graph embedding 论文及源码阅读 deepwalk & line & node2vec & bine
最近学习了下graph embedding方面的内容,主要看了如下几篇论文及对应开源代码,记录下。
DeepWalk: Online Learning of Social Representations
LINE: Large-scale Information Network Embedding
node2vec: Scalable Feature Learning for Networks
BiNE: Bipartite Network Embedding
graph embedding是将网络中的节点使用低维向量来表示,这种向量表示可以反映原始网络结构,可应用于推荐等场景。
deepwalk:
比较直观,训练语料中的每一个样本都是从网络中以某节点为起点,然后随机游走产生一个路径,将路径上的节点当作一条句子,然后使用word2vec来训练。
line:

在该图中,节点6和节点7在语义空间中距离是近的,因为他们之间连了一条边;节点5和6的距离也是近的,因为他们共享了很多邻居节点。line定义了这两种关系,分别为first order和second order。
first order:
为了建模first order相似度,对每条无向边,定义了一个联合分布

v代表节点,u代表对应节点的embedding,而真实分布为
![]()
其中![]() 为归一化因子,然后使用kl散度来衡量两个分布的距离,化简之后为最小化下面式子,其中wij表示节点i和j间的边的权重,
为归一化因子,然后使用kl散度来衡量两个分布的距离,化简之后为最小化下面式子,其中wij表示节点i和j间的边的权重,
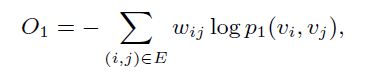
另外,first order只适用于无向边。
second order:
second order适用于有向图和无向图,以下只考虑有向图,无向图中每条边可以看作两条有向边。second order认为两个节点如果共享了很多邻居节点,那么他们是相似的,在这里邻居称为context,每个节点有两个embedding,原始embedding和作为context时候的embedding。对于每一条有向边(i,j),定义如下概率分布,表示节点vi产生上下文vj的概率

其中|V|为网络中节点数目
而真实分布为
![]() 其中wij为边(i,j)的权重,di为节点i的度。
其中wij为边(i,j)的权重,di为节点i的度。
类似的化简两个分布的kl散度之后为
![]()
几个优化点:
- 注意到second order的归一化因子需要扫一遍所有节点,为了减少这部分计算量论文使用了负采样的方法,对于一条边采样出几个边作为负样本。
- 在使用随机梯度下降时,计算梯度时边权w会作为一个因子乘入,如果边权分布差异较大的话,那么梯度变化也会很大,难以设置合适的学习率,为了解决这个问题,直观的可以将一条权重为w的边拆为w条边权为1的边,但是这样会导致内存膨胀,为了解决这个问题,在原图中按照权重w对边进行采样,采样到的边看作为一条边权为1的边。
- 随机采样使用了alias method,预处理之后可以O(1)的进行采样。关于alias method可以看这里http://shomy.top/2017/05/09/alias-method-sampling/
另外,first order和second order两个模型单独训练,产出的向量concate之后使用。
然后看下简单line的开源实现,核心函数为TrainLINEThread

首先采样得到一条边(u,v),中间的循环为产生样本及采负样本,order为1表示first order,order为2表示second order,然后更新样本的embedding,两个order的区别为lv使用的embedding和lu的embedding是否相同。
node2vec:
deepwalk中使用dfs来生成路径,在node2vec中则引入bfs,通过超参数p和q来决定使用bfs还是dfs

如图,当一次随机游走从t走到了v之后,考虑下次游走时各个邻居x的概率分布如下,d表示距离,dtx为0表示返回t;dtx为1表示t和v的共同邻居,近似bfs;dtx为2表示v的邻居,为dfs。值得一提的是并不是真正的bfs,而是限定在v的邻居中,如果只与t邻接是不会被采样到的。
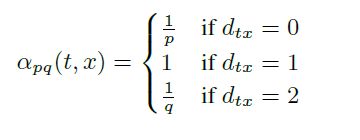
然后看下node2vec中游走代码
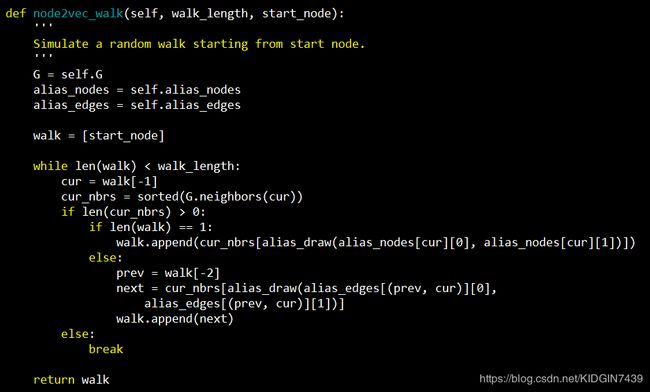
alias_draw方法即为alias method中的采样方法,当路径长度不为1时,会在当前节点邻居中按照p和q决定进行bfs还是dfs。
bine:
这篇论文考虑在一个异构二部图上的图embedding,例如在推荐场景中user和item就是一个异构二部图。
类似line中的first order和second order,bine中分为显式关系和隐式关系,图中两点之间如果连接了一条边,即为显式关系,主要刻画二部图中两类节点之间的关系,例如user和item之间是显式关系;隐式关系刻画二部图中同类节点间的关系,例如user和user,item和item,如果两个节点之间存在一条路径,那么表示这两个点之间有隐式的关系,路径越多,则这两点间的隐式关系越强。
显式关系:
和line完全一致
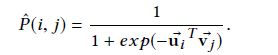
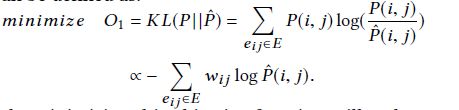
隐式关系:
直接按照定义的,需要计算任意两点之间路径的个数,不太现实,所以使用了游走的方法来构建样本,假设原始网络为G,G的shape为|USER|*|ITEM|,,bine中会基于G会产生两个新图Gu和Gi,其中Gu = G * GT,Gi = GT * G,直观意义上例如Gu[u1][u2]即为用户u1和u2共同点击的item个数(当所有边权为1时),游走序列基于这两个图产生。
在通过上述过程产出了样本序列之后,之后就使用skipgram来解决了,下面公式中的u和v分别代表一类节点,例如u代表user,v代表item。
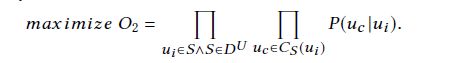
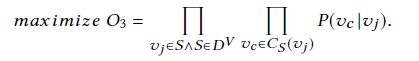
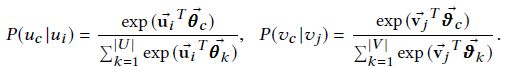
不同于line的分开训练两种关系,bine是联合训练两种关系,总流程为

另外,bine中游走序列的产生也不同于deepwalk,deepwalk中为对每个节点游走固定的次数,每次游走序列的长度也为定值,bine中游走次数和长度均为可变的,叫做biased ramdom walk。
然后看下bine中生成Gu,Gv的代码

A即为上述的G,然后通过矩阵乘得到新图fw_u和fw_v,然后在两个新图上进行游走得到训练样本。