卷积神经网络例子
验证码识别的首选大法--卷积神经网络
不懂的人建议先看一下这篇:
http://www.moonshile.com/post/juan-ji-shen-jing-wang-luo-quan-mian-jie-xi
http://blog.csdn.net/v_july_v/article/details/51812459
首先下载训练数据,我将其放在了这里:http://pan.baidu.com/s/1pLUEjwf,另外注意,这里的csv格式的文件中,将label设置为科学计数法,所以需要人为将其修正。训练数据一共20000张图,每一张都是由数字和大写字母组成,每一张的5个字符所在位置比较接近,因此考虑将其切割为5个字符,总共100000张图,最后利用卷积神经网络进行训练。重新生成的图我放在cut文件夹下,重新生成的图片名name和标签label对应的文件为train_y.xlsx,如图所示
首先导入模块,将其进行切割函数如下:
import tensorflow as tf
import pandas as pd
import os
from PIL import Image
import numpy as np
#from sklearn import cross_validation
#X_train, X_test, y_train, y_test = cross_validation.train_test_split(train_data, train_target, test_size=0.4, random_state=0)
path=r"C:\Users\user\Desktop\type2_train"
files = os.listdir(path)
files = files[3:]
df = pd.read_excel(r"C:\Users\user\Desktop\type2_train\train_y.xlsx")
def cut():
for i in range(20000):
# print (files[i])
im=Image.open(path+"/"+files[i])
region = (30,10,190,50)
cropImg = im.crop(region)
# cropImg.show()
region = [(0,0,40,40),(30,0,70,40),(60,0,100,40),(90,0,130,40),(120,0,160,40)]
for j in range(5):
cropImg1 = cropImg.crop(region[j])
cropImg1.save(r"C:\Users\user\Desktop\type2_train\cut\%s.jpg"%(files[i]+"_"+str(j)))
cut()
def text2vec(text):
vector=np.zeros(36)
def char2pos(c):
if c =='_':
k = 62
return k
k = ord(c)-48
if k > 9:
k = ord(c) - 55
if k > 35:
k = ord(c) - 61
if k > 61:
raise ValueError('No Map')
return k
idx = char2pos(text)
vector[idx] = 1
return vector
def vec2text(vec):
char_pos = vec.nonzero()[0]
text=[]
for i, c in enumerate(char_pos):
char_at_pos = i #c/63
char_idx = c % 36
if char_idx < 10:
char_code = char_idx + ord('0')
elif char_idx <36:
char_code = char_idx - 10 + ord('A')
elif char_idx < 62:
char_code = char_idx- 36 + ord('a')
elif char_idx == 62:
char_code = ord('_')
else:
raise ValueError('error')
text.append(chr(char_code))
return "".join(text)
def convert2gray(img):
if len(img.shape) > 2:
gray = np.mean(img, -1)
# 上面的转法较快,正规转法如下
# r, g, b = img[:,:,0], img[:,:,1], img[:,:,2]
# gray = 0.2989 * r + 0.5870 * g + 0.1140 * b
return gray
else:
return img 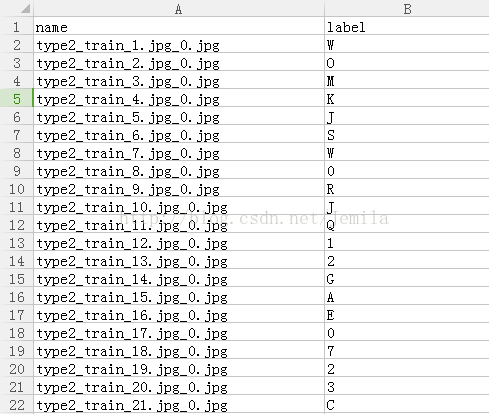
函数代码如下:
path2=r"C:\Users\user\Desktop\type2_train\cut"
files2 = os.listdir(path2)
def get_split(start_size=0,end_size=128):
batch_size=end_size-start_size
batch_x = np.zeros([batch_size, 40*40])#128*1600
batch_y = np.zeros([batch_size, 1*36])#128*36
number=np.array([i for i in range(start_size,end_size)])
for i,j in enumerate(number):
captcha_image=Image.open(path2+"/"+files2[j])
img = np.array(captcha_image)
image=convert2gray(img)
batch_x[i,:] = image.flatten() / 255 # (image.flatten()-128)/128 mean为0
batch_y[i,:] = text2vec(list(df[df.name==files2[j]].label)[0])
return batch_x, batch_y
train_dataset, train_labels = get_split(0,80001)
valid_dataset, valid_labels = get_split(80001,90001)
test_dataset, test_labels = get_split(90001, 99001)
def accuracy(predictions, labels):
return (100.0 * np.sum(np.argmax(predictions, 1) == np.argmax(labels, 1))
/ predictions.shape[0])接下来开始设计模型,reformat函数将三个数据集进行格式转化,比如train_dataset原本是80000*1600矩阵,reformat之后为80000*40*40*1。其中layer1和2是卷积层,layer3是隐藏层,layer4是输出层。
image大小为40*40
num_channels=1,只需保留image前2维即黑白图像
num_labels=36即总的label个数
batch_size 每次输入的图片个数
patch_size 卷积的核大小
depth 为卷积核的个数,即通道数
num_hidden为隐藏层的个数
介绍一下tf.nn.conv2d函数:http://blog.csdn.net/mao_xiao_feng/article/details/53444333
这里之所以是relu函数,可以查看这里:http://www.tuicool.com/articles/vieuIbi
这里有个讨论三个激活函数:https://mp.weixin.qq.com/s?__biz=MzA5MzQwMDk4Mg==&mid=2651042020&idx=1&sn=091c7af42c59b8497b780af409122be1
image_size=40
num_channels=1
num_labels=36
batch_size = 16
patch_size = 5
depth = 16
num_hidden = 64
def reformat(dataset, labels):
dataset = dataset.reshape(
(-1, image_size, image_size, num_channels)).astype(np.float32)
labels = labels
return dataset, labels
train_dataset, train_labels = reformat(train_dataset, train_labels)
valid_dataset, valid_labels = reformat(valid_dataset, valid_labels)
test_dataset, test_labels = reformat(test_dataset, test_labels)
print('Training set', train_dataset.shape, train_labels.shape)
print('Validation set', valid_dataset.shape, valid_labels.shape)
print('Test set', test_dataset.shape, test_labels.shape)
graph = tf.Graph()
with graph.as_default():
# Input data.
tf_train_dataset = tf.placeholder(
tf.float32, shape=(batch_size, image_size, image_size, num_channels))
tf_train_labels = tf.placeholder(tf.float32, shape=(batch_size, num_labels))
tf_valid_dataset = tf.constant(valid_dataset)
tf_test_dataset = tf.constant(test_dataset)
# Variables.
layer1_weights = tf.Variable(tf.truncated_normal(
[patch_size, patch_size, num_channels, depth], stddev=0.1))
layer1_biases = tf.Variable(tf.zeros([depth]))
layer2_weights = tf.Variable(tf.truncated_normal(
[patch_size, patch_size, depth, depth], stddev=0.1))
layer2_biases = tf.Variable(tf.constant(1.0, shape=[depth]))
layer3_weights = tf.Variable(tf.truncated_normal(
[image_size // 4 * image_size // 4 * depth, num_hidden], stddev=0.1))
layer3_biases = tf.Variable(tf.constant(1.0, shape=[num_hidden]))
layer4_weights = tf.Variable(tf.truncated_normal(
[num_hidden, num_labels], stddev=0.1))
layer4_biases = tf.Variable(tf.constant(1.0, shape=[num_labels]))
# Model.
def model(data):
conv = tf.nn.conv2d(data, layer1_weights, [1, 2, 2, 1], padding='SAME')
hidden = tf.nn.relu(conv + layer1_biases)
conv = tf.nn.conv2d(hidden, layer2_weights, [1, 2, 2, 1], padding='SAME')
hidden = tf.nn.relu(conv + layer2_biases)
shape = hidden.get_shape().as_list()
reshape = tf.reshape(hidden, [shape[0], shape[1] * shape[2] * shape[3]])
hidden = tf.nn.relu(tf.matmul(reshape, layer3_weights) + layer3_biases)
return tf.matmul(hidden, layer4_weights) + layer4_biases
# Training computation.
logits = model(tf_train_dataset)
loss = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(labels=tf_train_labels, logits=logits))
# Optimizer.
optimizer = tf.train.GradientDescentOptimizer(0.05).minimize(loss)
# Predictions for the training, validation, and test data.
train_prediction = tf.nn.softmax(logits)
valid_prediction = tf.nn.softmax(model(tf_valid_dataset))
test_prediction = tf.nn.softmax(model(tf_test_dataset))num_steps = 1001
with tf.Session(graph=graph) as session:
tf.global_variables_initializer().run()
model_saver = tf.train.Saver()
print('Initialized')
for step in range(num_steps):
offset = (step * batch_size) % (train_labels.shape[0] - batch_size)
batch_data = train_dataset[offset:(offset + batch_size), :, :, :]
batch_labels = train_labels[offset:(offset + batch_size), :]
feed_dict = {tf_train_dataset : batch_data, tf_train_labels : batch_labels}
_, l, predictions = session.run(
[optimizer, loss, train_prediction], feed_dict=feed_dict)
if (step % 50 == 0):
print('Minibatch loss at step %d: %f' % (step, l))
print('Minibatch accuracy: %.1f%%' % accuracy(predictions, batch_labels))
print('Validation accuracy: %.1f%%' % accuracy(
valid_prediction.eval(), valid_labels))
print('Test accuracy: %.1f%%' % accuracy(test_prediction.eval(), test_labels))
model_saver.save(session,r"C:\Users\user\Documents\Python Scripts3\CNN.ckpt")不过这里面的代码依然比较初始,使用的是udacity的初始代码改写而成,对于池化、drop_out、学习率衰减,hidden_layer层数增加 等都没有加入,希望后人可以再改进改进。
最终输出如下:
Initialized
Minibatch loss at step 0: 7.026362
Minibatch accuracy: 6.2%
Validation accuracy: 2.9%
Minibatch loss at step 50: 2.510715
Minibatch accuracy: 25.0%
Validation accuracy: 18.9%
Minibatch loss at step 100: 1.361911
Minibatch accuracy: 50.0%
Validation accuracy: 64.7%
Minibatch loss at step 150: 0.608910
Minibatch accuracy: 68.8%
Validation accuracy: 75.1%
Minibatch loss at step 200: 0.184350
Minibatch accuracy: 100.0%
Validation accuracy: 91.1%
Minibatch loss at step 250: 0.065574
Minibatch accuracy: 100.0%
Validation accuracy: 95.5%
Minibatch loss at step 300: 0.001877
Minibatch accuracy: 100.0%
Validation accuracy: 98.2%
Minibatch loss at step 350: 0.161129
Minibatch accuracy: 93.8%
Validation accuracy: 97.2%
Minibatch loss at step 400: 0.039044
Minibatch accuracy: 100.0%
Validation accuracy: 98.6%
Minibatch loss at step 450: 0.023053
Minibatch accuracy: 100.0%
Validation accuracy: 98.0%
Minibatch loss at step 500: 0.043104
Minibatch accuracy: 100.0%
Validation accuracy: 97.5%
Minibatch loss at step 550: 0.353673
Minibatch accuracy: 93.8%
Validation accuracy: 99.3%
Minibatch loss at step 600: 0.006877
Minibatch accuracy: 100.0%
Validation accuracy: 99.5%
Minibatch loss at step 650: 0.008127
Minibatch accuracy: 100.0%
Validation accuracy: 99.4%
Minibatch loss at step 700: 0.002018
Minibatch accuracy: 100.0%
Validation accuracy: 99.7%
Minibatch loss at step 750: 0.017241
Minibatch accuracy: 100.0%
Validation accuracy: 99.8%
Minibatch loss at step 800: 0.003464
Minibatch accuracy: 100.0%
Validation accuracy: 99.7%
Minibatch loss at step 850: 0.020851
Minibatch accuracy: 100.0%
Validation accuracy: 99.8%
Minibatch loss at step 900: 0.024757
Minibatch accuracy: 100.0%
Validation accuracy: 99.2%
Minibatch loss at step 950: 0.003235
Minibatch accuracy: 100.0%
Validation accuracy: 99.5%
Minibatch loss at step 1000: 0.004147
Minibatch accuracy: 100.0%
Validation accuracy: 99.8%
Test accuracy: 99.7%