爬虫——scrapy框架爬取多个页面电影的二级子页面的详细信息
文章目录
- 需求:
- 总结:
- 代码:
- movieinfo.py
- items.py
- middleware.py
- pipelines.py
- 结果:
- 附加:
- crawlspider可以改进:
需求:
- scrapy框架,爬取某电影网页面的每个电影的一级页面的名字
- https://www.55xia.com/
- 爬取每部电影二级页面的详细信息
- 使用代理ip
- 保存日志文件
- 存为csv文件
总结:
1、xpath解析使用extract()的各种情况分析
https://blog.csdn.net/nzjdsds/article/details/77278400
2、xpath用法注意的点:
div[not(contains(@class,"col-xs-12"))]
class属性不包括"col-xs-12"的div标签
https://blog.csdn.net/caorya/article/details/81839928?utm_source=blogxgwz1
3、二次解析时,用meta参数字典格式传递第一次解析的参数值。
# meta 传递第二次解析函数
yield scrapy.Request(url=url, callback=self.parse_detail, meta={'item': item})
4、存为csv文件:
import csv
csv.writer
writerow
https://blog.csdn.net/qq_40243365/article/details/83003161
5、空行加参数newline='',
self.f=open('./movie.csv','w',newline='', encoding='utf-8')
6、伪装UA,保存日志,编码格式
settings里设置
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36'
FEED_EXPORT_ENCODING = 'utf-8-sig'
LOG_LEVEL = 'ERROR'
LOG_FILE = 'log.txt'
ROBOTSTXT_OBEY = False
7、代理ip中间件
class MyMiddleware(object):
def process_request(self, request, spider):
request.meta['proxy'] = 'https://157.230.150.101:8080'
settings设置:
DOWNLOADER_MIDDLEWARES = {
'movie.middlewares.MyMiddleware': 543,
}
代码:

movieinfo.py
import scrapy
from movie.items import MovieItem
class MovieinfoSpider(scrapy.Spider):
name = 'movieinfo'
# allowed_domains = ['www.movie.com']
start_urls = ['https://www.55xia.com/movie']
page = 1
base_url = 'https://www.55xia.com/movie/?page={}'
# 解析二级子页面
def parse_detail(self, response):
# 导演可能不止一人,不用extract_first(),拼接成字符串
directors = response.xpath(
'/html/body/div[1]/div/div/div[1]/div[1]/div[2]/table/tbody/tr[1]/td[2]//a/text()').extract()
directors = " ".join(directors)
movieType = response.xpath(
'/html/body/div[1]/div/div/div[1]/div[1]/div[2]/table/tbody/tr[4]/td[2]/a/text()').extract_first()
area = response.xpath(
'/html/body/div[1]/div/div/div[1]/div[1]/div[2]/table/tbody/tr[5]/td[2]//text()').extract_first()
time = response.xpath(
'/html/body/div[1]/div/div/div[1]/div[1]/div[2]/table/tbody/tr[7]/td[2]//text()').extract_first()
score = response.xpath(
'/html/body/div[1]/div/div/div[1]/div[1]/div[2]/table/tbody/tr[9]/td[2]//a/text()').extract_first()
# 取出meta的item
item = response.meta['item']
print('二级子页面:', item['name'])
item['directors'] = directors
item['movieType'] = movieType
item['area'] = area
item['time'] = time
item['score'] = score
yield item
def parse(self, response):
"""
获取超链接
导演,编剧,主演,类型,地区,语言,上映时间,别名,评分
:param response:
:return:
"""
div_list = response.xpath('/html/body/div[1]/div[1]/div[2]/div[not(contains(@class,"col-xs-12"))]')
for div in div_list:
name = div.xpath('./div/div/h1/a/text()').extract_first()
print('已找到:',name)
url = div.xpath('.//div[@class="meta"]/h1/a/@href').extract_first()
url = "https:" + url
# 实例化item对象并存储
item = MovieItem()
item['name'] = name
# meta 传递第二次解析函数
yield scrapy.Request(url=url, callback=self.parse_detail, meta={'item': item})
# 完成每页之后开始下一页
if self.page < 3:
self.page += 1
new_url=self.base_url.format(self.page)
yield scrapy.Request(url=new_url, callback=self.parse)
items.py
import scrapy
class MovieItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field()
directors = scrapy.Field()
movieType = scrapy.Field()
area = scrapy.Field()
time = scrapy.Field()
score = scrapy.Field()
middleware.py
class MyMiddleware(object):
def process_request(self, request, spider):
request.meta['proxy'] = 'https://157.230.150.101:8080'
pipelines.py
import csv
class MoviePipeline(object):
def open_spider(self, spider):
print('开始存储')
self.f=open('./movie.csv','w',newline='', encoding='utf-8')
self.writer= csv.writer(self.f)
self.writer.writerow(['name','directors','movieType','area','time','score'])
def process_item(self, item, spider):
print('正在写入')
self.writer.writerow([item['name'],item['directors'],item['movieType'],item['area'],item['time'],item['score']])
return item
def close_spider(self, spider):
self.f.close()
print('保存完成')
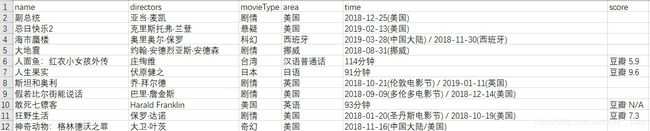
结果:
附加:
Excel和CSV格式文件的不同之处
https://blog.csdn.net/weixin_39198406/article/details/78705016
crawlspider可以改进:
crawlspider更加高效,直接写个正则,可以提取页面符合规则的所有url,直接解析。
- 创建工程scrapy startproject 工程名
- cd 该文件夹
- 创建爬虫文件 scrapy genspider -t crawl 爬虫文件名 网址
- 主要是rule比较牛

rules = (
Rule(LinkExtractor(allow=r'/movie/\?page=\d+'), callback='parse_item', follow=False),
)
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class TtSpider(CrawlSpider):
name = 'tt'
# allowed_domains = ['www.baidu.com']
start_urls = ['https://www.55xia.com/movie']
rules = (
Rule(LinkExtractor(allow=r'/movie/\?page=\d+'), callback='parse_item', follow=False),
)
'''
LinkExtractor(allow=r'Items/') 实例化一个链接提取器的对象,根据allow的正则表达式来提取指定内容。
Rule()实例化一个规则解析器对象,对Link提取的链接发起请求,获取链接对应的页面内容,交给callback解析
follow 表示是否在提取到的url链接页面再次以相同规则提取,
scrapy 最后会去重
# follow=True 所有的页面数据。
'''
def parse_item(self, response):
# i = {}
#i['domain_id'] = response.xpath('//input[@id="sid"]/@value').extract()
#i['name'] = response.xpath('//div[@id="name"]').extract()
#i['description'] = response.xpath('//div[@id="description"]').extract()
# return i
'''
print(response)打印的是提取器提取到的链接,但是可以直接response.xpath解析链接指向的页面!
:param response:
:return:
'''
title=response.xpath('/html/body/div[1]/div[1]/div[2]/div[1]/div/div/h1/a/text()').extract_first()
print(title)