Tensorflow_03_Checkpoint 与 Tensorboard
Brief 概述
在理解了建构神经网络的大致函数用途,且熟悉了神经网络原理后,我们已经大致具备可以编写神经网络的能力了,在涉及比较复杂的神经网络结构前,还有两件重要的事情需要了解,那就是中途存档和事后读取的函数,它攸关到庞大的算力和时间投入后产出的结果是否能够被再次使用,是一个绝对必须弄清楚的环节。另外是 Tensorflow 提供的的一个工具名为 Tensorboard,它可以很有效率的为我们呈现数据流图可视化的过程,包含了计算的结果和数据分布的状态,让我们在寻找错误的时候有一个更为清晰的逻辑脉络,因此本节主要围绕这两个主题展开:
- Checkpoint
- tf.train.Saver().save()
- tf.train.Saver().restore()
- Tensorboard
前者如同会议记录一般,可以针对性的把训练过程记录下来,除了避免前功尽弃之外,还可以让我们有机会一窥训练过程的究竟,从演变过程中寻找改善算法的方案;而后者提供一个在浏览器梳理计算过程的核心工具,提升了整体的开发效率与优化参数的过程。
p.s. 关于设备如果手边没有,非常建议直接使用云端的计算服务,如 AWS, FloydHub 等平台
其他在深度学习中常用的函数定义方法可以参考上一篇文章: Tensorflow_02_Useful Functions 常用函数大全
Checkpoint 检查点
在初期一般训练模型简单且训练速度极快,对于参数中间变化的过程我们也不会特别在意,但是到了复杂的神经网络训练过程时,为参数训练过程中途存档这件事情就会变得非常重要,这就像我们玩电玩游戏闯关的时候,希望最好能够中途存档,如果死在半路上可以直接从存档的地方恢复游戏。
Save checkpoints 储存检查点
1-1. Save checkpoints 储存检查点
同理深度学习训练过程,一般训练耗费时间约为几天乃至一周,如果中途发生机器停机或是任何意外导致训练终止,我们可以从检查点记录的地方重新开始。抑或者如果我们要分析训练过程中参数的变化走势,检查点也非常实用。使用的类为:
- tf.train.Saver(max_to_keep=None) 档名: 「.ckpt」
- .Saver({’save_w‘: weight}) 括弧中可以用字典的方式指定只要储存哪一个参数
- max_to_keep=None: 最多有几个检查点被保存下来,如果是 None 或是 0 则表示全保存
- keep_checkpoint_every_n_hours=1: 设置几个小时保存一次检查点
变量以二进制的方式被存在名为 .ckpt 的档案中,内容包含了变量的名字和对应张量的数值,创建一个该类的示例,就可以呼叫里面储存与载入储存文件内容的函数方法:
- tf.train.Saver().save(sess, './file_directory', global_step=int(num))
- sess: 表示要储存哪个绘话里面的参数
- './file_directory/file_name': 储存的路径沿着执行训练的 .py 文档路径位置继续指定路径,如果文件夹不存在指定目录的话,它会自行创建。官网教程中建议档名后面连同后缀一起加上,如下代码...
- global_step:指定一个数字,将一起被纳入检查点文件命名中
!!! 储存这些参数的时候特别需要注意申明清楚参数的数据类型非常重要,它攸关到之后要呼叫回这些参数的时候是否顺利,如果没有事先申明清楚,大概率上会有错误发生。
下面代码展示如何保存检查点:
import numpy as np
import tensorflow as tf
x_data = np.random.rand(100).astype(np.float32)
y_data = x_data * 0.1 + 0.3
weight = tf.Variable(tf.random_uniform(shape=[1], minval=-1.0, maxval=1.0),
dtype=np.float32)#, name='weight')
bias = tf.Variable(tf.zeros(shape=[1]), dtype=np.float32, name='bias')
y = weight * x_data + bias
loss = tf.reduce_mean(tf.square(y - y_data))
optimizer = tf.train.GradientDescentOptimizer(0.5)
training = optimizer.minimize(loss)
sess = tf.Session()
init = tf.global_variables_initializer()
sess.run(init)
# The instance is created to call the method saving checkpoint
saver = tf.train.Saver()
save_w = tf.train.Saver({'a_name': weight})
for step in range(101):
sess.run(training)
if step % 10 == 0:
print('Round {}, weight: {}, bias: {}'
.format(step, sess.run(weight[0]), sess.run(bias[0])))
saver.save(sess, './checkpoint/linear.ckpt', global_step=step)
save_w.save(sess, './weight/linear.ckpt', global_step=step)
saver.save(sess, './checkpoint/linear.ckpt')
sess.close()Round 0, weight: 0.6087742447853088, bias: 0.031045857816934586
Round 10, weight: 0.3177388906478882, bias: 0.18408644199371338
Round 20, weight: 0.19332920014858246, bias: 0.2503160834312439
Round 30, weight: 0.14000359177589417, bias: 0.27870404720306396
Round 40, weight: 0.11714668571949005, bias: 0.2908719480037689
Round 50, weight: 0.10734956711530685, bias: 0.29608744382858276
Round 60, weight: 0.10315024852752686, bias: 0.29832297563552856
Round 70, weight: 0.10135028511285782, bias: 0.29928117990493774
Round 80, weight: 0.10057878494262695, bias: 0.29969191551208496
Round 90, weight: 0.10024808347225189, bias: 0.2998679280281067
Round 100, weight: 0.10010634362697601, bias: 0.2999434173107147
检查点的路径设置需要使用 「./.../.../...」 的格式去写路径,尤其是开头的 ./ 必须加上,否则在某些平台上会出现错误,等代码运行完毕后在下面 .py 文档执行路径下出现我们设置的储存文件夹和文件名称,如下图:

在默认情况下 tf.train.Saver(max_to_keep=5) 是我们无特别设定的结果,因此只会保存离最近更新的五个参数,其他的参数将即自动删除。
1-2. Read checkpoints 读取检查点
文件存好之后接下来就是读取上图中储存的文件,储存在文件里面的数据是一个原封不动的 tf.Variable() 物件,有着与储存前一模一样的名字和属性,甚至在呼叫回该储存的变量时也不用初始化,是一个非常全面的保存结果, 只是需要记得: 「同样变量名的物件需要事先存在在代码中, 并且数据类型和长相必须一模一样。」
读取的方式也很直观,同样的创建一个 tf.train.Saver() 示例,并用该示例里面的方法 .restore() 完成读取,读取完毕后储存的参数就回像起死回生一般重新回到我们的代码中。
- tf.train.Saver().restore(sess, 'file_directory')
- sess: 表示我们希望把该储存的内容重新叫回哪一个绘话中
- './file_directory/file_name': 表示我们要呼叫的该存档文件
p.s. 如果在储存过程中有加上 global_step 参数,呼叫文档名的时候就必须一起把数字也加上去,如下代码。
呼叫储存文件的时候有以下三种情况:
- 最直接: 使用 tf.train.Saver() 创建示例后,呼叫 .restore() 方法配合对应名字,成功回到训练中途的记录
- 第一个方法受阻: 绕道使用 .meta 储存文件,并使用 tf.import_meta_graph() 示例的 .restore() 方法,同样可以成功回到训练中途的记录
- 呼叫只储存部分参数的记录档: 创建一个示例前先在 tf.train.Saver() 括弧中使用字典形式声明好当时部分储存的时候对应一模一样名字的字典键和参数名,再用 .restore() 方法成功回到训练中途的记录
详细代码如下演示:
import tensorflow as tf
# tf.reset_default_graph()
weight = tf.Variable([33], dtype=tf.float32)#, name='weight')
bias = tf.Variable([3], dtype=tf.float32, name='bias')
saver = tf.train.Saver()
# saver = tf.train.import_meta_graph('./checkpoint/linear.ckpt.meta')
saver_2 = tf.train.Saver({'a_name': weight})
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
path1 = saver.restore(sess, './checkpoint/linear.ckpt-90')
path2 = saver_2.restore(sess, './weight/linear.ckpt-60')
print(sess.run(weight))
print(sess.run(bias))
sess.close()
'''
print(sess.run(biases))
### ----- Result as follow ----- ###
FailedPreconditionError:
Attempting to use uninitialized value Variable
[[Node: _retval_Variable_0_0 = _Retval[T=DT_FLOAT, index=0,
_device="/job:localhost/replica:0/task:0/device:CPU:0"](Variable)]]
'''
### ----- Result is shown below ----- ###
INFO:tensorflow:Restoring parameters from ./checkpoint/linear.ckpt-90
INFO:tensorflow:Restoring parameters from ./weight/linear.ckpt-60
[0.10315025]
[0.29986793]可以观察到,如果没有成功导入内容, sess.run() 执行一个参数的时候就会被通知该参数没有初始化,需要特别注意。另外如果重复导入同样的值到该代码中,那么该值以最后一次导入为主,如上面代码中的 weight,最近导入的 60 个回合训练的 weight 值比训练 90 个回合的 bias 值还要不准得多。
ValueError: At least two variables have the same name: Variable
花了大把的时间才找出在回传参数的时候发生错误的症结点,最后原因还是在于 tf.Variable() 的格式没有完全一样,前面只专注在数据格式上面,但是其节点名称必须也完全一致才可以! 如果表明名称 name='a_name', 那么就都不要写,如果表明了名称,那就必须完全一致才行!
下面提炼三个有关储存和导出的要点:
- 储存的时候官网建议我们呢加上 .ckpt 后缀的目的仅仅只是为了区隔该储存文件与别的文件之间的不同,其实并非真正去修改其后档名,因此没有加上此后缀的情况下,储存的参数照样可以被导入
- 储存后的文件状态有些电脑中是三个,有些是四个,他们的全名甚至没有与当时储存文件时的名字完全相同,但是实际上不用担心,在回传参数的时候只要想着当时储存的档名是什么即可,完全可以忽视不同档名的影响
- 回传参数的时候必须与法官一样严格的审视要被导入的框架容器是否跟当时储存参数的时候完全一样,包含命名节点的名字,和每个节点设置的数据类型
p.s. 如果是使用 Jupyter Notebook 启动代码的话,切记在使用 .restore 回传参数之前确定没有先启动了训练的过程,需要该变量的值是空的情况下才能顺利传参
Save / Restore Related Useful Functions 好用函数
1. tf.train.latest_checkpoint('./.../...')
回传的是该目录下最近一次被储存的 checkpoint 文件完整位置,数据类型是字符串,此类方法放入的路径切记是文件夹目录,而非文件本身的目录,因此通常只要找到存放储存点的文件夹目录,用此方法回传一个字符串结果后,放入 .restore() 内就可以顺利呼叫最新的存档参数内容。
2. Tensorboard 可视化工具
在使用 Tensorflow 之初,我们首先了解的两个观念肯定是节点 node 和边 edge,借由在这两者里面添加张量和运算单元等方法,我们最终可以驱动计算机完成我们期望的运算结果。然而这些运算过程都是在我们脑子里面抽象概念,放到计算机中也只是一行一行的代码,并没有办法提供给我们太直观的感受,而 Tensorboard 就是中间的润滑剂,它良好的构建一个硬邦邦的代码与直观感受之间的桥梁,让如同一个黑箱般的神经网络运算过程透出一线光亮,只要在现有的代码中添加一些 作用域 Scope 的设置后,导出文件并使用终端的 Tensorboard 指令执行,Tensorflow 就会自动为我们建构出一个完整的数据布告栏在浏览器中使用。
而这些额外添加的代码这里,目的就是用来给不同的节点和边之间设置各自归属的作用域,分为下面两种:
- node names
- name scopes
继续沿用上面的代码,加上作用域的方法如下:
import numpy as np
import tensorflow as tf
# Create a graph and set this graph as the default one.
# By doing this, the original default graph would not be called
graph = tf.Graph()
with graph.as_default():
x_data = np.random.rand(100).astype(np.float32)
y_data = x_data * 0.1 + 0.3
with tf.name_scope('linear'):
weight = tf.Variable(tf.random_uniform(shape=[1], minval=-1.0, maxval=1.0),
dtype=np.float32, name='weight')
bias = tf.Variable(tf.zeros(shape=[1]), dtype=np.float32, name='bias')
y = weight * x_data + bias
with tf.name_scope('gradient_descent'):
loss = tf.reduce_mean(tf.square(y - y_data), name='loss')
optimizer = tf.train.GradientDescentOptimizer(0.5)
training = optimizer.minimize(loss)
init = tf.global_variables_initializer()
sess = tf.Session(graph=graph)
writer = tf.summary.FileWriter('/Users/kcl/Documents/Python_Projects/01_AI_Tutorials/tb')
writer.add_graph(graph)
sess.run(init)
for step in range(101):
sess.run(training)
writer.close()
sess.close()代码的运行结果会在指定的目录下创建一个文件,该文件只能够在终端 (Terminal or CMD) 使用下面指令开启: tensorboard --logdir="/Users/01_AI_Tutorials/tb" 或者 tensorboard --logdir /Users/01_AI_Tutorials/tb 的方式开启,之后终端里面会创建一个本地伺服器和一个对应网址,用来让使用者在浏览器中开启 Tensorboard 的页面,下图即为开启上面代码背后的 Tensorboard 模样:
 在每个 Tensor 后面都可以加上 name 予以名称,而 tf.name_scope() 则可以把一搓的 Tensors 打包起来成为一个更大的涵盖范围。
在每个 Tensor 后面都可以加上 name 予以名称,而 tf.name_scope() 则可以把一搓的 Tensors 打包起来成为一个更大的涵盖范围。
p.s. 但是值得我们注意的一点,只有属于 tf 的节点与运算子,或者是跟节点产生关联的算式才能够被记录在 Tensorboard 上面,如果跟 tf 一点关系都没有的算式如 x_data,y_data 就不会显示在数据流图中。
Dive into the Details of Graph 深究细节
在建立数据流图的上面过程中,实际上完整的步骤如下:
- 创建一个 tf.Graph() 对象
- 使用对象的方法 .as_default() 设定该图为指定的图
- 在该图中设定需要的节点内容并给予名称
- 使用 tf.name_scope() 等方法设定更大作用域的名称,名称注意不能够有空格
- 使用 tf.summary.FileWriter() 方法在指定路径下创建一个文件
- 把步骤五的方法指向一个对象,然后使用 .add_graph() 添加指定 session 创建好的 graph
完成后,才可以如上述步骤去终端指定路径下开启 Tensorboard 观察数据流图,一般代码中之所以没那么复杂,原因是在创建数据流图的时候,Tensorflow 框架本身已经为我们预设了一个数据流图,因此省去许多麻烦。
Unveil the default Graph 一探预设流图
1. Graph is the foundation of All
我们在使用 Tensorflow 创建自己的数据流图的时候,都是基于 一张图 的构建的,此图就如同一张无边际的画布让我们在上面自由的创建张量和运算子,即便在我们不特别去设定一个数据流图的时候,tf 框架本身也已经自动帮使用者生成好了,因此可以确保每个节点和运算子都落在这张图里面。
但是如果如上图的情况一样,是我们自己从头到尾设定的数据流图作用域,那就必须考虑到是否把全部的节点和运算子全部都建立在图上,一旦某个东西落在了图外面,到了执行的时候 tf 框架就会不明白该对象是谁家的孩子。
2. Calculation and the Graph
把哪个节点和运算子归类到了哪个作用域这件事情,说到底其实也就只是在 Tensorboard 上面呈现的画面不同而已,并不会对运算的功能产生任何影响。
另外,Tensorboard 只会打印数据流图本身的结构,并不会参与 sess.run() 执行运算的结果输出,因此不论储存文档的代码放在 sess.run() 的前还是后,结果都会是一样的结构呈现,但并没有运算数值。
Import Data 数据导入
直到目前为止我们在 "图" 上创建的数据流图也仅仅只是数据流图,并没有数据实际上在 Tensorboard 中被参与进来,把参数写入到 Tensorboard 的方法不外乎 tf.summary 系列的函数。然而,用这些函数写入数据到 Tensorboard 的过成类似于 sess.run() 的过程,对同一个对象而言一次只会写一个数字,完成图之所以会有一个连贯的结果,那是因为使用 Python 建构一个回圈运行出来的结果导致,系列函数包含了如下几个:
- tf.summary.scalar()
- tf.summary.image()
- tf.summary.audio()
- tf.summary.histogram()
- tf.summary.tensor()
上面陈列方法的参数项内容都是一样的,皆为 ...('a_name/node', object),第一个参数是一个字符串,其内容是什么,在图上显示出来坐标的名称就是什么,而第二项则是一个经过运算后的对象,谁被放到这里的话,谁就能够在图上的坐标轴中显示方程式经过训练的变化过程。
面对简单的数据流图,我们尚且可以数得出来一共有多少个数值需要被放入 Tensorboard 中,但是如果是像 Inception 这类的巨大神经网络,那我们就需要一个工具统合所有需要被写入的对象,一次性的完成写入的动作:tf.summary.merge_all(),我们可以进一步想像上面陈列的五种方法就像是剪刀,负责剪下我们期望截取的数值,然而一次一次贴上 board 实在太麻烦,因此先全部把这些剪下来的值融为一体后,再使用 .FileWriter() 方法一次贴上,并以 .add_summary() 方法逐步更新。函数方法使用方式如下代码:
import numpy as np
import tensorflow as tf
graph = tf.Graph()
with graph.as_default():
x_data = np.random.rand(100).astype(np.float32)
y_data = x_data * 0.1 + 0.3
with tf.name_scope('linear'):
weight = tf.Variable(tf.random_uniform(shape=[1], minval=-1.0, maxval=1.0),
dtype=np.float32, name='weight')
# In order to watch the changes of weight, use histogram method
tf.summary.histogram('linear_weight', weight)
bias = tf.Variable(tf.zeros(shape=[1]), dtype=np.float32, name='bias')
# Mind that we don't need to assign the method to an object
tf.summary.histogram('linear_bias', bias)
y = weight * x_data + bias
with tf.name_scope('gradient_descent'):
loss = tf.reduce_mean(tf.square(y - y_data), name='loss')
# The changes of loss would be updated in each iteration of optimization
tf.summary.scalar('linear_loss', loss)
optimizer = tf.train.GradientDescentOptimizer(0.5)
training = optimizer.minimize(loss)
### --! Mind the graph scope if we are using the graph set by ourselves !-- ###
init = tf.global_variables_initializer()
# As we can see above, we have total 3 values needed to be merged
merge = tf.summary.merge_all()
# If we are using the default graph, "graph=graph" would not need to be emphasized
sess = tf.Session(graph=graph)
# A graph should only be created once outside of the for loop
writer = tf.summary.FileWriter('/Users/kcl/Documents/Python_Projects/01_AI_Tutorials/tb')
# If the default graph is used, "graph" should be replaced by "sess.graph"
writer.add_graph(graph)
sess.run(init)
for step in range(101):
if step%2 == 0:
# In order to update the value throughout training iteration,
# we should use add_summary method to record the values into the graph.
# But before the recording, we have to merge all summary nodes again first.
m = sess.run(merge)
writer.add_summary(m, step)
sess.run(training)
if step % 10 == 0:
print('Round {}, weight: {}, bias: {}'
.format(step, sess.run(weight[0]), sess.run(bias[0])))
writer.close()
sess.close()p.s. 需要非常注意如果是自己定义的 Graph,就必须非常小心作用域错误位造成的程序崩溃。
代码当中,我们可以设定要在经历几个 step 之后,才 merge 一次上面的所有值并把这些值写入到文件当中,成为 Tensorboard 里面显示坐标图的精度控制,下面是经过不同的 tf.summary 方法回传值到文件中并用浏览器显示出来的结果: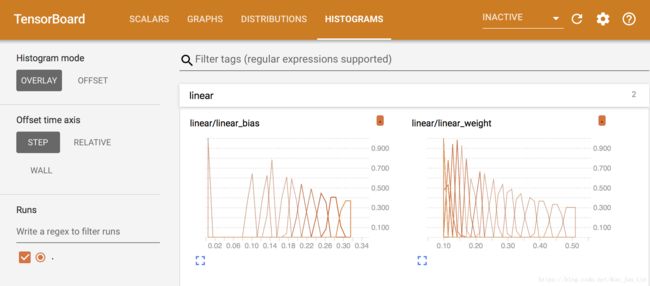
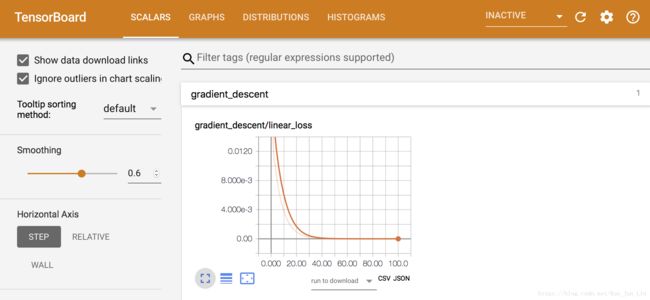

利用 Tensorboard 提供的诸多工具可以让我们在训练模型的过程中更容易找到问题所在,并根据过程的变化来判断优化模型的方向。此工具是 Google 话费大量人力所共同完成的一项厉害的作品,同时也是其他深度学习框架中没有的工具之一,如果使用其他的模型同时需要观察例如损失函数的数值变化,那么使用者只能够自己从头建构坐标轴,使用如 matplotlib 等工具一点一点的把数值记录到图上,但这么一来又将降低代码的执行效率,是一个鱼与熊掌的关系。反观 Tensorboard 是一个嵌入在 tf 的工具,有非常好的效率和兼容性,值得让我们花时间一探究竟。