AI 自动研发机器学习系统,DeepMind 让算法学习强化学习
人工智能研发的一个大方向是用AI系统来自动化开发AI系统。虽然这一目标尚未实现,但目前的进展让已足够令人人震惊。本文介绍了最新的一些进展,包括伯克利让算法自我优化、MIT自动生成神经网络架构,以及在这方面走得最远的 DeepMind 让算法“学习强化学习”。
2011年硅谷最有影响的技术投资人 Marc Andreessen 一篇“Why Software Is Eating The World”震撼业界。6 年后,移动、云计算和大数据三大技术浪潮已经强烈地改变了很多行业。
新的技术浪潮已经袭来,那就是人工智能。近年来,人工智能的人才大战已经愈演愈烈,机器学习专家的薪酬也水涨船高,到了惊人的水平。
然而,顶尖的人工智能专家们最近发现,他们最困难的工作之一——设计机器学习系统本身,也有可能通过AI系统自动完成。
用 Google 技术大神 Jeff Dean 最近在 AI Frontiers 会议上的话说,目前人工智能领域解决问题所需的就是机器学习技术、计算和数据,我们能否减少对这种技术本身的需求呢?他认为是可能的。“自动机器学习”这个方向正是他来到的 Google Brain 团队正在积极探索的最有希望的领域之一。
而 DeepMind 的研究发现,这方面的进展还可以减少深度学习系统对数据量的要求。这在无人驾驶汽车等场景非常有用。
Yoshua Bengio 则指出,目前的研究对计算能力的要求太高(Google Brain 的实验用了800个高配置GPU),所以还不太实用。但这确实是一个令人兴奋的方向。
1月18日,Tom Simonite 在《MIT Technology Review》发表的文章 “AI Software Learns to Make AI Software”,收集了 Google Brain、OpenAI、MIT、Berkeley 和 DeepMind 等在 learning to learn 领域的最新的研究成果。
TechCrunch 接着发表的文章则总结说,在不少场景下,AI系统自己开发的AI系统,已经赶上甚至超过了人类专家。这将大大加快 AI 技术民主化的进程。而稀缺的人类研究资源也可以释放出来,转而去研究更重要的问题。
接下来,我们一起深入地分析相关论文,看一看这方面的进展已经到了什么程度。
让算法自己写代码
让算法自己写代码的努力并不止于学术界。国外著名科技记者 Steven Levy 去年 6 月在他刊于 BackChannel 的文章《谷歌如何将自己重塑为一家“AI 为先”的公司》(How Google Is Remaking Itself As A "Machine Learning First" Company)中提到,谷歌大脑负责人 Jeff Dean 表示,如果现在让他改写谷歌的基础设施,大部分代码都不会由人编码,而将由机器学习自动生成。
“以前,我们可能在系统的几个子组件中使用机器学习,”Jeff Dean 说:“现在我们实际上使用机器学习来替换整套系统,而不是试图为每个部分制作一个更好的机器学习模型。”
谷歌的代码bug预测系统,使用一个得分算法,随着commits变得越来越旧,它们的价值越来越小。
谷歌已经开发了一个 bug 预测程序,使用机器学习和统计分析,来判断某一行代码是否存在瑕疵。
谷歌工程师、W3C的联合主席 Ilya Grigorik 也开发了一个开源版本的 bug 预测工具,目前已被下载近 3 万次。开源地址:https://github.com/igrigorik/bugspots
让代理自己设计神经网络
差不多同一时间,MIT 媒体实验室的研究人员则提出了自动生成神经网络架构的方法。在论文《Designing Neural Network Architectures using Reinforcement Learning》当中,Bowen Baker 等人提出,目前设计卷积神经网络(CNN)架构需要人的专业知识和劳动,设计新的架构需要经过大量实验手工编码,或者从个别现有的网络架构修改得到。
为此,他们提出一种基于强化学习的元建模方法,以针对给定的学习任务自动生成高性能 CNN 体系结构。代理(agent)遍历可能存在的架构,并且迭代发现在学习任务上具有改进性能的设计。在图像分类基准上,代理所设计的网络(仅由标准卷积层、池化层和完全连接层组成)比使用相同层类型设计的现有网络表现更好,与使用更多复杂层类型的结构相比,结果也不相上下。
将学习算法表示为递归神经网络
再说一下 OpenAI 在这方面的努力。
在前不久提交的论文《RL2: Reinforcement Learning via Slow Reinforcement Learning》中,OpenAI 的 Yan Duan 等人提出,将学习算法表示为一个递归神经网络(RNN),并从数据中学习。这种方法称为 RL2,研究人员让算法被编码在 RNN 的权重中,通过通用的“慢”(“slow”)RL 算法慢慢学习(而没有从开始就设计一个“快的” RL 算法)。
RNN 接收典型的RL算法所能接收的所有信息,包括观察、动作、奖励和终止标志,RNN在给定的马尔科夫决策过程(MDP)中保持其状态。RNN的激活存储“快”RL算法的状态于当前的MDP中。OpenAI 的研究负责人 Ilya Sutskever 和伯克利的 Pieter Abbeel 也是论文作者。
深度增强学习(deep RL)已经在自动学习复杂行为方面取得成功。然而,该学习过程需要大量的试验。相比之下,得益于对世界的先有知识,动物仅仅需要几个试验就能学会新的任务。本论文试图弥合这一差距。
研究人员用实验评估了RL2在小规模和大规模问题上的表现。“在小规模问题上,我们训练它来解决随机生成的多臂赌博机问题(multi-armed bandit problems)和有限MDP。RL2被训练好后,它在新的MDP问题上的表现接近人类设计的最优算法。在大规模问题上,我们用基于视觉的导航任务测试RL2,并扩展到高维问题。”
DeepMind 一直在努力:利用强化学习,打造能学习和推理的机器
神经程序解释器(NPI)
2015 年,DeepMind 团队开发了一个“神经编程解释器”(NPI),能自己学习并且编辑简单的程序,排序的泛化能力也比序列到序列的 LSTM 更高。描述这项研究的论文《神经程序解释器》(Neural Programmer-Interpreters),被评选为 ICLR'16 最佳论文。
NPI 是一种递归性的合成神经网络,能学习对程序进行表征和执行。NPI 的核心模块是一个基于 LSTM 的序列模型,这个模型的输入包括一个可学习的程序嵌入、由调用程序传递的程序参数和对环境的特征表征。这个核心模块的输出包括,一个能指示接下来将调用哪个程序的键、一个经典算法程序的参数,以及一个能指示该程序是否该停止的标记。除了递归性内核外,NPI 构架还包括一个内嵌的可学习程序的键值内存。这种程序-内存的结构对于程序的持续学习和重用是极其重要的。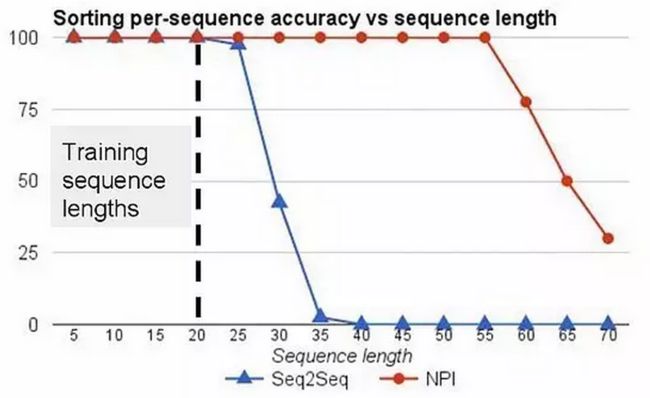
NPI 与 序列到序列 LSTM 对不同长度的序列进行排序的准确率对比,最长序列含有20个数组。
NPI 有三个拥有学习能力的部件:一是任务未知的递归内核,二是持续键值程序内存,三是基于特定领域的编码器,这个编码器能在多个感知上有差异的环境中让单一的 NPI 提供截然不同的功能。通过合成低层程序表达高层程序,NPI 减少了样本复杂性,同时比序列到序列的 LSTM 更容易泛化。通过在既有程序的基础上进行建构,程序内存能高效学习额外的任务。NPI 也可以利用环境缓存计算的中间结果,从而减轻递归隐藏单元的长期存储负担。
当时,DeepMind 团队并未使用无监督学习的方法的训练 NPI,其模型也只能学习合成若干种简单的程序,包括加法、排序和对 3D 模型进行正则化转换。不过,单一 NPI 能学会执行这些程序以及所有 21 个关联子程序。
可微分计算机(DNC)
2016 年 10 月,谷歌 DeepMind 团队在 Nature 发表论文,描述了他们设计的可微分神经计算机(DNC)神经网络模型。DNC 结合神经网络与可读写的外部存储器,能够像神经网络那样通过试错或样本训练进行学习,又能像传统计算机一样处理数据。
在实验中,DNC 能理解家谱、在没有先验知识的情况下计算出伦敦地铁两站之间的最快路线,还能解决拼图迷宫。德国研究者 Herbert Jaeger 评论称,这是目前最接近数字计算机的神经计算系统,该成果有望解决神经系统符号处理难题。

作者在论文摘要中写道,就像传统计算机一样,DNC 能使用外存对复杂的数据结构进行表征及操纵,但同时又像神经网络一样,能够从数据中学会这样做。“使用监督学习训练后,DNC 能够成功回答人工合成的问题……能够学会找到特定的点之间距离最短的路线、从随机生成的图当中推断缺少的连接等任务,之后再将这种能力泛化,用于交通线路图、家谱等特定的图。使用强化学习训练后,DNC 能够完成移动拼图的益智游戏,其中符号序列会给出不停变化的游戏目标。综上,我们的成果展示了 DNC 拥有解决复杂、结构化任务的能力,这些任务是没有外部可读写的存储器的神经网络难以胜任的”。
深度元强化学习(deep meta-reinforcement learning)
最近,DeepMind 的研究人员还与 UCL 的神经科学家合作,提出让算法《学习强化学习》(Learning to reinforcement learn)。近年来,深加强学习(RL)系统已经在许多富有挑战性的任务领域中获得了超人的性能。然而,这种应用的主要限制是它们对大量训练数据的需求。因此,关键的目前的目标是开发可以快速适应新任务的深度 DL 方法。
“在目前的工作中,我们引入了一种新的方法来应对这种挑战,我们称之为深度元强化学习。以前的工作表明,递归网络(RNN)可以在完全监督的上下文中支持元学习。我们将这种方法扩展到 RL 设置。由此出现的是一个使用一种 RL 算法训练的系统,但是其递归的动力却来自另一个完全独立的 RL 过程。这个独立的、习得的 RL 算法可以以任意方式与原始算法不同。重要的是,因为它是经过训练习得的,这个算法在配置上(configured)利用训练领域中的结构。”

论文描述了研究人员在一系列共计 7 个概念验证实验中证明了上述观点,每个实验都检查深度元 RL 的一个关键方面。
开发机器学习程序员都面临失业的风险?
随着越来越多的这类技术变得成熟,机器将会在各种各样的任务上超越人类。那么,机器为什么不能理解自己呢?更重要的是,一旦机器做到这一步,在软件能够发挥作用的所有领域,都将会经历一场颠覆性的变革。
人工智能的核心挑战之一便是教会机器学习新的程序、从既有程序中快速地编写新程序,并自动在一定条件下执行这些程序以解决广泛种类的任务。
这是否意味着就连开发机器学习的程序员都面临失业的危险?
答案是否定的,至少目前为止——创造出性能等同或超越人类设计的机器学习程序,需要大量的计算力,比如 Google Brain 使用 AI 开发的图像识别系统,虽然击败了人类,但却需要超大的 GPU 集群,这从多种意义上而言都是相当大的一笔开销。
但尽管如此,使用 AI 开发 AI 软件的优点十分明显,而且大量的资源开销也可以通过种种办法减少。将开发机器学习系统的重任交给机器,有助于解决该领域拥有专业知识的人才严重短缺。AI 产业专家指出,开发机器学习软件需要在一开始就投入巨大的人力,但将其中一些工作交给其他机器学习系统可以大大减少开始和整个过程中所需的人力。
目前,从学术界和初创公司大力收割机器学习人才的争夺战正在加剧。此外,让机器自己设计机器可以解放人类研究员,让他们把时间用于解决更重要的问题,而不是仅仅使用大量数据集反复训练 AI 系统。
让 AI 不断优化 AI 还有另外一个潜在的好处,那就是改善 AI 系统的学习曲线,这样就能减少产生有意义结果所需的数据量。这一方面有助于极大地促进像自动驾驶汽车系统这样的产业发展——对于开发自动驾驶技术而言,数百万英里的行驶里程只能算收集真实世界数据的开始——另一方面则会大大缩短 AI 产品上市的时间。
但是,所有这些都不能消除机器学习技术被算法取代的可能。