Druid 基本介绍
1.概述
随着互联网快速发展,数据量增长快,达到TB、PB,以交通车流量为例,如湖南省每月的车辆流量至少达到4亿,这个数据量远不止如此。数据量如此大,如何满足后期分析,传统面向OLTP型数据库(ORACLE、MYSQL等)无法要求,渐渐开始转向OLAP,如GreenPlum等,虽然很多OLAP数据库吸收分布式计算思想,数据达到20亿以上后,进行Count、聚合等操作性能仍然达不到客户实时分析要求。
虽然相关大数据框架及组件已经很流行:Hadoop(离线分析)、Spark、storm、Hive、Impala、Hbase等,Hadoop生态系统大庞大,Spark一站式安装部署,但是满足实时分析还需借助其它组件、开发要求很高。
Druid是一个为大型冷数据集上实时探索查询而设计的开源数据分析和存储系统,提供极具成本效益并且永远在线的。尤其是当发生代码部署、机器故障以及其他产品系统遇到宕机等情况时,Druid仍能够保持100%正常运行。创建Druid的最初意图主要是为了解决查询延迟问题,当时试图使用Hadoop来实现交互式查询分析,但是很难满足实时分析的需要。而Druid提供了以交互方式访问数据的能力,并权衡了查询的灵活性和性能而采取了特殊的存储格式。
2.大数据分析和Druid
大数据一直是近年的热点话题,随着数据量的急速增长,数据处理的规模也从GB 级别增长到TB 级别,很多图像应用领域已经开始处理PB 级别的数据分析。大数据的核心目标是提升业务的竞争力,找到一些可以采取行动的洞察(Actionable Insight),数据分析就是其中的核心技术,包括数据收集、处理、建模和分析,最后找到改进业务的方案。
最近一两年,随着大数据分析需求的爆炸性增长,很多公司都经历过将以关系型商用数据库为基础的数据平台,转移到一些开源生态的大数据平台,例如Hadoop 或Spark 平台,以可控的软硬件成本处理更大的数据量。Hadoop 设计之初就是为了批量处理大数据,但数据处理实时性经常是它的弱点。例如,很多时候一个MapReduce 脚本的执行,很难估计需要多长时间才能完成,无法满足很多数据分析师所期望的秒级返回查询结果的分析需求。
为了解决数据实时性的问题,大部分公司都有一个经历,将数据分析变成更加实时的可交互方案。其中,涉及新软件的引入、数据流的改进等。数据分析的几种常见方法如下图。
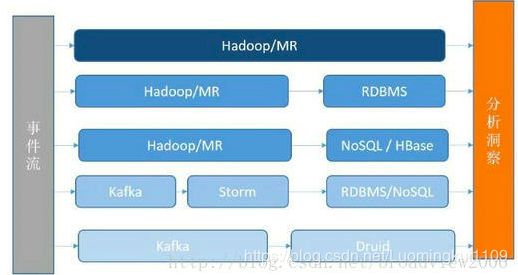
整个数据分析的基础架构通常分为以下几类。
• 使用Hadoop/Spark 的MR 分析。
• 将Hadoop/Spark 的结果注入RDBMS 中提供实时分析。
• 将结果注入到容量更大的NoSQL 中,例如HBase 等。
• 将数据源进行流式处理,对接流式计算框架,如Storm,结果落在RDBMS/NoSQL 中。
• 将数据源进行流式处理,对接分析数据库,例如Druid、Vertica 等。
3.Druid 的三个设计原则
在设计之初,开发人员确定了三个设计原则(Design Principle)。
• 快速查询(Fast Query):部分数据的聚合(Partial Aggregate)+内存化(In-emory)+索引(Index)。
• 水平扩展能力(Horizontal Scalability):分布式数据(Distributed Data)+ 并行化查询(Parallelizable Query)。
• 实时分析(Realtime Analytics):不可变的过去,只追加的未来(Immutable Past,Append-Only Future)。
4.Druid 的技术特点
Druid 具有如下技术特点。
• 数据吞吐量大。
• 支持流式数据摄入和实时。
• 查询灵活且快。
• 社区支持力度大。
5.Druid 基本概念
Druid数据存储结构可以分为三层:DataSourc,Chunk 和 Segment。
DataSource相当于MySQL的按时间分区的表,Chunk相当于MySQL中的按时间分区的表一个分区,但是Chunk不是一个实体,只是一个虚拟的概念,一个Chunk中可以有多个Segment。
在最终落地的文件结构中,一个DataSource占用一个目录,该目录下包含若干个Segment文件,Segment文件名中包含该Segment所属的DataSource名、内含数据的时间区间、分区序号,每个Segment都是一个压缩文件。
Druid的DataSource本身不维护元数据,每一个Segment内部包含了该Segment的所有列信息;一个DataSource下的各Segment的字段可以不同,Druid允许在同一个DataSource下存放不同字段数、字段名的Segment,在做数据入库的时候不做格式合法性检查,查询的时候针对缺失字段提供默认行为(缺失的数值型字段取默认值0,缺失的字符串型字段取默认值null)。
示例:Segment的数据结构

Segment的字段分为三类:
• TimeStamp:以时间序列进行数据分片,所有查询以时间为中心轴。
• Dimension:Druid基于列式存储,查询结果展示列,常用于数据过滤,如示例数据集有四个维度:出版商,广告商,性别和国家。
• Metric:通常用于计算值,操作方法如:COUNT、SUM等。
TimeStamp是固定字段,每个Segment都必须有一个TimeStamp类型字段,字段名可以由用户指定;Dimension是维度字段,可以是数值型、字符串型;Metric是指标字段,必须是数值型。
Druid的数据是按列存储的,每一列的所有数据都存储在一段连续的文件地址内,执行查询的时候只需要访问相关的列即可,而且由于列内数据的存储地址是连续的,所以读取每一列的数据都很快。
TimeStamp和Metric类型的列的存储格式都比较简单,只是单纯地把所有数据按照LZ4的格式压缩存储而已,而Dimension类型的列的存储格式比较复杂,包含如下结构:
(1)一个把所有取值(不管Dimension是什么类型,存储时都被视为是字符串类型)和连续的数字ID一一匹配的字典
(2)该列的所有行的取值对应的数字ID按顺序存储
(3)一个倒排索引字典,key是该列的所有取值,value是一个列表,如果第N行的该列取值为key,则该列表的第N项就是1,否则是0
这些数据结构都是为提高查询速度而服务的,第一条是基础,第二条在处理groupBy/topN这类查询时效率很高,第三条(倒排索引)在处理查询的AND/OR的联合筛选时效率很高。
示例如下:
1: Dictionary that encodes column values
{
"Justin Bieber": 0,
"Ke$ha": 1
}
2: Column data
[0,
0,
1,
1]
3: Bitmaps - one for each unique value of the column
value="Justin Bieber": [1,1,0,0]
value="Ke$ha": [0,0,1,1]
6.Druid 系统的拓展性
• 分布式系统,采用Lambda架构,实时数据和批处理数据解耦;
• 实时处理面向写多读少优化
• 批处理面向读多写少优化
• Shared nothing架构,各个节点有自己的存储和计算能力
• 使用zookeeper协调,使用mysql/postgresql提供元数据存储
7.Druid 的应用场景
从技术定位上看,Druid 是一个分布式的数据分析平台,在功能上也非常像传统的OLAP系统,但是在实现方式上做了很多聚焦和取舍,为了支持更大的数据量、更灵活的分布式部署、更实时的数据摄入,Druid 舍去了OLAP 查询中比较复杂的操作,例如JOIN 等。相比传统数据库,Druid 是一种时序数据库,按照一定的时间粒度对数据进行聚合,以加快分析查询。
在应用场景上,Druid应用最多的是类似于广告分析创业公司Metamarkets中的应用场景,如广告分析、互联网广告系统监控以及网络监控等。当业务中出现以下情况时,Druid是一个很好的技术方案选择:
需要交互式聚合和快速探究大量数据时。
需要实时查询分析时。
具有大量数据时,如每天数亿事件的新增、每天数10T数据的增加。
对数据尤其是大数据进行实时分析时。
需要一个高可用、高容错、高性能数据库时。