关系型数据库中联合主键和唯一索引的应用
一、前言
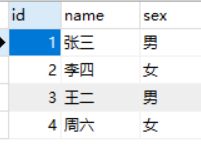
在项目开发中往往会遇到两个实体对象之间存在多对多关系的情况,此时我们会维护两个实体对象表,一个关系表,用来存放两者之间的关系。比较典型的案例是学生表、课程表、学生课程关系表。在这种关系表中,我们可以确定的是,学生和课程关系虽然是多对多,但一个确定的学生id和一个确定的课程id在关系表中只能存在一个。如下图所示:,业务逻辑就是一个学生只能有当前课程的一个分数。
t_student t_course t_student_course_rel

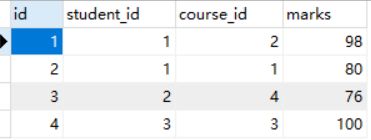
因此可以得知,通过student_id和course_id可以唯一确认一个t_student_course_rel数据,相同的student_id、course_id最多只能存在一条数据。按照正常的业务逻辑来说,不会出现意外的情况,但是一旦出现了,对于以后的查询操作将是一个潜在的隐患,如 select * from t_student_course_rel where student_id=1 and course_id = 2 ,此时我们希望只查出来一条数据,但如果出现了意外情况,则可能对应出来多条数据,这样便会报错。
导致意外的情况:后端高并发的操作没有做出处理、插入数据时没有做验证等等。
解决方案:1. 对高并发操作加锁, 并且在插入数据时做验证。2. 可在数据库层面做出限制,如联合主键和唯一索引均可。
接下来,以这几个表为例,分析使用两者之间的区别。
二、联合主键和唯一索引的应用
上述提到,可以对 student_id和 course_id做联合主键和唯一索引,均可以实现在数据库层面对关系表中异常数据做出限制,我们如何选择呢?
1.使用联合主键限制
如果是在最初建关系表t_student_course_rel 的时候,就已经考虑到这个需求的话,可以考虑将student_id和course_id直接当做联合主键去使用。建表语句如下图所示:
CREATE TABLE `t_student_course_rel ` (
`id` bigint(20) NOT NULL ,
`student_id` bigint(20) NOT NULL ,
`course_id` bigint(20) NOT NULL ,
`marks` int(11) NOT NULL DEFAULT 0 ,
PRIMARY KEY (`student_id`, `course_id`)
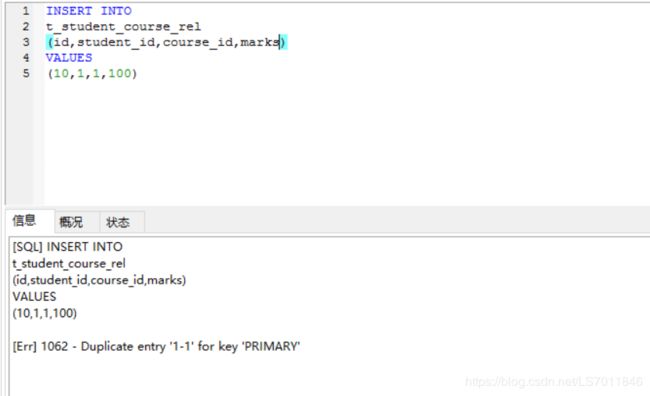
)已经建立联合主键的关系表,在面对两个相同student_id和course_id的数据插入时,会抛出主键重复的异常,如下图所示
表中已经有了student_id=1和course_id=1的数据,如果再插入便会报错。

2.使用唯一索引限制
如果当前的表已经运行了很久,不适合再去修改表结构时,或者是表中的主键已经确定为其他字段时,便不再适合使用联合主键,则可以考虑对表增加非聚集索引之一的唯一索引对关系表做出限制。即将student_id和course_id建立表的唯一索引。其中sql如下:
CREATE TABLE `t_student_course_rel ` (
`id` bigint(20) NOT NULL ,
`student_id` bigint(20) NOT NULL ,
`course_id` bigint(20) NOT NULL ,
`marks` int(11) NOT NULL DEFAULT 0 ,
PRIMARY KEY (`id`),
UNIQUE INDEX `in_rel` (`student_id`, `course_id`) USING BTREE
)(如果表已经建成,则直接用sql加唯一索引即可)
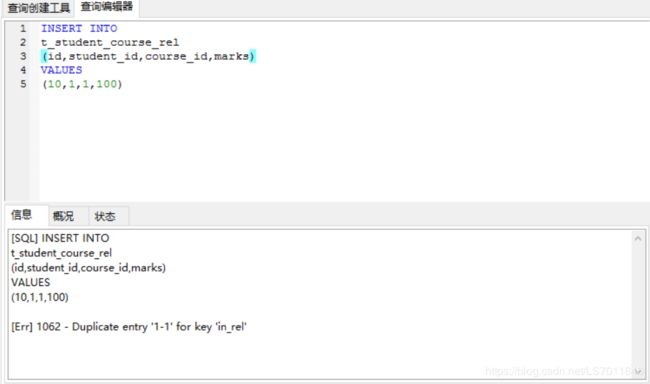
同样,已经建立联合唯一索引的关系表,在面对两个相同student_id和course_id的数据插入时,会抛出主键重复的异常,即可解决。
三、结论
对关系表中的单个关系的两个外键id做出联合主键以及联合唯一索引,可以有效限制关系表中错误数据以及异常数据的产生(不管是中期的数据插入,还是后期的数据迁移,都能有效地做出限制),而两者的选择就看需求了。
1.联合主键:在创建表的初期就考虑到这个问题,可以对两个外键id做联合主键,相对于索引来说会省去一些空间。
2.唯一索引:可以在后期加入索引,对两个外键id做唯一索引,不会修改表结构,但相对来说会增加一些空间。