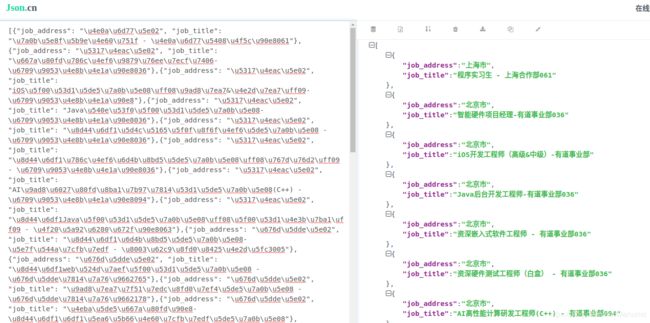
通过CrawlSpider爬取网易社会招聘信息
1.创建工程
scrapy startproject 项目名称
2.创建crawlspider爬虫
scrapy genspider -t crawl 爬虫名 爬虫的范围.com
3.爬虫代码如下
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class WangyishezhaoSpider(CrawlSpider):
name = 'wangyishezhao'
allowed_domains = ['163.com']
start_urls = ['https://hr.163.com/position/list.do?postType=01']
rules = (
Rule(LinkExtractor(restrict_xpaths='//div[@class="m-page"]/a'), follow=True),
Rule(LinkExtractor(restrict_xpaths='//tbody/tr/td[1]/a'), callback='parse_item', follow=False),
)
def parse_item(self, response):
data_dict=dict()
data_dict['job_title'] = response.xpath('//div[1]//div[1]/h2/text()').extract_first()
data_dict['job_address'] = response.xpath('//table[@class="job-params"]//td[4]/text()').extract_first()
return data_dict
4.通过pipeline管道进行保存数据
from scrapy.exporters import JsonItemExporter
class WangyishezhaoPipeline(object):
def open_spider(self,spider):
self.file = open('wangyi.json','wb')
self.write = JsonItemExporter(self.file)
self.write.start_exporting()
def process_item(self, item, spider):
self.write.export_item(item)
return item
def close_spider(self,spider):
self.write.finish_exporting()
self.file.close()
5.定义中间件,设置用户代理和ip代理
class UserAgentMiddleware(object):
def process_request(self,request,spider):
random_user = random.choice(USER_AGENT_LIST)
request.headers['User-Agent']=random_user
def process_response(self, request, response, spider):
print('#' * 100)
print(request.headers['User-Agent'])
return response
class ProxyMiddleware(object):
def process_request(self,request,spider):
proxy = random.choice(proxies)
request.meta['proxy']=proxy
return None
6.最后在settings配置文件中进行配置
BOT_NAME = 'WangYiSheZhao'
SPIDER_MODULES = ['WangYiSheZhao.spiders']
NEWSPIDER_MODULE = 'WangYiSheZhao.spiders'
USER_AGENT = 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.84 Safari/537.36'
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 0.5
DOWNLOADER_MIDDLEWARES = {
'WangYiSheZhao.middlewares.UserAgentMiddleware': 543,
'WangYiSheZhao.middlewares.ProxyMiddleware': 555,
}
ITEM_PIPELINES = {
'WangYiSheZhao.pipelines.WangyishezhaoPipeline': 300,
}
USER_AGENT_LIST = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.101 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 SE 2.X MetaSr 1.0",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; SE 2.X MetaSr 1.0)",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60",
"Opera/8.0 (Windows NT 5.1; U; en)",
"Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208 Firefox/2.0.0 Opera 9.50",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; en) Opera 9.50",
]
proxies = [
'http://58.218.200.223:30054',
'http://58.218.200.223:30153',
'http://58.218.200.223:30370',
'http://58.218.200.223:30288',
'http://58.218.200.223:30044',
]
运行结果如下图所示

通过json.cn渲染后的结果