HDFS 之 NameNode 和 SecondaryNameNode 关系解析
1.NN和2NN工作机制
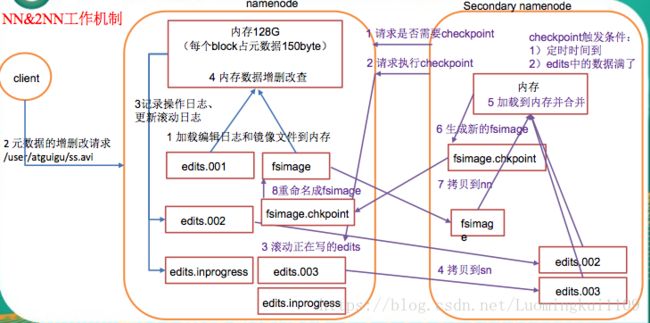
(1) 第一阶段:NameNode启动
① 第一次启动NameNode格式化后,创建fsimage和edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
② 客户端对元数据进行增删改的请求。
③ NameNode记录操作日志,更新滚动日志。
④ NameNode在内存中对数据进行增删改查。
(2) 第二阶段:Secondary NameNode工作
① Secondary NameNode询问NameNode是否需要checkpoint。直接带回NameNode是否检查结果。
② Secondary NameNode请求执行checkpoint。
③ NameNode滚动正在写的edits日志。
④ 将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode。
⑤ Secondary NameNode加载编辑日志和镜像文件到内存,并合并。
⑥ 生成新的镜像文件fsimage.chkpoint。
⑦ 拷贝fsimage.chkpoint到NameNode。
⑧ NameNode将fsimage.chkpoint重新命名成fsimage。
2.Fsimage和Edits解析
(1) 概念
namenode被格式化之后,将在/opt/module/hadoop-2.7.2/data/tmp/dfs/name/current 目录中产生如下文件:
edits_0000000000000000000
fsimage_0000000000000000000.md5
seen_txid
VERSION
① Fsimage文件:HDFS文件系统元数据的一个永久性的检查点,其中包含HDFS文件系统的所有目录和文件idnode的序列化信息。
② Edits文件:存放HDFS文件系统的所有更新操作的路径,文件系统客户端执行的所有写操作首先会被记录到edits文件中。
③ seen_txid文件: seen_txid文件保存的是一个数字,就是最后一个edits_的数字
④ VERSION:记录了nameNode的相关信息
namespaceID=1660707761
clusterID=CID-ae140ab0-f35c-42e4-bace-99e391612bd5
cTime=0
storageType=NAME_NODE
blockpoolID=BP-513901284-10.211.55.103-1526360404128
layoutVersion=-63
⑤ 注意:每次NameNode启动的时候都会将fsimage文件读入内存,并从00001开始到seen_txid中记录的数字依次执行每个edits里面的更新操作,保证内存中的元数据信息是最新的、同步的,可以看成NameNode启动的时候就将fsimage和edits文件进行了合并。
(2) oiv查看fsimage文件
① 查看oiv和oev命令
[luomk@hadoop102 current]$ hdfs
oiv apply the offline fsimage viewer to an fsimage
oev apply the offline edits viewer to an edits file
② 基本语法
hdfs oiv -p 文件类型 -i镜像文件 -o 转换后文件输出路径
③ 案例实操
[luomk@hadoop102 current]$ pwd
/opt/module/hadoop-2.7.2/data/tmp/dfs/name/current
[luomk@hadoop102 current]$ hdfs oiv -p XML -i fsimage_0000000000000000025 -o /opt/module/hadoop-2.7.2/fsimage.xml
[luomk@hadoop102 current]$ cat /opt/module/hadoop-2.7.2/fsimage.xml
将显示的xml文件内容拷贝到eclipse中创建的xml文件中,并格式化。部分显示结果如下。
(3) oev查看edits文件
① 基本语法
hdfs oev -p 文件类型 -i编辑日志 -o 转换后文件输出路径
② 案例实操
[luomk@hadoop102 current]$ hdfs oev -p XML -i edits_0000000000000000012-0000000000000000013 -o /opt/module/hadoop-2.7.2/edits.xml
[luomk@hadoop102 current]$ cat /opt/module/hadoop-2.7.2/edits.xml
将显示的xml文件内容拷贝到eclipse中创建的xml文件中,并格式化。显示结果如下。
3.checkpoint设置
在 hdfs-default.xml 配置文件中
(1) 通常情况下,SecondaryNameNode每隔一小时执行一次。
(2) 一分钟检查一次操作次数,当操作次数达到1百万时,SecondaryNameNode执行一次。
4.NameNode故障处理
NameNode故障后,可以采用如下两种方法恢复数据。
方法一:将SecondaryNameNode中数据拷贝到NameNode存储数据的目录;
(1) kill -9 namenode进程
(2) 删除NameNode存储的数据(/opt/module/hadoop-2.7.2/data/tmp/dfs/name)
[luomk@hadoop102 hadoop-2.7.2]$ rm -rf /opt/module/hadoop-2.7.2/data/tmp/dfs/name/*
(3) 拷贝SecondaryNameNode中数据到原NameNode存储数据目录
[luomk@hadoop102 dfs]$ scp -r luomk@hadoop104:/opt/module/hadoop-2.7.2/data/tmp/dfs/namesecondary/* ./name/
(4) 重新启动namenode
[luomk@hadoop102 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start namenode
方法二:使用-importCheckpoint选项启动NameNode
守护进程,从而将SecondaryNameNode中数据拷贝到NameNode目录中。
(1) 修改hdfs-site.xml中的
(2) kill -9 namenode进程
(3) 删除NameNode存储的数据(/opt/module/hadoop-2.7.2/data/tmp/dfs/name)
[luomk@hadoop102 hadoop-2.7.2]$ rm -rf /opt/module/hadoop-2.7.2/data/tmp/dfs/name/*
(4) 如果SecondaryNameNode不和NameNode在一个主机节点上,需要将SecondaryNameNode存储数据的目录拷贝到NameNode存储数据的平级目录,并删除in_use.lock文件。
[luomk@hadoop102 dfs]$ scp -r luomk@hadoop104:/opt/module/hadoop-2.7.2/data/tmp/dfs/namesecondary ./
[luomk@hadoop102 namesecondary]$ rm -rf in_use.lock
[luomk@hadoop102 dfs]$ pwd
/opt/module/hadoop-2.7.2/data/tmp/dfs
[luomk@hadoop102 dfs]$ ls
data name namesecondary
(5) 导入检查点数据(等待一会ctrl+c结束掉)
[luomk@hadoop102 hadoop-2.7.2]$ bin/hdfs namenode -importCheckpoint
(6) 启动namenode
[luomk@hadoop102 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start namenode
5.NameNode多目录配置
本人觉得没有什么必要,因为生成了配置之后在 /opt/module/hadoop-2.7.2/data/tmp/dfs 目录下生成了完全一样的两个文件,之所以说,是因为想和后面学习的DataNode多目录配置进行区分
(1) NameNode的本地目录可以配置成多个,且每个目录存放内容相同,增加了可靠性。
(2) 具体配置如下:
① 在hdfs-site.xml文件中增加如下内容
② 停止集群,删除data和logs中所有数据。
[luomk@hadoop102 hadoop-2.7.2]$ rm -rf data/ logs/
[luomk@hadoop103 hadoop-2.7.2]$ rm -rf data/ logs/
[luomk@hadoop104 hadoop-2.7.2]$ rm -rf data/ logs/
③ 格式化集群并启动。
[luomk@hadoop102 hadoop-2.7.2]$ bin/hdfs namenode –format
[luomk@hadoop102 hadoop-2.7.2]$ sbin/start-dfs.sh
④ 查看结果
[luomk@hadoop102 dfs]$ ll
总用量 12
drwx------. 3 luomk luomk 4096 6月 28 17:33 data
drwxrwxr-x. 3 luomk luomk 4096 6月 28 17:33 name
drwxrwxr-x. 3 luomk luomk 4096 6月 13 17:01 name2
You have new mail in /var/spool/mail/luomk