猪八戒网DevOps容器云与流水线
项目容器化改造
![]()
猪八戒网是一家成立有12年的互联网公司,历史包袱较多,最初以PHP语言为主,前几年在微服务化的趋势下,进行了SOA微服务化的改造,逐渐转向了以Java和Node.js为主的技术形态,公司从14年开始进行容器的研究与实践,于16年以Kubernetes为编排平台,将业务容器运行于生产环境中。
也得益于这些改造,推动了项目容器化的进展。初期Kubernetes对有状态应用的支持不是很好,想要顺利的迁移到Kubernetes平台,需要完成业务项目的无状态化,有状态的数据向外迁移,我们在微服务转型的过程中,打造了统一的配置中心,CacheCloud集群,数据库集群,消息队列等等,将与业务无关的中间件独立出来,做到项目容器可随时重启,迁移,伸缩等。
我们也为业务项目打造了统一的标准容器运行环境,为了做到与项目之前在虚拟机中的运行保持一致,我们基于CentOS系统做了JDK、Jetty、Node.js等基础镜像,这样可以做到业务项目在虚拟机到容器平滑迁移,我们在每个项目中内嵌了Dockerfile,Dockerfile可以由开发负责人配置,基于基础镜像,只需要将编译生成的jar包copy到我们指定的位置即可,基础镜像的启动脚本会自动启动这些项目并内置Supervisor守护进程。如果开发有特殊需求,他们也可以在Dockerfile中添加自己的配置和脚本,这样既保持了Dockerfile的简洁,也允许开发灵活配置,无论开发是否熟悉Dockerfile,都可以做到项目的一键编译构建与自启动运行。并且统一了镜像交付标准,可以做到一次构建,处处运行。
项目在做容器化改造的同时,我们的容器集群也需要为适配项目而改造。首先,容器化的迁移不是一蹴而就的,必然存在容器与虚拟机并存运行的的情况,我们业务项目使用的Dubbo+ZooKeeper框架,众所周知,Dubbo是客户端服务发现并且直接通过IP地址发起RPC调用的,为了做到开发无感知迁移,首先要解决的就是虚拟机与容器之间的网络通信问题,在调研了众多网络方案后,我们选择了Calico网络方案来解决,Calico是一个纯三层的路由转发方案,几乎没有性能损耗,并且可以使用calico routereflector路由反射器来与核心交换机建立bgp连接,进行路由交换,这样虚拟机就可以感知容器网段的存在,从而进行路由转发,也就打通了虚拟机与容器间的网络互通。示意图如下:
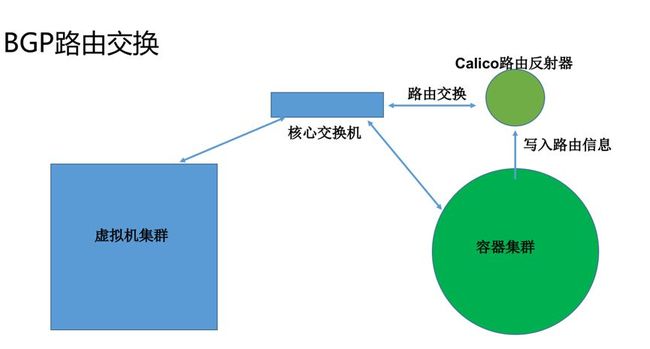
Calico是我们在私有云的解决方案,在公有云上也有同样的问题,并且大多数公有云都不支持Calico BGP的网络方案,但公有云都对容器集群VPC网络进行了支持,同样的原理,VPC网络的实质就是将容器的路由信息写入到VRouter中,使外部虚拟机能够感知到容器网段的路由,从而实现互相通信。
![]()
解决了项目容器化的问题,公司也组建了DevOps团队来推进自动化运维,我们开发了DevOps平台来实现项目的统一管理,CI/CD,灰度发布以及项目监控等功能。

第一代DevOps流水线是基于Jenkins和Shell脚本来做的CI/CD,示意如下:
git clone project
mvn compile || npm install || composer install
docker build && docker push
sed –i deployment.yaml
kubectl apply –f deployment.yaml
kubectl get pod –o wide
小规模的情况下还算可以,但当项目增长到1000个时,如何管理这些项目的deployment模板,并且每个项目的每个环境配置要求是不一样的,比如:
A项目测试环境需要1c1g1个节点,生产环境就需要2c2g4个节点,测试环境的DNS配置,滚动更新策略等与生产环境均不同,这些项目模板的人工维护成本是很高的,一旦出错就会带来严重的后果。
并且对于用户及运维人员来说,他们不会关心deployment文件,只有Kubernetes才会关心。
我们打造了第二代DevOps流水线,Sahaba-MetaData项目,顺便说下,Sahaba是我们团队的代号,所有的项目都以Sahaba开头命名,Sahaba来自阿拉伯语,云的意思。
Sahaba-MetaData项目,使用etcd数据库作为后端存储,我们将deployment文件的数据分成了三部分,对用户解耦:
用户数据:如项目名/CPU/内存/节点数等用户可配置的参数
流水线数据:镜像名称/项目域名/健康检测配置/机房环境等,这些由DevOps流水线在构建时实时生成,然后传递过来
容器云数据(策略模板):滚动更新配置/资源超开策略/DNS/日志组件配置/deployment基础信息等,这些是我们的发布策略配置,由我们容器团队来维护,其他用户不需要关心这些数据


在容器化迁移过程中,以尽可能的做到自动化运维管理为目标,这里借用来自阿里的DevOps八荣八耻:

![]()
接下来分享一些容器相关的实践与遇到的坑。
一、使用Resource: request/limit控制容器的资源超开比例,建议一定要为每个项目容器都要配置,不配置容器默认可以使用整个宿主机的资源,从而影响宿主机上其他项目的运行。
Java项目JVM的参数设置,在JDK8U131,JDK9版本以后,新增了一个参数可以自动感知容器内存大小限制。我们的Java项目主要以JDK7、8为主,JVM默认会以整个宿主机的CPU内存来初始化,建议加上Java –server –xms –xmx –xmn等参数,防止JVM爆内存,被容器杀死。我们是将容器CPU内存的限制写入到环境变量里,JVM启动脚本从环境变量里读取参数启动。
二、做好容器磁盘使用的限制,不要相信你们的开发,你不知道他们会向容器里输出什么,应用日志做好轮转,限制docker stdout标准输出,可以使用Docker的参数配置;限制容器rootfs,目前DeviceMapper存储驱动支持较好;限制所有挂载到容器的数据卷,不要让一个容器坏掉整个节点;并且为节点添加自动驱逐参数,新版本kubelet是默认启用的。
三、应用上线,做好滚动更新与健康检测配置。
配置ReadinessProbe,我们要求每个项目都内置http健康检测路径,滚动更新会根据ReadinessProbe状态来决定是否继续更新以及是否允许接入流量,这样在整个滚动更新过程中可保证始终会有可用节点的存在,达到无缝更新。
四、容器日志收集方案
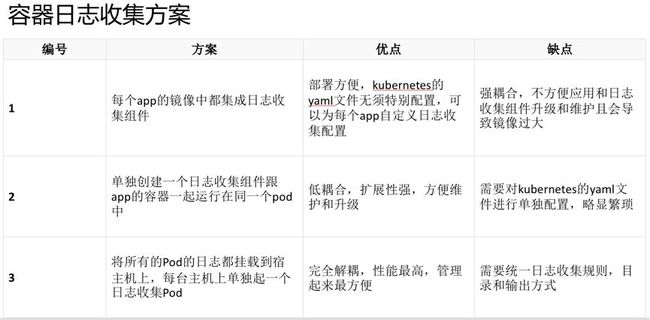
比较常见的有这么几种,可能也有项目日志直接写入ES集群,不需要容器内收集的。
这里我推荐使用第三种收集方案,以DaemonSet的方案部署日志收集组件,做到业务容器的完全无侵入,节省服务器资源,不必为每个业务容器都启动一个日志收集组件。
五、定时备份etcd数据库
etcd集群的稳定是Kubernetes集群稳定的根本,一旦etcd发生问题,整个Kubernetes集群都将不可用,我们曾有etcd集群故障导致容器集群崩溃的惨痛教训,做到定时备份etcd数据,包括etcd snapshot快照和etcd数据目录的备份,有条件的还可以做etcd服务器的镜像备份以及远程备份,做到发生故障时能够快速恢复。
![]()
项目容器化之后,需要让开发及运维与容器进行交互操作,kubectl工具学习成本高,权限不好管理,不适合直接给用户使用,我们开发了Sahaba api & cli工具,对接LDAP登录,自己做了精确的权限管理。
Sahaba api基于kubernetes api开发,cli端只保留了用户需要的功能,比如:get/exec/logs/describe/scale/delete等命令。
我们也同样开发了web terminal界面,当用户不习惯使用命令行时,可以从网页端进入容器控制台操作。
同时对接了公司的CMDB,可以在CMDB的界面中实时看到容器的状态。
![]()
最初我们使用Heapster+InfluxDB+Grafana做容器的资源监控,但当集群增长到一定规模时,数据量太大会导致InfluxDB数据库崩溃,Heapster项目也被Kubernetes官方放弃,所以我们转向了Prometheus监控,Prometheus可以使用自定义的exporter,收集自己想要的数据,从集群组件,到集群节点再到每一个容器,都可以做到精准的监控,以及配置相应的告警规则,做到自动告警。
后续我们还在考虑根据容器应用的资源监控以及APM实时的业务负载,达到自动伸缩的目的,目前我们没有使用Kubernetes官方的HPA资源,因为单一的CPU内存指标不一定能够做到准确的伸缩,所以我们想要根据实际的业务场景来自己做。
Q&A
![]()
Q:Ingress是用的那个组建?A:这里我再详细补充下,我们没有使用到Ingress Service这些对象,为了维护与虚拟机项目的统一管理,方便运维使用,我们的Nginx是部署在集群外部的,与nginx-ingress-controller一样,使用Lua扩展自己做服务发现,Nginx直接向Pod转发流量。
Q:Nginx和PHP-FPM采用什么方法部署和更新,Nginx和FPM有分开部署吗?A:Nginx部署在集群外部虚拟机里,虚拟机网络与容器内部网络是打通的,直接转发流量给Pod;PHP是老项目,有一小部分做了容器化,基于PHP基础镜像使用deployment部署,PHP项目是无状态的,跟其他项目一样进行滚动更新;Nginx与FPM是分开部署的。
Q:请问下你们有没有使用API网关,自己开发的还是使用Kubernetes自带的,用户权限是做在API网关吗? A:目前没有用到API网关项目,自己使用Nginx做的简单API网关,sahaba api是我们自己开发的Kubernetes管理工具,使用client-go组件向Kubernetes API发起请求调用;用户权限我们对接了DevOps权限管理系统,区分超级管理员,运维人员,项目负责人,普通用户等,确定某个用户对某个项目容器guest或admin权限。
Q:你们的Kubernetes管理平台,考虑用360开源的wayne吗?https://github.com/Qihoo360/wayne可以满足用户上线需求,也集成了webshell之类的,看起来挺不错的。A:360的wayne项目,我们也关注了,把源码下下来看了一下。我们DevOps平台与wayne的一大不同之处在于:wayne给用户的发布是把Kubernetes的deployment模板放上去了,让用户去填写;我们是用sahaba-metadata项目将deployment模板抽象出来,只给用户填写Git项目分支,以及需要发布的CPU/内存/节点等,镜像url,超开策略等数据不需要用户填写,开发人员不需要关心这些。我们也参考了wayne的webshell实现,跟kube dashboard项目一样的,我们也正在基于他们的代码优化我们自己的webshell。
Q:etcd用哪个版本的,3节点以上的etcd集群崩溃后如何用镜像快速恢复?A:我们的集群各个版本都有,从1.4到1.11,都是使用当时最新的稳定版部署,具体可以看Kubernetes release note里的dependencies;etcd集群恢复,只要有一个节点etcd的数据在,就可以恢复,先将这个节点force-new,其他节点join进来,数据会自动从leader同步到slave。你提到的使用虚拟机镜像恢复,这个我还没有使用过,我理解的整个云硬盘的数据都可以备份下来,数据恢复也是没问题的,参照公有云数据备份恢复方案。
Q:etcd数据备份是怎么做的,Crontab吗,还是使用Kubernetes里的Job,如何确保备份的数据是没有问题的?A:因为etcd是二进制文件部署的,目前我们是使用Crontab定时任务每天备份一次数据,备份的内容包括etcd snapshot,etcd的数据目录,同时备份到本地及远程服务器,公有云上还有云硬盘镜像备份,多种备份方案保证数据正常。
Q:日志收集工具是否用了Fluentd,日志收集到ES里,用Kibana查询有没有遇到过日志乱序的问题?A:我们使用的是Filebeat,将日志收集到Kafka,再转给Logtash,Logtash处理后才转给ES, Filebeat -> Kafka -> Logstash -> ES -> Kibana,乱序问题我没遇到过,应该可以在Logstash处理的时候确认。
Q:可否实现Kubernetes上容器与主机通讯?A:容器与主机通信是可以的,具体可以参见Calico的网络方案,使用calico routereflect路由反射功能与核心交换机做bgp peer进行路由交换,公有云上使用VPC网络方案。
Q:JVM Xmx是堆内存,硬限制是物理内存,你们的配置是直接读环境变量设置一样了吗?会不会出现内存不足?堆外内存怎么办?A:我们的环境变量配置的是Pod容器的limit大小,JVM Xmx是使用limit大小*0.6配置启动的,出现过内存不足,OOM等情况,一般是让开发去调整permsize大小,或不要有内存泄露。
Q:容器rootfs大小怎么限制的?A:在安装Docker时,使用Devicemapper驱动安装,会默认限制大小10G,overlya驱动对rootfs大小的限制不是很完善。
Q:什么时候升级集群,Kubernetes大版本升级的时候怎么做?A:我们一般会在进行机房业务迁移的时候去升级集群,如从私有云迁到公有云,直接新建一套新版本集群,把旧集群的deployment文件更新过去。
Q:相关中间件和DB都没有上吗?有的话请介绍一下。A:是的,中间件和DB数据库都有专门的团队来维护,在没有必要的情况下没有去做容器化,我们集群对接了Ceph存储,但IO性能不高,数据库容器化还是应该使用local volume。
Q:DevOps的资料都存在etcd中的吗? 这个是怎么做的 能否讲讲设计思路?A:是我们的Deployment发布模块及元数据都存在了etcd中,把etcd当做一个K-V数据库来用,当时在数据库选型时也考虑过MySQL,但是我们的数据类型适合KV存储,如我们的每个项目Deployment模板都是不一样的,存放在/deployment/region/env/projectname/这样的路径下,并且etcd更加稳定高可用。
![]()
