Importance Weighted Adversarial Nets for Partial Domain Adaptation 使用加权对抗网络实现部分域适应
论文地址:https://arxiv.org/pdf/1803.09210。
简介
这篇文章介绍了一种深度域适应方法,构造了两个网络以及两个判别器,两个网络作用是分别提取源域和目标域的,然后一个判别器用于获取源域样本的重要性权重,第二个分类器使用经过加权的源域样本特征和目标域数据进行优化作为目标分类器。该方法的思路与之前的SAN[2]类似,不同的是SAN中只使用了一个网络,源域和目标域的数据输入到同一个网络中,然后网络提取的特征输入到与源域类别个数相同个判别器中,最后使用这些判别器加权后的结果以及目标判别器结果用于优化网络,而在本文的方法中将源域和目标域分别输入到两个网络,并且不分享参数以提取出更多的域特定特征,并且只使用了两个判别器来进行样本的加权和目标分类器的优化。网络框架如下:
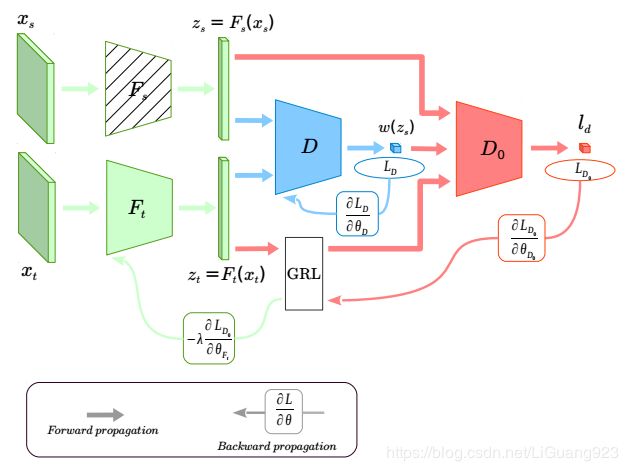
Importance Weighted Adversarial Nets
如上图所示,绿色部分是源域和目标域的特征提取器,有斜杠的块表示的是经过预训练的网络,同时在训练阶段参数固定不动。蓝色部分是第一个域判别器,用于获取源域样本的重要性权重。红色部分是第二个域判别器,其通过经过加权的源域样本和目标域样本minimax网络。
应用场景:源域 D s \mathcal{D}_s Ds有充足的带标签样本,目标域 D t \mathcal{D}_t Dt中则全是无标签样本。其中源域和目标域的特征空间也相同: X s = X t \mathcal{X}_s=\mathcal{X}_t Xs=Xt,并且目标域的标签空间为源域标签空间的一个子集: Y t ⊂ Y s \mathcal{Y}_t \subset \mathcal{Y}_s Yt⊂Ys。
如上图,网络需要优化的有三个部分:1.特征提取器的参数 2.第一个域判别器 D D D 3.第二个判别器 D 0 D_0 D0 我们也将从三个方面介绍网络。
优化域判别器D
判别器D的作用只是用于获取基于当前目标域特征,源域特征的重要性权重。该域判别器的思想与生成对抗网络中判别器的思想类似,当判别器根据特征提取器提取出来的特征判别出接近1时,那么就认为这些特征属于源域中与目标域数据较为互斥的特征,分配给这些特征的权值就会较小,而当域判别器D的判别器接近0时,就认为这些源域特征与目标域特征接近,并对目标分类器有帮助,则分配给这些特征的权重就会较大,而这些权重将用于第二个判别器 D 0 D_0 D0中对源域特征进行加权。另外,域判别器D的优化则是根据前面两个特征提取器的效果进行,判别器D的损失函数如下:
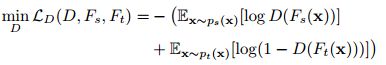
在上图网络框架中标识了 F s ( x ) F_s(x) Fs(x)以及 F t ( x ) F_t(x) Ft(x)代表的内容,并结合上图网络框架可以看出判别器D的损失值就是根据判别器对两个特征提取器的判别效果加成得出。另外,关于源域样本的权重分配如下:
ω ~ ( z ) = 1 − D ( z ) \tilde{\omega}(z) = 1-D(z) ω~(z)=1−D(z)
由此,当判别器D的结果越接近1,分配的权重越低,越接近0,分配的权重越高,也表示源域中的样本对目标域分类越有用。
值得注意的是,D的损失不用于后向传播更新特征提取器 F t F_t Ft,因为D的梯度是从没有经过加权的源域样本学习到的,这将不能给优化 F t F_t Ft提供一个好的指示。
优化判别器 D 0 D_0 D0
判别器 D 0 D_0 D0则通过经过加权的源域样本和目标域样本进行训练,并根据 D 0 D_0 D0的结果优化 F t F_t Ft,因为这里的判别器D的结果是通过与目标域相关的源域数据以及目标域本身的数据得来的,所以该结果与 F t F_t Ft有很大的指导作用。而在 D 0 D_0 D0中参考GAN中的思想,最大化判别器 D 0 D_0 D0的损失,最小化生成器 F t F_t Ft的损失,其损失函数如下:
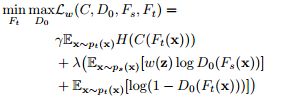
其中第一项为一个正则化项,使用的熵最小化原则,希望通过熵最小化来促进类别之间的低密度分离(这在SAN中同样用到)。第二项则为判别器对源域样本结果进行权重化处理,第三项则为判别器对目标域数据的结果损失。后面两项与第一个判别器D类似,只不过加上了权重和一个正则化项,然后参数 λ 、 γ \lambda、\gamma λ、γ是权重参数。为了解决最大最小优化,作者使用了GRL层[3]来完成(同样在SAN中用到)。
优化源域特征提取器 F s F_s Fs
因为网络的侧重点是在目标域上的优化,所以在网络中首先对源域特征提取器 F s F_s Fs进行了一个预训练,并在网络训练阶段固定 F s F_s Fs的参数,而这个预训练就是通过源域的标签对 F s F_s Fs进行有监督训练,优化方式大家应该都比较熟悉:

其中C为有监督分类器,公式比较简单,就不做介绍啦。
总结
该方法可以看做是在SAN基础上的一个优化----源域和目标域的特征提起之间分开进行,并没有进行参数共享,以提取到更多的域特定特征,同时网络的结构比SAN的简单,解决了源域样本筛选和部分迁移的问题。
参考
[1] Zhang J, Ding Z, Li W, et al. Importance Weighted Adversarial Nets for Partial Domain Adaptation[J]. 2018.
[2] Cao Z, Long M, Wang J, et al. Partial Transfer Learning with Selective Adversarial Networks[J]. 2017.
[3] Ganin Y, Lempitsky V. Unsupervised Domain Adaptation by Backpropagation[J]. 2015:1180-1189.