory
要引包:log4j-1.2.11.jar
org.hibernate.exception.SQLGrammarException: could not execute query
映射文件属性配置错误
懒加载问题
org.hibernate.LazyInitializationException - could not initialize proxy - no Session
当我们查询一个对象的时候,返回的只是该对象的普通属性(默认情况)
当用户去使用对象属性时,才会向数据库发出再一次的查询语句
这种现象:Lazy
hibernate中不使用懒加载时,不要在One-to-many中去配,
可以在many 那一方去配置lazy=’false’
Employee—department例子中
如下配置(不推荐):
查询department时,关联的employee 的集合也会查询好
查询employee时候,其关联的department也会被查询
解决方案:
- Hibernate.initialize(代理对象); 需要使用的未加载对象
- 在department映射文件中加入 lazy=’false’,关闭懒加载
- openinsessionview解决(通过过滤器)
opensessionView详解:
doFilter方法中:
Session session = null;
Transaction transaction = null;
try {
session = MySessionFactory.getSessionFactory().getCurrentSession();
transaction = session.beginTransaction();
chain.doFilter(request, response);//业务
transaction.commit();
} catch(Exception e) {
e.printStackTrace();
if(transaction!=null)transaction.rollback();
throw new RuntimeException(e.getMessage());
} finally {
if(session!=null&&session.isOpen())
session.close();//这里关闭session,
}
然后配合 只使用currSession和不关闭session的hibernate工具类
处理懒加载问题(只限于web项目中)
Hibernate使用的场景
不适合OLAP(on-line-Analytical processiong 联机分析处理),以查询分析数据为主的系统
适用于 OLTP (On-line transaction processing) 联机事务处理