Shell知识点集合
cat /etc/shells //显示系统所有解释器
yum -y install ksh //安装新的解释器
vim /etc/profile //设置历史命令存储条数
cat /root/.bash_history //历史命令保存文件
history -c //清除历史命令
编写shell规范
- 声明解释器 #!/bin/bash
- 脚本功能注释
- 脚本内容,要执行的指令
脚本执行方式
- 添加x权限
- 使用bash之类的解释器读取脚本文件,比如bash test.sh
- 使用source命令读取脚 本文件 source test.sh ,source可以省略为.
bash first.sh //开启子进程
sh first.sh //开启子进程
source first.sh //不开启子进程
可以使用下面的脚本验证bash跟source的区别
#!/bin/bash
mkdir /opt/123
cd /opt/123
案例一,搭建yum,搭建ftp服务
#!/bin/bash
rm -rf /etc/yum.repos.d/*.repo
echo '[rhel7]
name=yum
baseurl=ftp://172.25.254.250/rhel7
enabled=1
gpgcheck=0 ' > /etc/yum.repos.d/yum.repo
yum -y install vsftpd &> /dev/null
systemctl restart vsftpd
systemctl enable vsftpd &> /dev/null
环境变量:PWD当前位置、USER当前用户、HOME当前用户家目录、SHELL当前用户的解释器,HOSTNAME主机名,UID当前用户的UID,PATH系统命令所在地,PS1一级提示符,PS2二级提示符
$0 当前的解释器
$$ 当前程序的进程号
$? 上条指令的执行结果,0是正确,非0是错误
$# 统计位置变量的个数
$* 显示所有位置变量的值
$- 显示Shell使用的当前选项,与set命令功能相同。
$! 后台运行的最后一个进程的ID号
$@ 与$*相同,但是使用时加引号,并在引号中返回每个参数。
如"$@“用「”」括起来的情况、以"$1" “$2” … “$n” 的形式输出所有参数。
$*就是把所有输入的参数一次输出,是一个整体,$@就是分开输出每个输入的参数
env,查看所有的系统环境变量
使用set可查看所有变量(包括env能看到的环境变量)
unset +变量名 取消变量定义
单引号:用来界定范围,可以取消特殊字符的意义
双引号:用来界定范围
反撇号``,等同于$(),将命令的执行输出作为变量值
stty -echo关闭回显
stty echo 恢复
#!/bin/bash
read -p "请输入您要创建的用户名:" user
useradd $user &>> /opt/user.txt
stty -echo
read -p "请设置登录密码:" pw
stty echo
echo $pw | passwd --stdin $user >&2 &>> /opt/user.txt
export b=100将b定义为全局变量,在其他进程中也可以访问
expr 43 + 21 计算指定的表达式并输出结果
expr $b + 21
加,减,乘,除,取余 + ,-,*,/,%,乘号必须加反斜杠转义
expr $x \* 78
echo $[$x*78] //这个不需要转义
echo $[$x % 78]
中括号里边的变量也可以不加$,即echo $[x%78]
let对变量值做运算再保存新的值
let x++或者let x+=1 让变量x加1,修改变量x的值
如果指令不写let,只写x+=1,则表达的意思是变量x所代表的值后面加1,即,如果x=100则x+=1就为1001
直接打bc,进入交互式小数运算环境
echo 'scale=4;12.34+5.63' | bc 非交互式小数计算,scale=4,表示的是保留多少位小数
x=$(echo "scale=10;6.2/5.3" | bc) //给变量x赋值计算后的结果
echo 'scale=1;'$c'/0.1' | bc //带入变量c的值进行计算
test $USER == eee && test $USER == root //test测试
-z 检查变量的值是否未设置(空值)
[ -z "$var1" ] && echo "空值" || echo "非空值"
[ ! -z "$var1" ] && echo "非空值" || echo "空值"
ping -c 3 -i 0.2 -W 1 127.0.0.1 //为了节省ping测试时间,可以只发送3个测试包(-c 3)、缩短发送测试包的间隔秒数(-i 0.2)、等待反馈的超时秒数(-W 1)。
-z 判断 变量的值,是否为空; zero = 0
- 变量的值,为空,返回0,为true
- 变量的值,非空,返回1,为false
-n 判断变量的值,是否为空 name = 名字
- 变量的值,为空,返回1,为false
- 变量的值,非空,返回0,为true
for循环
(1)
#!/bin/bash
for i in $(seq 2 10);
do
echo $i ;
done
(2)
for ((i=10;i<=20;i++));
do
echo $i ;
done
(3)
for num in `seq 50` //打印1~50
do
echo This is $num
done
(4)
for num in {20..30}
do
echo Result $(expr $num \* 3 + 1)
done
(5)
list="rootfs usr data data2"
for i in $list;
do
echo $i is appoint ;
done
(6)循环ping 172.25.0.0网段
#!/bin/bash
for ip in `seq 254`
do
IP=172.25.0.$ip
ping -c 3 -i 0.2 -W 1 $IP > /dev/null
if [ $? -eq 0 ];then
echo $IP 通了
else
echo $IP 不通
fi
done
While语句
//猜数
#!/bin/bash
N=$[RANDOM%101]
c=0
while true
do
read -p "请猜数字:" num
let c++
expr $num + 6 &> /dev/null
if [ $? -ne 0 ] || [ -z "$num" ];then
echo 必须输入数字
else
if [ $N -eq $num ];then
echo 你猜了$c次,牛逼,猜对了,Bye\!
exit
elif [ $N -gt $num ];then
echo 不对,猜小了
elif [ $N -lt $num ];then
echo 不对,猜大了
fi
fi
done
case语句的用法
#!/bin/bash
case $1 in
redhat)
echo "fedora";;
fedora)
echo "redhat";;
*)
echo "用法:$0{redhat|fedora}"
esac
定义函数:
[root@svr5 ~]# mycd(){ //定义函数
> mkdir /test
> cd /test
> }
[root@svr5 ~]# mycd //调用函数
type mycd 检查该函数
//ping地址
#!/bin/bash
myping(){
ping -c1 -W1 $1 &>/dev/null
if [ $? -eq 0 ];then
echo "$1 is up"
else
echo "$1 is down"
fi
}
for i in {1..254}
do
myping 192.168.4.$i &
done
wait
#wait命令的作用是等待所有后台进程都结束才结束脚本。
或者
function myping {//函数名后面要有空格
}
shell脚本定义的变量,默认为全局变量,作用域为整个shell脚本,要是想让某个变量只能在方法或者模块内部被访问,外界访问不到,需要在变量名前面加local(local只能在函数中使用)
echo -e "\033[32mABC\033[0m" //颜色输出的命令,3X为字体颜色,4X为背景颜色,其中\033[为固定格式,0m为还原系统颜色
(1)定义一个函数,打印色值
#!/bin/bash
cecho(){
echo -e "\033[$1m$2\033[0m"
}
for i in `seq 255`
do
echo 色值$i
cecho $i ABCDEFYYYYYYPPPPP
done
(2)ping ip地址,ping的结果采用彩色打印
#!/bin/bash
tl=0
bt=0
cecho(){
echo -e "\033[$1m$2\033[0m"
}
for ip in `seq 15`
do
IP=172.25.0.$ip
ping -c 3 -i 0.2 -W 1 $IP > /dev/null
if [ $? -eq 0 ];then
cecho 32 $IP通了
let tl+=1
else
cecho 31 $IP不通
let bt+=1
fi
done
echo 不通$bt
echo 通了$tl
(3)fork炸弹
#!/bin/bash
.(){
.|.&
}
.
break可以结束整个循环;continue结束本次循环,进入下一次循环;exit结束整个脚本
//求和
#!/bin/bash
SUM=0
while :
do
read -p "Input a num(0 is over):" num
[ $num -eq 0 ]&& break
let SUM+=$num
done
echo The result is $SUM
//求1~20之类6的倍数,并算平方和
#!/bin/bash
for i in `seq 20`
do
[ $[i % 6] -ne 0 ] && continue
expr $i \* $i
done
//石头剪刀布
#!/bin/bash
game=(石头 剪刀 布)
index=$[RANDOM%3]
computer=${game[$index]}
echo "请根据下列提示,选择您出拳的手势"
echo "1.石头"
echo "2.剪刀"
echo "3.布"
read -p "请选择1-3:" person
case $person in
1)
if [ $index -eq 0 ];then
echo "平局"
elif [ $index -eq 2 ];then
echo "你赢了"
else
echo "计算机赢了"
fi;;
2)
if [ $index -eq 0 ];then
echo "计算机赢了"
elif [ $index -eq 1 ];then
echo "平局"
else
echo "你赢了"
fi;;
3)
if [ $index -eq 0 ];then
echo "你赢了"
elif [ $index -eq 1 ];then
echo "计算机赢了"
else
echo "平局"
fi;;
*)
echo "必须输入1-3之间的数字"
esac
echo 电脑是$computer
字符串操作
string=“woo is a great”
(1)字符截取
echo ${#string} #统计字符串长度
echo ${string:1:4}#从字符串下标1开始,截取4个字符,字符串的下标从0开始计数,0可以不写,即${string::4}表示从下标0即第一个字符开始往后截取4个字符
expr substr "$string" 1 3#从第一个字符开始,往后截取三个字符长度
echo $string | cut -b 1-3 #从第一个字符开始,往后截取三个字符长度
expr index "$string" io#查找i或者o的位置,哪个字母先出现,计算的
哪个,这个计算的下标是第几个位置,下标从1开始
echo $string | cut -b 3-从第三个字符开始,截取到最后
echo $string | cut -b -5从第一个开始截取到第五个字符
echo $string | cut -b 3 只截取第三个字符
echo $string | cut -b 3,5,8 只截取第3,5,8个字符
案例:打印一个八位的随机密码
#!/bin/bash
pass=''
x=abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789
for i in `seq 8`
do
tmp=$[RANDOM%62]
pass=${pass}${x:tmp:1}
done
echo $pass
(2)字符替换
phone=13356891346
echo ${phone/3/x} 将匹配到的第一个3替换成x
echo ${phone//3/x} 将匹配到的所有的3都替换成x
(3)字符串掐头去尾
A=head -1 /etc/passwd // root❌0:0:root:/root:/bin/bash
echo ${A#root} //从左往右 删除第一个root
echo ${A#root:} //从左往右 删除第一个root:
echo ${A##*root}//从左往右 删除最右边的root左边的所有字符(*通配符)
echo ${A%:*} //从右往左,删除第一个冒号右边所有的字符
echo ${A%%:*} //从右往左,删除最左边的最后一个冒号的右边的所有字符
案例:批量修改文件扩展名
#!/bin/bash
1)if [ -f /opt/abc1.txt ];then
for i in `ls /opt/*.txt`
do
# mv $i ${i/txt/doc}
mv $i ${i%.*}.doc
done
else
for i in `ls /opt/*.doc`
do
mv $i ${i%.*}.txt
done
fi
2)
#!/bin/bash
for i in `ls /opt/*.$1`
do
mv $i ${i%.*}.$2
done
(4)字符串的初值的处理
echo ${ss:-123} //当变量ss没有初始化值时会打印123,如果有初始化的值,则会打印初始化的值
案例:创建用户,要求没有输入用户名则直接退出,没有输入密码,默认采用123456
#!/bin/bash
read -p "请输入创建的用户名:" user
[ -z "$user" ] && exit
id $user &> /dev/null
[ $? -eq 0 ]&& exit
read -p "请输入登录密码:" -s pass
pass=${pass:-123456}
useradd $user
echo -e "\n登录密码为:$pass"
echo $pass | passwd --stdin $user
定义数组
array_name=(value1 value2 value3 value4 value5 value6)
#根据数组下标获取某一元素的值
echo ${array_name[0]}
echo ${array_name[1]}
echo ${array_name[2]}
echo ${array_name[3]}
#修改某一下标对应的值
array_name[3]=hahaha
echo ${array_name[3]}
#使用@打印数组所有元素
echo ${array_name[@]}
#获取数组长度
echo ${#array_name[@]} #或者${array_name[*]}
#获取数组单个元素的长度
echo ${#array_name[1]}
多行注释
多行注释还可以使用以下格式:
:<
注释内容…
注释内容…
EOF
EOF 也可以使用其他符号:
:<<’
注释内容…
注释内容…
注释内容…
’
:< 注释内容…
注释内容…
注释内容…
!
a=10
b=20
-o 或运算,有一个表达式为 true 则返回 true,等同于[[ $a -lt 100 || $b -gt 100 ]] 。-a 与运算,两个表达式都为 true 才返回 true,等同于[[ $a -lt 100 && $b -gt 100 ]] 。
if [ $a -lt 20 -a $b -gt 100 ];then
echo ‘true’
else
echo ‘false’
fi
read
-p 输入提示文字
-n 输入字符长度限制(达到6位,自动结束)
-t 输入限时
-s 隐藏输入内容
read -p "请输入一段文字:" -n 6 -t 5 -s password
echo -e "\npassword is $password" //-e是开启转义
expect预期交互
expect可以为交互式过程(比如FTP、SSH等登录过程)自动输送预先准备的文本或指令,而无需人工干预。触发的依据是预期会出现的特征提示文本。
yum -y install expect
#!/bin/bash
expect << EOF
spawn ssh -o StrictHostKeyChecking=no 172.25.0.10 //加-o StrictHostKeyChecking=no是避免第一次登录时显示让输入yes/no
expect "password:" { send "redhat\r" }
expect "#" { send "touch /tmp.txt\r" }
expect "#" { send "exit\r" }
EOF
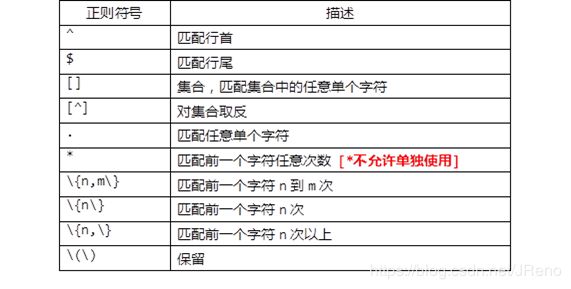
正则表达式:
基本正则
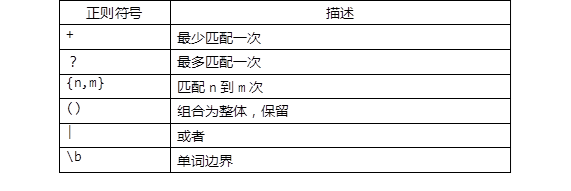
扩展正则
一,基本正则列表
grep "^t" /opt/t.txt以t开头的行grep "t$" /opt/t.txt以t结尾的行grep "[c]" /opt/t.txt包含集合字符的行grep "[c,a]" /opt/t.txt或者grep "[ca]" /opt/t.txt包含c或者a的行grep "[^ca]" /opt/t.txt对集合取反,搜索文本中含有字母c/a之外的行grep "root." /etc/passwd以点(.)匹配任意单个字符grep "root*" /etc/passwd匹配前面字符(root)字符的任意次数grep "t*" /etc/passwd匹配t出现的任意次数,0次也行grep ".*" /etc/passwd匹配任意字符的行grep "o\{1,2\}" /etc/passwd匹配连续出现1-2次o的行grep "r\{2\}" /etc/passwd匹配连续出现2次r的行grep "0\{3,\}" /etc/passwd匹配连续出现3次及以上0的行grep -q '^172.25.254.254' /etc/hosts && echo "YES" || echo "NO"// 匹配/etc/hosts 文件中是否存在172.25.254.254的映射记录,-q(quite)的作用是屏蔽掉检索输出egrep -m10 "/sbin/nologin$" /etc/passwd//仅在前10行里面匹配以/sbin/nologin结尾的行egrep -m10 -c "/sbin/nologin$" /etc/passwd//-c表示输出匹配的行数,同wc -l
二,扩展正则列表
grep -E或者egrep匹配扩展正则grep -E "ro{2,}" /etc/passwd//匹配出现两次及以上的ro的行egrep "ro{1,2}" /etc/passwd//匹配出现1-2次ro的行egrep "ro{1}" /etc/passwd//匹配只出现一次ro的行egrep "^(root|daemon)" /etc/passwd//匹配以root或者daemon开头的行egrep "f+" /etc/passwd//匹配f至少出现一次的行egrep 'init(ial)?' /etc/rc.local// 输出包括init、initial的行,即末尾的“ial”最多出现一次(可能没有)egrep "^root.*bash$" /etc/passwd//匹配以root开头,bash结尾的行egrep "[A-Z]" /etc/passwd//匹配包含大写字母的行egrep "[^a-z]" /etc/passwd//过滤非小写字母的其他字符egrep '\bbin\b' /etc/passwd或者egrep '\//输出包含bin单词的行,sbin不符合条件
sed(流式编辑器)工具基本用法
p 输出
d 删除
s 替换
- 非交互,基于模式匹配过滤及修改文本
- 逐行处理,并将结果输出到屏幕
- 可实现对文本的输出,删除,替换,复制,剪切,导入,导出等操作
sed命令的常用选项如下:
-n(屏蔽默认输出,默认sed会输出读取文档的全部内容)
-r(让sed支持扩展正则)
-i(sed直接修改源文件,默认sed只是通过内存临时修改文件,源文件无影响)
sed -n 'p' /opt/sed.txt//屏蔽默认输出,字母p是逐行输出sed -n '1p' /opt/sed.txt//输出文本第一行的内容sed -n '3,5p' /opt/sed.txt//输出文本3~5行sed -n '3p;5p' /opt/sed.txt//输出文本第3行和第5行sed -n "2,+2p" /opt/sed.txt//打印第2以及后面的2行:sed -n "1~2p" /opt/sed.txt//打印奇数行,即从第一行开始,每隔两行打一次sed -n "2~2p" /opt/sed.txt//打印偶数行,即从第二行开始,每隔两行打一次head -5 /etc/passwd | sed -n "2p;4p"//先设置前置命令sed -n "/ro\{1,\}/p" /etc/passwd//基本正则,正则表达式写在两个/之间sed -n -r "/ro{1,}/p" /etc/passwd//加-r,支持扩展正则表达式
以上指令p换乘d执行删除指令
sed -n "$=" /etc/passwd//打印最后一行的行号,即可以知道文件总行数sed -n "/root/=" /etc/passwd//输出包含root的行的行号sed '$d' /opt/sed.txt//删除文本最后一行sed '/^$/d' /opt/sed.txt//删除所有的空行sed '/xml/!d' a.txt//删除不包含xml的行,!符号表示取反sed -i -n '/nologin/p' /opt/password//将满足条件的输出行写入到文本文件中,原先的内容被替换sed -i '/bash$/!d' /opt/passwd//只保留文件中以bash结尾的行,或者sed -i -n '/bash$/p' /opt/passwd也可以
sed替换(s)
-
sed 's/2017/aaa/' /opt/sed_s.txt//逐行执行,将每行的第一个2017替换成aaa -
sed 's/2017/aaa/g' /opt/sed_s.txt//将文本中所有的2017替换成aaa -
sed '1s/2017/aaa/g' /opt/sed_s.txt//将文本中第一行的2017替换成aaa -
sed '1,2s/2017/aaa/g' /opt/sed_s.txt//将文本中第1~2行中的2017都替换成aaa -
sed '2,+1s/2017/aaa/2' /opt/sed_s.txt//将文本中的2行开始,到后面+1行,第二个2017替换成aaa -
sed -n 's/root/XXXX/p' /opt/passwd//将文本中的每行的第一个root替换成XXXX并且只输出替换行 -
sed -n 's/^root/XXXX/p' /opt/passwd//替换以root开头的行 -
sed -n 's/\/bin\/bash/\/bin\/sh/p' /opt/sed.txt//将/bin/bash换成/bin/sh 不是/意义的,要加\转义 -
sed -n 's#/bin/bash#/bin/sh#p' /opt/sed.txt//为了避免/与本身替换的内容中所带的/产生冲突,原先的/可以用! @ # $ % ^ & * () 替换,这些就是数字键盘上的随便哪个字符都可以 -
sed '4,7s/^/#/' /opt/sed.txt//在4~7行的行首加#,相当于注释 -
sed '4,7s/^#//' /opt/sed.txt//去注释 -
sed 's/.//2;s/.$//' /opt/nssw.txt//删除每行的第二个字符跟最后一个字符 -
sed -r 's/^(.)(.*)(.)$/\3\2\1/' /opt/nssw.txt//将文件中每行的第一个、倒数第1个字符互换,每行文本拆分为“第1个字符”、“中间的所有字符”、“倒数第1个字符”三个部分,然后通过替换操作重排顺序为“3-2-1”,这个可以选择是否显示哪一段,如 -
sed -r 's/^(.)(.*)(.)$/\3\2/' /opt/nssw.txt只显示3跟2段 -
sed -r 's/^(.)(.)(.*)(.)$/\1\3/' /opt/nssw.txt//删除每行的第二个字符跟最后一个字符,原理就是将每一行拆分成4段,选择要显示哪一段以及在哪个位置显示 -
sed 's/[0-9]//g' /opt/nssw.txt//删除文本当中的所有的数字 -
sed -r 's/[0-9]//g;s/^ +//' /opt/nssw.txt//删除文本中的数字以及每一行开头的空格 -
sed -r 's/([A-Z])/[\1]/g' /opt/nssw.txt//将文本中所有的大写字母都加上中括号[]
案例
本案例要求熟悉课上的sed应用案例,并编写脚本anonftp.sh,实现以下功能:
通过yum安装vsftpd软件包
修改vsftpd服务配置,开启匿名上传
调整/var/ftp/pub目录权限,允许写入
启动vsftpd服务,并设置开机自运行
#!/bin/bash
yum -y install vsftpd
cp /etc/vsftpd/vsftpd.conf
sed -r -i 's/^#anon/anon/' /etc/vsftpd/vsftpd.conf
chmod 777 /var/ftp/pub
systemctl restart vsftpd
systemctl enable vsftpd
sed多行文本处理
sed 'a abc' /opt/nssw.txt//在每一行的后面都追加一行abcsed '2a abc' /opt/nssw.txt//在第二行后面重起一行,插入abcsed '2i abc' /opt/nssw.txt//在第二行前面重起一行,插入abcsed '3c abc' /opt/nssw.txt//将第三行替换成abcsed '$a abc' /opt/nssw.txt//在最后一行插入一行abc
综合案例
本案例要求编写脚本getupwd.sh,实现以下需求:
找到使用bash作登录Shell的本地用户
列出这些用户的shadow密码记录
按每行“用户名 --> 密码记录”保存到getupwd.log
#!/bin/bash
if [ -f /opt/getupwd.log ];then
rm -rf /opt/getupwd.log
fi
for usr in $(sed -n '/bash$/s/:.*//p' /etc/passwd)
do
userinfo=`sed -n "/$usr/p" /etc/shadow`
tmp1=${userinfo#*:}
tmp2=${tmp1%%:*}
storeStr="$usr --> $tmp2"
echo $storeStr >> /opt/getupwd.log
done
sed [选项] ‘条件指令’ 文件
选项:
-n 屏蔽默认输出
-r 支持扩展正则
-i 修改源文件
条件:
行号 4 4,5 4~2 4,+10
/正则/
指令:
p 打印
d 删除
s 替换s/旧/新/g
a 追加
i 插入
c 替换行
sed的文件导入导出
基本动作
r动作应结合-i选项才会存入
w动作以覆盖的方式另存为新文件
-
sed '2r /opt/sed.txt' /opt/nssw.txt//在第二行下边插入sed.txt中的内容 -
sed '1,3r /opt/sed.txt' /opt/nssw.txt//在1~3行,每一行下边都插入sed.txt的内容 -
sed '1,+3r /opt/sed.txt' /opt/nssw.txt//从第一行开始,后面3行,每一行后面都插入sed.txt的内容 -
sed '1~2r /opt/sed.txt' /opt/nssw.txt//每个奇数行后面都插入sed.txt的内容 -
sed '/^H/r /opt/sed.txt' /opt/nssw.txt//在以H开头的行后面插入sed.txt -
sed -n '1,2w /opt/sed.txt' /opt/nssw.txt//将nssw.txt的前1~2行导入到sed.txt(覆盖方式) -
sed -n '/^H/w /opt/sed.txt' /opt/nssw.txt//将nssw.txt中,以H开头的行,覆盖到sed.txt文件中
sed复制剪切
模式空间
- 存放当前处理的行,将处理的结果输出
- 若当前行不符合处理条件,则原样输出
- 处理完当前行再都入下一行来处理
保持空间 - 作用类似于“剪切板”
- 默认存放下一个空行(换行符\n)
基本动作
- 复制
- H:模式空间–[追加]–>保持空间
- h:模式空间–[覆盖]–>保持空间
- 粘贴
-
G:保持空间–[追加]–>模式空间
-
g:保持空间–[覆盖]–>模式空间
-
sed '1h;2H;$G' /opt/nssw.txt//把1~2行复制到文件末尾,并且中间没有空行 -
sed '1H;2H;$G' /opt/nssw.txt//把1~2行复制到文件末尾,中间有空行 -
sed '1h;2,3H;$G' /opt/nssw.txt//把1~3行复制到文件末尾,并且中间没有空行 -
sed '1h;2H;$g' /opt/nssw.txt//把1~2行覆盖到文件末尾 -
sed '1h;1d;$G' /opt/nssw.txt//把第一行剪切到文件末尾 -
sed '1h;2H;1,2d;$G' /opt/nssw.txt//把1~2行剪切到文件末尾,原理是,先复制1~2行,然后再把1~2行删除,然后再粘贴
awk用法
-
awk '{print $1,$2}' /opt/nssw.txt// 打印nssw.txt中第一列跟第二列的值,默认以空格或者tab键分割 -
df -h | awk '{print $4}'//打印磁盘剩余空间 -
awk -F: '{print $1}' /etc/passwd以:分割文档,打印第一列 -
awk -F[:/] '{print $1}' /etc/passwd以:或者/分割文档,打印第一列 -
awk '{print $0}' /etc/passwd打印所有内容 -
awk '{print $0,$1}' /etc/passwd打印所有内容和第一列,加,(逗号)就是表示打印内容中间用空格隔开 -
awk '{print NR}' /etc/passwd打印文件行号 -
awk '{print NF}' /etc/passwd打印当前行的列数(有几列) -
uptime | awk '{print $NF}'//打印最后一列 -
awk '{pring $1,"a"}' /etc/passwd//打印文件的第一列,加上常量a -
ifconfig eth0 | egrep "RX p|TX p" | awk '{print $5}'//打印网卡接收与发送的流量 -
df -h | awk '/\/$/{print $4}'//打印根分区磁盘剩余空间 -
awk '/Failed/{print $11}' /var/log/secure//在系统安全日志中筛选访问系统失败的ip
1. awk处理的时机
awk会逐行处理文本,支持在处理第一行之前做一些准备工作,以及在处理完最后一行之后做一些总结性质的工作。
awk [选项] ' BEGIN{指令} {指令} END{指令}' 文件 -
awk 'BEGIN{print 2.2+3.3}{print $1}END{print"test"}' /opt/test.txt//在执行打印文本第一列之前,先执行BEGIN里边2.2+3.3任务,执行完文本任务之后,执行END里边的任务 -
awk -F: 'BEGIN{print "User\tUID\tHome"}{print $1 "\t" $3 "\t" $6}END{print "总计",NR ,"行"}' /etc/passwd//按一定格式输出passwd,并统计输出的行数 -
awk -F: '/^(root|adm)/{print $1,$3}' /etc/passwd -
awk '$1~/root/' /etc/passwd//匹配第一列,包含root的行 -
awk '$1!~/root/' /etc/passwd//匹配第一列,不包含root的行 -
awk '!/root/{print}'//匹配不包含root的行 -
awk '$1=="root"' /etc/passwd//打印第一列是root的行 -
awk 'NR==2{print}' /etc/passwd//打印第二行 -
awk -F: '$3>=1000{print $1,$3}' /etc/passwd//打印第三列大于等于1000的行的第一列跟第三列 -
awk 'BEGIN{x=8;print x+=2}' -
awk 'BEGIN{x=8;x--;print x}' -
seq 200 | awk '$1%3==0'//找200以内3的倍数 -
awk -F: '$3>10 && $3<20' /etc/passwd -
awk -F: '$3>1000 || $3<10' /etc/passwd -
awk '{printf "%-8s %-10s\n",$1,$4}' /opt/log.txt//分别在输出第一列和第二列之后,加上8个空格和10个空格并换行 -
awk 'BEGIN{IGNORECASE=1}/this/' /opt/log.txt//忽略大小写,匹配包含this的行
案例
编写脚本的任务要求如下:
分析出使用bash作登录Shell的本地用户
列出这些用户的shadow密码记录
按每行“用户名 – 密码记录”保存结果
#!/bin/bash
A=`awk -F: '/bash$/{print $1}' /etc/passwd`
for i in $A
do
(1)grep ^$i: /etc/shadow | awk -F: '{print $1" --> "$2}'
(2)awk -F: -v x=$i '$1==x{print $1" --> "$2}' /etc/passwd //-v,传递外部变量
done
awk数组
-
awk 'BEGIN{a[0]=1;a[1]=2;a[2]=3;for(i in a){print i,a[i]}}'//循环的i是数组下标 -
awk '{ip[$1]++}END{for(i in ip){print i,ip[i]}}' ip.txt//统计文档中相同ip出现的次数 -
awk '/Failed/{ip[$11]++}END{for(i in ip){print i,ip[i]}}' /var/log/secure//统计安全日志中,访问本机失败的ip以及次数 -
awk '{ip[$1]++}END{for(i in ip){print i,ip[i]}}' /var/log/httpd/access_log//统计http日志中,访问本机web页面的ip以及次数
针对文本排序输出可以采用sort命令,相关的常见选项为-r、-n、-k。其中-n表示按数字顺序升序排列,而-r表示反序,-k可以指定按第几个字段来排序。
sort /opt/sort.txt -r -k 2将文件第二列进行降序排列sort /opt/sort.txt -n -k 2将文件第二列进行升序排列sort /opt/sort.txt默认对第一列进行升序排列awk '/Failed/{ip[$11]++}END{for(i in ip){print i,ip[i]}}' /var/log/secure | sort -r//对访问系统失败的ip记录进行降序排列
awk -f cal.txt score.txt //将cal.txt中的文本读出作为脚本命令,处理score.txt
其中:cal.txt中的内容为
#!/bin/awk -f
#运行前
BEGIN {
math = 0
english = 0
computer = 0
printf "NAME NO. MATH ENGLISH COMPUTER TOTAL\n"
printf "---------------------------------------------\n"
}
#运行中
{
math+=$3
english+=$4
computer+=$5
printf "%-6s %-6s %4d %8d %8d %8d\n", $1, $2, $3,$4,$5, $3+$4+$5
}
#运行后
END {
printf "---------------------------------------------\n"
printf " TOTAL:%10d %8d %8d \n", math, english, computer
printf "AVERAGE:%10.2f %8.2f %8.2f\n", math/NR, english/NR, computer/NR
}
score.txt
Marry 2143 78 84 77
Jack 2321 66 78 45
Tom 2122 48 77 71
Mike 2537 87 97 95
Bob 2415 40 57 62
本案例要求编写脚本实现一键部署Nginx软件
#!/bin/bash
y=`yum repolist | awk '/repolist/{print $2}' | sed 's/,//'`
[ $y -eq 0 ] && exit
yum -y install gcc openssl-devel pcre-devel
tar -xf /root/nginx-1.12.2.tar.gz
cd nginx-1.12.2
./configure
make
make install
1)确认安装效果
Nginx默认安装路径为/usr/local/nginx,该目录下会提供4个子目录,分别如下:
/usr/local/nginx/conf 配置文件目录
/usr/local/nginx/html 网站页面目录
/usr/local/nginx/logs Nginx日志目录
/usr/local/nginx/sbin 主程序目录
主程序命令参数:
/usr/local/nginx/sbin/nginx //启动服务
/usr/local/nginx/sbin/nginx -s stop //关闭服务
/usr/local/nginx/sbin/nginx -V //查看软件信息
netstat命令可以查看系统中启动的端口信息,该命令常用选项如下:
-n以数字格式显示端口号
-t显示TCP连接的端口
-u显示UDP连接的端口
-l显示服务正在监听的端口信息,如httpd启动后,会一直监听80端口
-p显示监听端口的服务名称是什么(也就是程序名称)
netstat -ntulp | grep nginx//查询nginx启动的端口
uptime //查看CPU负载
ifconfig eth0 //查看网卡流量
free //查看内存信息
df //查看磁盘空间
wc -l /etc/passwd //查看计算机账户数量
who |wc -l //查看登录账户数量
rpm -qa |wc -l //查看已安装软件包数量
//查看系统的相关信息,5s执行一次
#!/bin/bash
while true
do
uptime | awk '{print "当前主机的CPU的平均负载为"$8,$9,$10}'
ifconfig eth0 | awk '/RX p/{print "eth0网卡接收的流量为"$5}'
ifconfig eth0 | awk '/TX p/{print "eth0网卡发送的流量为"$5}'
free -m | awk '/^Mem/{print "内存剩余空间为"$4"M"}'
echo "计算机账户数量是" `cat /etc/passwd | wc -l`
echo "计算机登录账户数量是" `who | wc -l`
echo "计算机开启的进程数量是" `ps -aux | wc -l`
echo "本机已安装的软件包数量为" `rpm -qa | wc -l`
sleep 5
clear
done
nginx操作工具,stop,restart,start,status等
#!/bin/bash
case $1 in
stop)
/usr/local/nginx/sbin/nginx -s stop;;
start)
/usr/local/nginx/sbin/nginx;;
restart)
/usr/local/nginx/sbin/nginx -s stop
/usr/local/nginx/sbin/nginx;;
status)
netstat -ntulp | grep nginx &> /dev/null
if [ $? -eq 0 ];then
echo "nginx服务已启动"
else
echo "nginx服务未启动"
fi;;
*)
echo Error;;
esac
检测ssh登录日志,如果远程登陆账号名错误3次,则屏蔽远程主机的IP
检测ssh登录日志,如果远程登陆密码错误3次,则屏蔽远程主机的IP
#!/bin/bash
awk '/Failed password/{ip[$11]++}END{for(i in ip){print i,ip[i]}}' /var/log/secure | awk '$2>3{print $1}'
awk '/Invalid user/{ip[$10]++}END{for(i in ip){print i,ip[i]}}' /var/log/secure | awk '$2>3{print $1}'
默认Linux的cp命令不具有进度显示
我们需要自己编写脚本实现进度显示
可以使用进度条的方式,或者显示百分比的方式
#!/bin/bash
jindu(){
while :
do
echo -ne '\033[43m#\033[0m'
sleep 0.3
done
}
jindu &
cp -r $1 $2
kill $!
echo -e "\n"
案例:读取安全文件中访问系统失败大于等于三次的用户,把他的ip过滤出来并用防火墙屏蔽
#!/bin/bash
while true
do
result=(`awk '/Failed/{ip[$11]++}END{for(i in ip){print i,ip[i]}}' /var/log/secure`)
firewall-cmd --zone=block --list-all | grep ${result[0]}
[ $? -eq 0 ] && continue
if [ ${result[1]} -ge 3 ];then
echo ${result[0]}
firewall-cmd --permanent --zone=block --add-source=${result[0]}
firewall-cmd --reload
fi
sleep 5
clear
done
案例:重定向输出,输入
#!/bin/bash
{
echo "abc"
echo "www.example.com"
echo "1"
} > log.txt
{
read name
read url
read age
} < log.txt
echo "$name已经$age岁了,它的网址是$url"