简历爬取系列(二)——破解58同城简历中的加密字符
直接目的:针对58同城简历数据中的加密字符,进行破解,以还原其对应的真实文字。
根本目的:爬取58同城网站上的个人简历,进行信息储备。
现有环境:安装python3.6的五服务器。
下面就开始吧。
如图1所示,是58同城的简历页面。从页面中可以看出,网站针对职位进行了简历的分类。
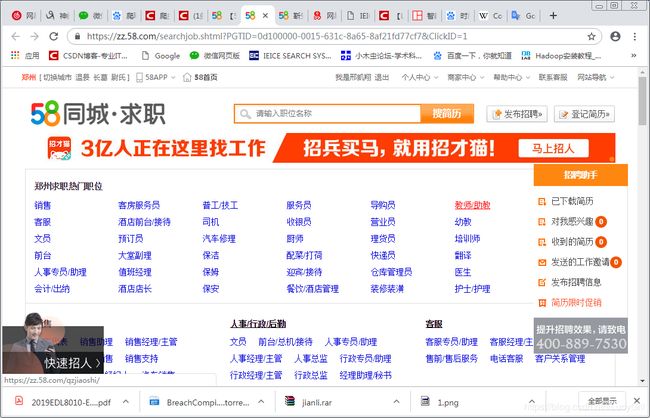
已左一的销售职位为例进行爬取。单击“销售”,发现有郑州不同人的简历信息。如图2所示。首先想通过图2所示的界面进行爬虫,发现有些字符在网页源码中无法显示。如图3所示,“詹先生”的“生”在源码中无法显示。
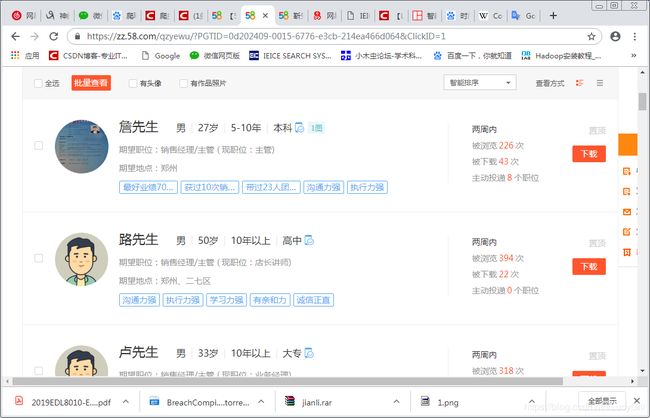
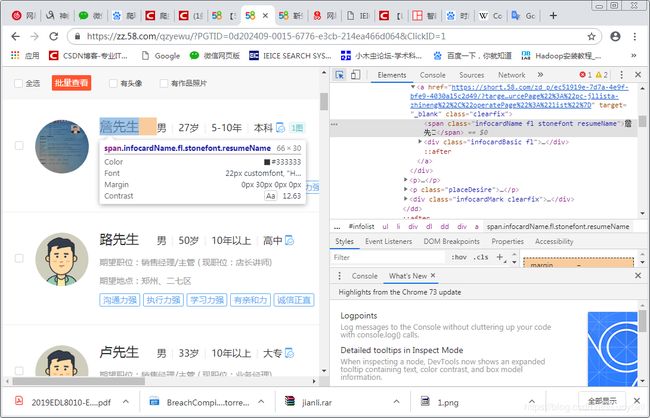
进一步,查看詹先生的具体信息,如图4所示。发现具体人名可以显示,但人名下方最关键的信息字符都无法在源码中显示。这应该是网站的反爬虫机制。
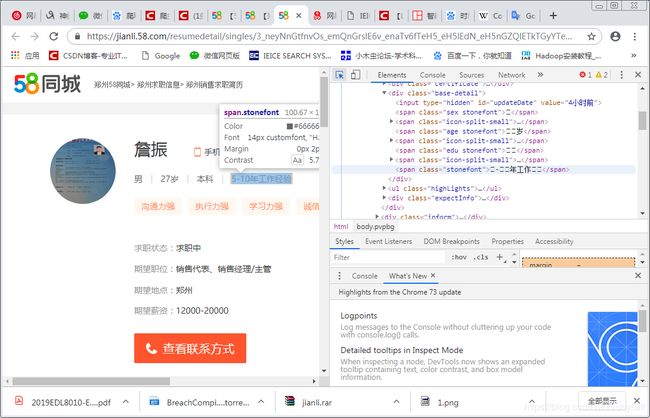
想要处理这种字符,参考了一个博客,据说可以帮忙爬取。(定制简历采集软件wechat联系13939147257)为了给组织省钱,决定先问百度怎么处理这种被加密的字符。
参考了另一篇博客(https://blog.csdn.net/m0_37156322/article/details/84658872),大致知道了字符无法显示的原因:网站通过base64对字体加密,将关键字通过一个特定的字典映射成了乱码的形式。
一般来说,此问题的通用解决办法是找到字体文件,分析文件中的映射关系。一般来说,字体文件都是作为样式加在加密字体的部位。通过观察HTML源码,发现加密字体中都有“stonefont”字样,该字样应该就是加密字体。
接下来,在源码中搜索“stonefont”,找到了加密文件。如图5右半边所示。
然后利用python将图5右侧所示的加密文件进行二进制解码,并利用FontCreater进行查看。解码函数如下所示。查看结果如图6所示。
def make_font_file(base64_string: str):
bin_data = base64.decodebytes(base64_string.encode())
with open('text.otf','wb') as f:
f.write(bin_data)
return bin_data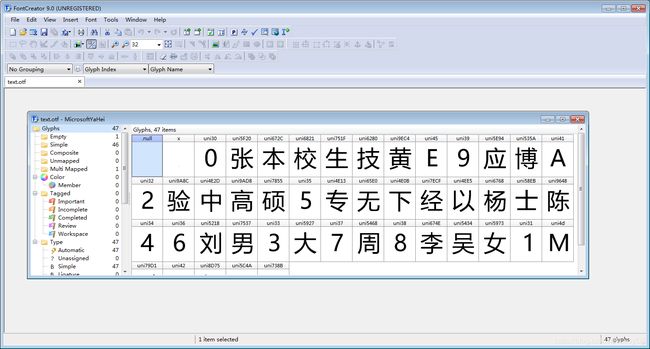
通过上述转化,我们是可以将加密字符进行还原的。接下来,要将二进制文件转化为xml格式,进而在python中得到加密字符与真实字符的对应关系。
FontTools是一套以ttx为核心的工具集,主要功能是处理字体文件。通过对网页源码的分析,我们可以得到网站的加密字体文件。因此,下一步可以利用FontTools将其转化为xml格式,进而得到加密字符对应的真实字符。
- 在python中安装FontTools。 Pip install fonttools
- 引入from fontTools.ttLib import TTFont
from fontTools.ttLib import TTFont
from io import BytesIO
def convert_font_to_xml(bin_data):
# 由于TTFont接收一个文件类型
# BytesIO(bin_data) 把二进制数据当作文件来操作
font = TTFont(BytesIO(bin_data))
font.saveXML("text.xml")
bin_data = make_font_file(base64_str)
convert_font_to_xml(bin_data)
# 获取对应关系
font = TTFont(BytesIO(make_font_file(base64_str)))
uniList = font['cmap'].tables[0].ttFont.getGlyphOrder()
c = font['cmap'].tables[0].ttFont.tables['cmap'].tables[0].cmap
# c = font.getBestCmap()
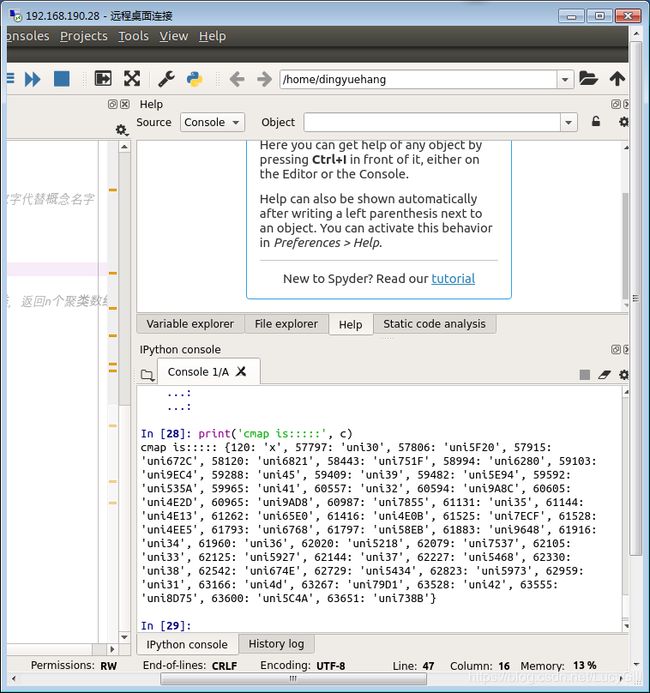
print('cmap is:::::', c)
打印结果如图7所示。键表示乱码字符,值表示乱码对应的真实Unicode字符。
通过上述操作,就可以对加密字符进行解码。
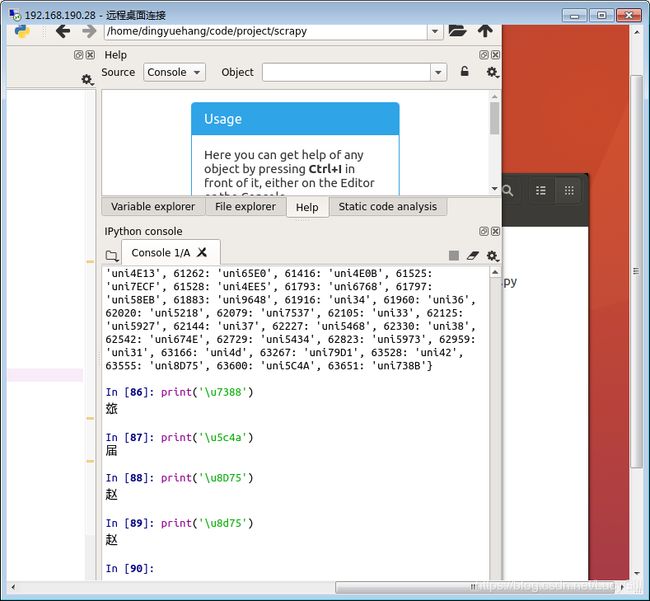
可以在python中直接打印出Unicode字符对应的汉字,如图8所示。
现在,针对加密字符,我们已经可以通过获得的加密-解密表,将其破解。但是,如何判定网页中的字符是否为加密字符呢?此为后话,将在下一篇文章中进行解决。