各类距离的意义与Python实现
转载来自:http://book.2cto.com/201511/58274.html,本文所属图书 > 机器学习算法原理与编程实践。
本节所列的距离公式列表和代码如下:
闵可夫斯基距离(Minkowski Distance)
欧氏距离(Euclidean Distance)
曼哈顿距离(Manhattan Distance)
切比雪夫距离(Chebyshev Distance)
夹角余弦(Cosine)
汉明距离(Hamming distance)
杰卡德相似系数(Jaccard similarity coefficient)
读者可根据自己需求有选择的学习。因使用矢量编程的方法,距离计算得到了较大的简化。
1. 闵可夫斯基距离(Minkowski Distance)
严格意义上,闵氏距离不是一种距离,而是一组距离的定义。
(1)闵氏距离的定义:
两个n维变量A(x11,x12,…,x1n)与 B(x21,x22,…,x2n)间的闵可夫斯基距离定义为: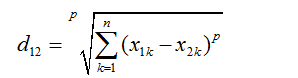
其中p是一个变参数。
当p=1时,就是曼哈顿距离
当p=2时,就是欧氏距离
当p→∞时,就是切比雪夫距离
根据变参数的不同,闵氏距离可以表示一类的距离。
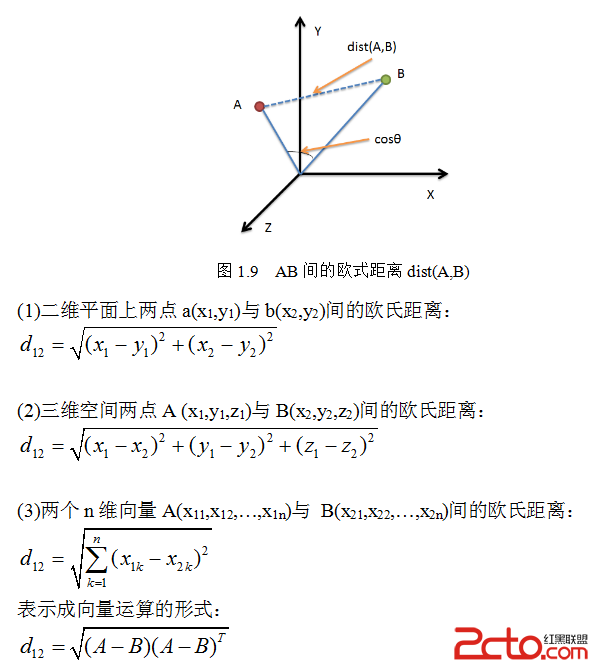
2.欧氏距离(Euclidean Distance)
欧氏距离(L2范数)是最易于理解的一种距离计算方法,源自欧氏空间中两点间的距离公式(如图1.9)。
(4) python实现欧式距离公式的:
from numpy import*
vector1 = mat([1,2,3])
vector2 = mat([4,5,6])
print sqrt((vector1-vector2)*((vector1-vector2).T))
输出:
[[5.19615242]]3.曼哈顿距离(Manhattan Distance)
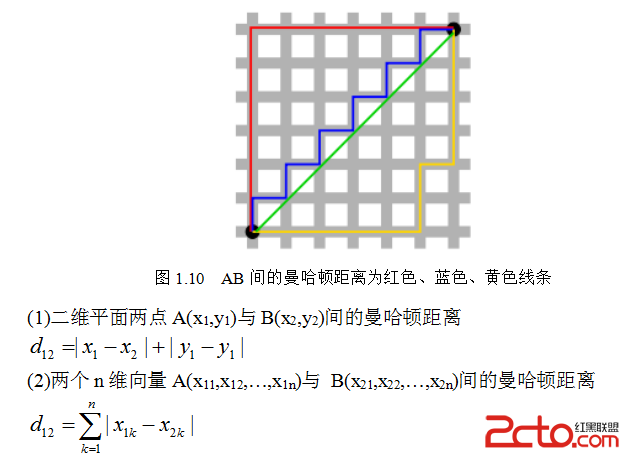
从名字就可以猜出这种距离的计算方法了。想象你在曼哈顿要从一个十字路口开车到另外一个十字路口,驾驶距离是两点间的直线距离吗?显然不是,除非你能穿越大楼。实际驾驶距离就是这个“曼哈顿距离”(L1范数)。而这也是曼哈顿距离名称的来源,曼哈顿距离也称为城市街区距离(City Block distance)(如图1.10)。
(3)python实现曼哈顿距离:
from numpy import*
vector1 = mat([1,2,3])
vector2 = mat([4,5,6])
print sum(abs(vector1-vector2))
输出:
94.切比雪夫距离(Chebyshev Distance)
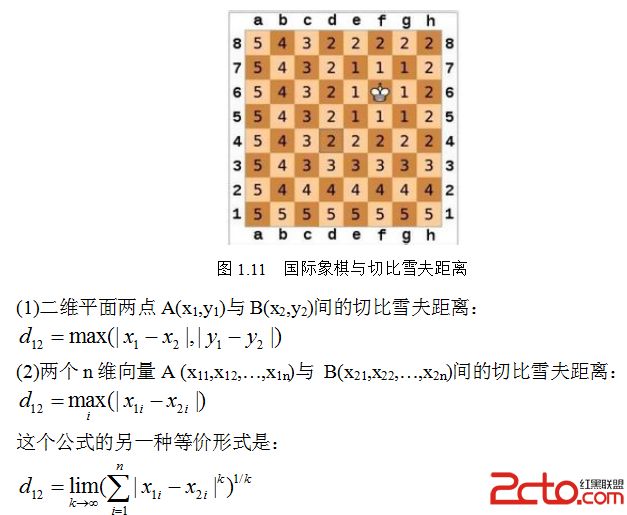
国际象棋玩过么?国王走一步能够移动到相邻的8个方格中的任意一个(如图1.11)。那么国王从格子(x1,y1)走到格子(x2,y2)最少需要多少步?自己走走试试。你会发现最少步数总是max(| x2-x1| , |y2-y1| ) 步。有一种类似的一种距离度量方法叫切比雪夫距离(L∞范数)。
(3) Python实现切比雪夫距离:
from numpy import*
vector1 = mat([1,2,3])
vector2 = mat([4,7,5])
print abs(vector1-vector2).max()
输出:
55. 夹角余弦(Cosine)
几何中夹角余弦可用来衡量两个向量方向的差异,机器学习中借用这一概念来衡量样本向量之间的差异(如图1.12)。
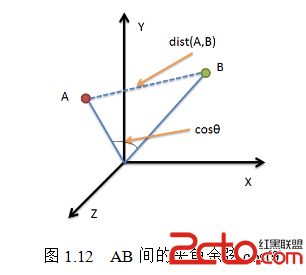
(1)在二维空间中向量A(x1,y1)与向量B(x2,y2)的夹角余弦公式: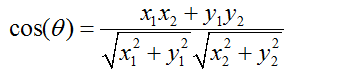
(2) 两个n维样本点A (x11,x12,…,x1n)与 B(x21,x22,…,x2n)的夹角余弦
类似的,对于两个n维样本点A(x11,x12,…,x1n)与 B(x21,x22,…,x2n),可以使用类似于夹角余弦的概念来衡量它们间的相似程度。
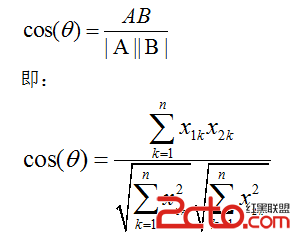
夹角余弦取值范围为[-1,1]。夹角余弦越大表示两个向量的夹角越小,夹角余弦越小表示两向量的夹角越大。当两个向量的方向重合时夹角余弦取最大值1,当两个向量的方向完全相反夹角余弦取最小值-1。
(3)python实现夹角余弦
from numpy import*
cosV12 = dot(vector1,vector2)/(linalg.norm(vector1)*linalg.norm(vector2))
print cosV12
输出:
0.92966968 6. 汉明距离(Hamming distance)
(1)汉明距离的定义
两个等长字符串s1与s2之间的汉明距离定义为将其中一个变为另外一个所需要作的最小替换次数。例如字符串“1111”与“1001”之间的汉明距离为2。
应用:信息编码(为了增强容错性,应使得编码间的最小汉明距离尽可能大)。
(2) python实现汉明距离:
from numpy import*
matV = mat([[1,1,0,1,0,1,0,0,1],[0,1,1,0,0,0,1,1,1]])
smstr = nonzero(matV[0]-matV[1]);
print shape(smstr[0])[1]
输出:
6 7. 杰卡德相似系数(Jaccard similarity coefficient)
(1) 杰卡德相似系数
两个集合A和B的交集元素在A,B的并集中所占的比例,称为两个集合的杰卡德相似系数,用符号J(A,B)表示。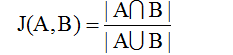
杰卡德相似系数是衡量两个集合的相似度一种指标。
(2) 杰卡德距离
与杰卡德相似系数相反的概念是杰卡德距离(Jaccard distance)。杰卡德距离可用如下公式表示: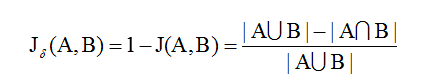
杰卡德距离用两个集合中不同元素占所有元素的比例来衡量两个集合的区分度。
(3) 杰卡德相似系数与杰卡德距离的应用
可将杰卡德相似系数用在衡量样本的相似度上。
样本A与样本B是两个n维向量,而且所有维度的取值都是0或1。例如:A(0111)和B(1011)。我们将样本看成是一个集合,1表示集合包含该元素,0表示集合不包含该元素。
P:样本A与B都是1的维度的个数
q:样本A是1,样本B是0的维度的个数
r:样本A是0,样本B是1的维度的个数
s:样本A与B都是0的维度的个数
那么样本A与B的杰卡德相似系数可以表示为:
这里p+q+r可理解为A与B的并集的元素个数,而p是A与B的交集的元素个数。
而样本A与B的杰卡德距离表示为: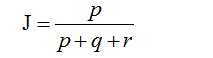
(4) Python实现杰卡德距离:
from numpy import*
importscipy.spatial.distance as dist # 导入scipy距离公式
matV = mat([[1,1,0,1,0,1,0,0,1],[0,1,1,0,0,0,1,1,1]])
print"dist.jaccard:", dist.pdist(matV,'jaccard')
输出:
dist.jaccard: [ 0.75]现在,我们有能力为矩阵中对象间的相似程度(接近与远离)提供各种度量方法,以及编码实现。通过计算对象间的距离,我们就可以轻松地得到表2.8中的四个对象所属的类别:以克、天为单位的苹果是水果类别的一个实例; 以吨、年为单位鲨鱼是大型动物的一个实例。这种区别是明显的,但是,如果我们考察颜色这个特征,情况可能会有所不同,苹果和梨都有黄色这个特征,像这种情况我们如何区分呢?
结合本例,我们不去研究黄色的苹果与黄色的梨有什么差别。而承认其统计规律:苹果是红色的概率是0.8,苹果是黄色的概率就是1-0.8=0.2,而梨是黄色的概率是0.9,将其作为先验概率。有了这个先验概率,就可以利用抽样,即任取一个水果,前提是抽样对总体的概率分布没有影响,通过它的某个特征来划分其所属的类别。黄色是苹果和梨共有的特征,因此,既有可能是苹果也有可能是梨,概率计算的意义在于得到这个水果更有可能的那一种。
这个问题的求解过程就是著名的贝叶斯公式: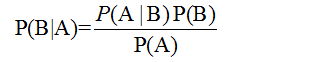
用数学的语言来表达,就是已知P(苹果)=10/(10+10),P(梨)=10/(10+10),P(黄色|苹果)
=20%,P(黄色|梨)=90%,求P(梨|黄色)
可得:P(梨|黄色)=P(黄色,梨)/P(黄色)
=P(黄色|梨)P(梨)/P(黄色)
=81.8%
贝叶斯公式贯穿了机器学习中随机问题分析的全过程。从文本分类到概率图模型,其基本原理都是贝叶斯公式,是机器学习领域最重要的基础概念。