蔡狗_linux04汇总
1 挂载新的硬盘
1.1 目标
虚拟机 增加一块 硬盘
1.2 路径
第一步: 了解linux系统分区的原理
第二步: 查看系统分区情况
第三步: 虚拟机 增加 硬盘
第四步: 分区
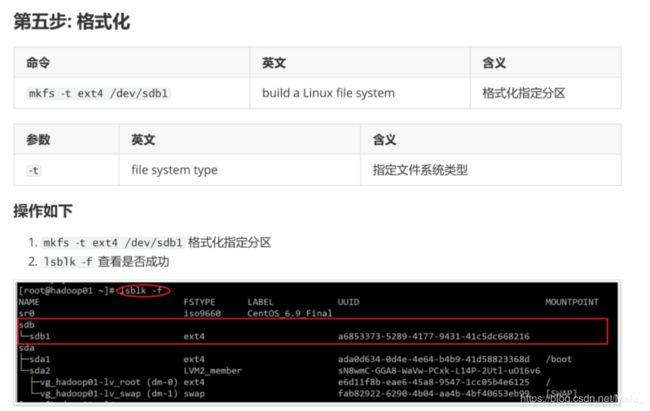
第五步: 格式化
第六步: 挂载
第七步: 设置重启后 挂载不失效
1.3 实现
第一步: 了解linux系统分区的原理
一个硬盘可以分成多个分区
用户不能直接操作硬件, 需要 让硬件和系统的目录 建立映射关系(挂载) 才可以操作, 称为 挂载
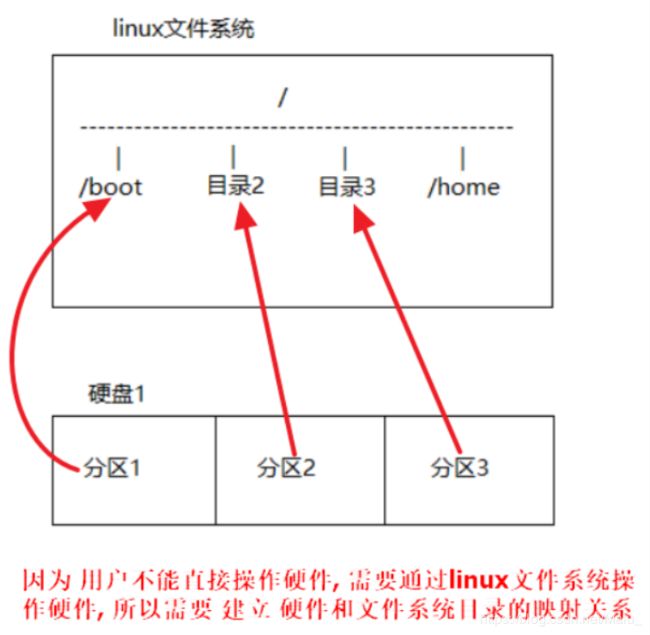
第二步: 查看系统分区挂载情况
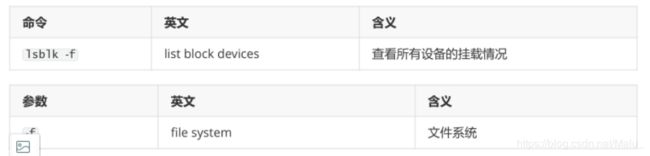

lsblk 的记忆小窍门: 老师不离开 的首字母
第三步: 虚拟机 增加 硬盘
模拟将买的硬盘插入到 服务器中
- 选中 目标虚拟机 右键 设置
- 选中 硬盘 点击 添加按钮
- 点击 下一步
- 选择 创建新虚拟磁盘
- 指定 磁盘大小为10G
- 完成
- 注意: 重启 才可以生效

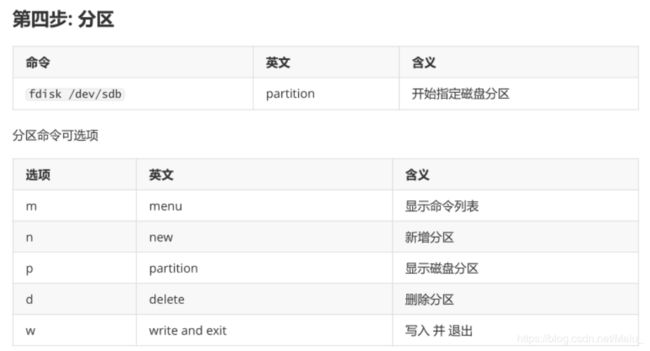
操作如下: - fdisk /dev/sdb 开始分区
- 输入 m , 进入 目录列表
- 输入 n , 新增分区
- 输入 p , 开始分区, 后面按回车
- 最后 输入 w , 保存 且 退出
- lsblk -f 查看是否成功

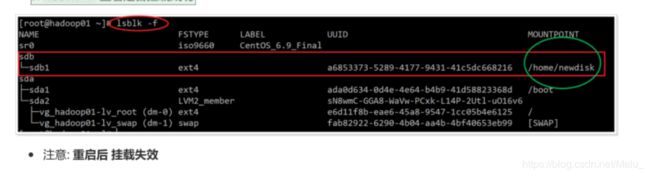
第六步: 挂载

操作步骤 - 创建目录 mkdir -p /home/newdisk
- mount /dev/sdb1 /home/newdisk 建立 设备分区 和 系统目录 的映射关系
- lsblk -f 查看是否挂载成功
17. 第七步: 设置重启不失效
第七步: 设置重启不失效
操作步骤
第一步: 将映射关系写到配置文件中 /etc/fstab
第二步: mount -a 重新加载 /etc/fstab 文件 ; mount 显示 /etc/fstab 文件内容
第三步: 重启操作系统后, 测试 lsblk -f
1.4 小结
用户不能直接访问 硬件设备
需要将硬件设备 挂载到 系统目录上, 用户才可以让用户访问
1.5 挂载 持有系统镜像 光驱
1.5.1 目标
因为 linux系统镜像中包含了常用的软件包, 就不用从网上下载了
所以需要挂载 持有系统镜像 的 光驱
1.5.2 路径

第一步: 将 linux系统镜像 放到光驱中
第二步: 创建目录 /mnt/cdrom
第三步: 通过挂载 建立 硬件 和 系统目录的关系
第四步: 到镜像中 寻找按照包
1.5.3 实现 - 目标虚拟机, 右键 设置
- 选中 CD/DVD, 浏览 选中本地的 centOS 镜像

创建目录 mkdir -p /mnt/cdrom - 挂载镜像文件 mount /dev/sr0 /mnt/cdrom
- 进入挂载目录, 找到 安照包
1.5.4 小结
通过 挂载 系统光驱, 就可以 获取系统镜像中 软件包
注意: 系统镜像目录中 不能有中文, 不能有空格
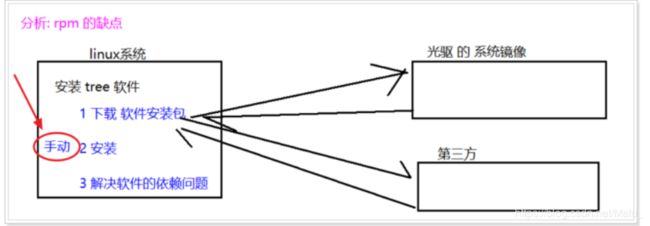
2 rpm 软件包管理器
2.1 目标
通过 rpm命令 实现对软件 的安装、查询、卸载
RPM 是Red-Hat Package Manager(RPM软件包管理器)的缩写
虽然 打上了 red-hat 的标记, 但是理念开放, 很多发行版都采用, 已经成为行业标准
2.2 路径
第一步: rpm包 的 查询命令
第二步: rpm包 的 卸载
第三步: rpm包 的 安装
切换到安装包目录中
cd /mnt/cdrom/Packages/
2.3 实现
第一步: rpm包 的 查询命令


第二步: rpm包 的 卸载


第三步: rpm包 的 安装

2.4 小结
1 查询
rpm -qa | grep rpm包
2 卸载
rpm -e rpm全包名
rpm -e --nodeps rpm全包名
3 安装
rpm -ivh rpm包的全路径
3 yum
3.1 目标
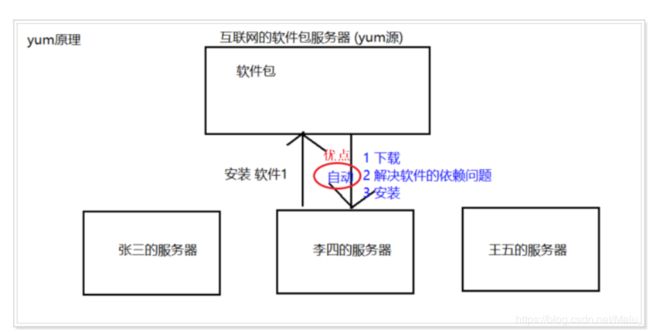
Yum (全称为 Yellow dog Updater, Modified )本质上 也是一个 软件包管理器。
特点: 基于 RPM 包管理,能够从指定的服务器 自动下载、 自动安装、 自动处理依赖性关系
3.2 路径
第一步: yum的原理
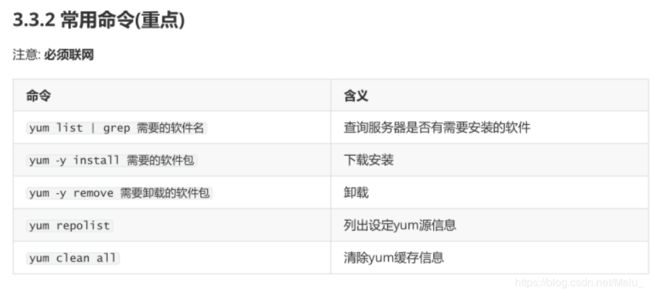
第二步: 常用指令 (重点)
第三步: 制作 本地 yum 源
第四步: 制作 局域网 yum 源
3.3 实现
3.3.1 yum的原理
 3.3.3 制作本地yum源
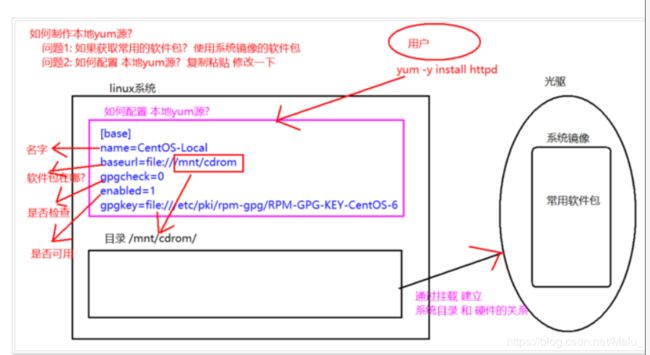
3.3.3 制作本地yum源
原因: 因为大数据集群 为了安全, 不让连接外网
原理
实现
 实现
实现
第一步 挂载 持有系统镜像的 光驱, 请参考 1.5 小结
第二步: 备份默认yum源仓库
第三步: 新增本地yum源 vim CentOS-Local.repo
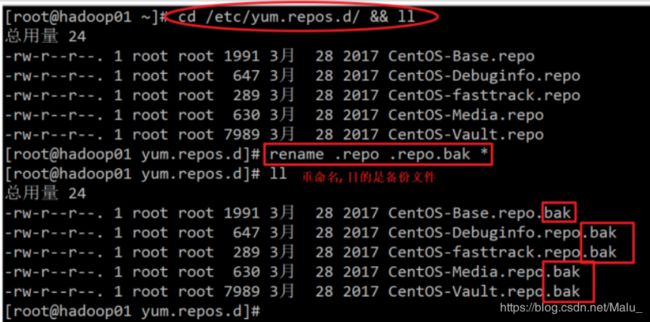
切换到保存yum信息的目录
cd /etc/yum.repos.d/
备份所有的配置文件
rename .repo .repo.bak *
查看是否备份成功
ll
 第三步: 新增本地yum源 vim CentOS-Local.repo
第三步: 新增本地yum源 vim CentOS-Local.repo
vi CentOS-Local.repo
编辑内容如下
[base]
name=CentOS-Local
baseurl=file:///mnt/cdrom
gpgcheck=0
enabled=1

注意: 必须以 .repo 结尾
第五步: 断网 测试是否可以安装
查看 yum 源仓库
yum repolist
清空缓存
yum clean all
卸载 tree 软件
yum -y remove tree
重新安装 tree 观察是否成功
yum -y install tree
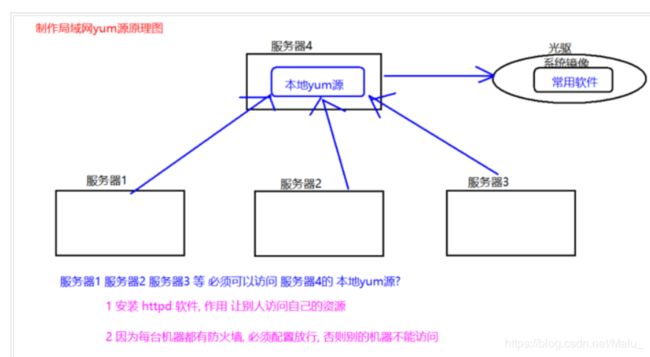
3.3.4 制作局域网yum源
原理
 3.3.5.1 安装httpd软件
3.3.5.1 安装httpd软件
安装httpd:
yum -y install httpd
启动 httpd 服务
service httpd start
测试
http://192.168.100.201:80
问题: 发现无法访问?
原因: 因为 linux 的防火墙 禁止他人 访问自己的80端口
解决: 通知 防火墙放行
关闭防火墙
原因: 为了方便 内网中集群间机器的相互操作, 通常会关闭防火墙
关闭防火墙
service iptables stop
重启之后不要开防火墙
chkconfig iptables off
3.3.4.3 制作局域网 yum源
使用浏览器访问http://192.168.100:201:80 第一步: 将常用软件包 复制到指定目录下
第一步: 将常用软件包 复制到指定目录下
拷贝yum源到httpd服务的默认工作路径下
cp -r /mnt/cdrom/* /var/www/html/CentOS-6.9
第二步: 浏览器访问http://192.168.100.201/CentOS-6.9/
第三步: 更新其他节点的 本地yum源(在其他节点上测试)
- 备份默认yum源
cd /etc/yum.repos.d/
mv CentOS-Local.repo CentOS-Local.repo.bak - 制作本地yum源
cd /etc/yum.repos.d/
vi CentOS-Local.repo
[base]
name=CentOS-Local
baseurl=http://192.168.100.201/CentOS-6.9/
gpgcheck=0
enabled=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-6
第四步: 测试是否成功(在其他节点上测试)
yum clean all
yum repolist
yum install -y tree
3.4 小结
安装软件
yum -y install 软件包
卸载软件
yum -y remove 软件包
4 安装jdk
4.1 路径
第一步: 卸载linux系统 提供的jdk
第二步: 上传按照包到 /export/soft , 解压到 /export/install
第三步: 将 jdk路径 放到 环境变量中
第四步: 重新加载 环境变量的配置文件
第五步: 测试是否安装成功
4.2 实现
第一步: 卸载linux系统 提供的jdk
查询已安装的jdk
rpm -qa | grep java
卸载
rpm -e --nodeps 软件包名
第二步: 上传按照包到 /export/soft , 解压到 /export/install
1 创建保存软件包目录
mkdir -p /export/soft/
cd /export/soft/ && ll
2 上传软件包
3 创建安装软件目录
mkdir -p /export/install
4 将压缩包解压到指定目录
tar -zxvf jdk-8u141-linux-x64.tar.gz -C /export/install
cd /export/install && ll
第三步: 将 jdk路径 放到 环境变量中
目的: 为了能够在任何目录下都可以使用 javac 和 java
JAVA_HOME=/export/install/jdk1.8.0_141
PATH=/export/install/jdk1.8.0_141/bin:$PATH
export JAVA_HOME PATH
第四步: 重新加载 环境变量的配置文件
为了生效, 要么重启电脑, 要么 重新加载配置文件
source /etc/profile
测试
java -version
第五步: 测试是否安装成功
需求: 编写一个简单的Hello.java, 输出 Hello World!
vim Hello.java
[root@hadoop01 export]# cat Hello.java
public class Hello{
public static void main(String[] args) {
System.out.println(“Hello java!”);
}
}
使用 javac Hello.java 编译
执行 java Hello
5 安装tomcat
5.1 目标
实际工作中我们可能需要发布web项目到tomcat中
5.2 路径
第一步: 将安装包上传到 /export/soft , 解压到 /export/install
第二步: 启动tomcat 且 查看日志
第三步: 上传项目 测试
5.3 实现
第一步: 将安装包上传到 /export/soft , 解压到 /export/install
切换到保存软件的目录
cd /export/soft
解压到 /export/install 安装目录
tar -zxvf apache-tomcat-7.0.82.tar.gz -C /export/install/
第二步: 启动tomcat 且 查看日志
切换启动命令的目录
cd /export/install/apache-tomcat-7.0.82/bin
启动 且 查看日志
./startup.sh && tail -100f …/logs/catalina.out
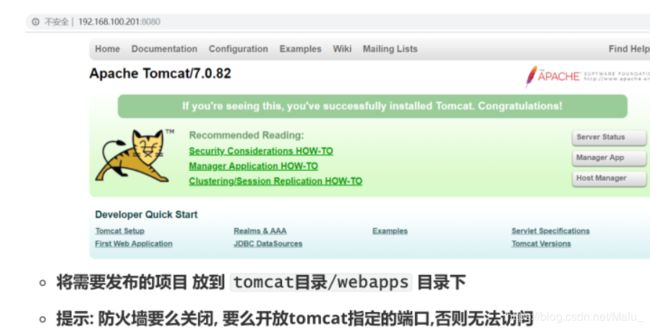
第三步: 测试
http://192.168.100.201:8080/
 6 安装mysql
6 安装mysql
6.1 yum安装原理:
yum安装是通过执行yum命令,自动分析依赖关系, 自动下载, 自动安装
6.2 yum安装优点:
安装简单、快速
6.3 缺点:
由于不同的yum仓库只有特定的几个版本,所以可选的版本较少。
6.4 yum安装实战
下面看看如何在CentOS7系统上安装 MySQL5.6.44
1 查询系统自带的mysql
[root@hadoop01 yum.repos.d]# rpm -qa | grep mysql
mysql-libs-5.1.73-8.el6_8.x86_64
2 安装mysql
yum install -y mysql-server
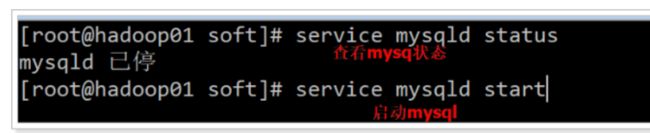
3 启动服务
service mysqld start
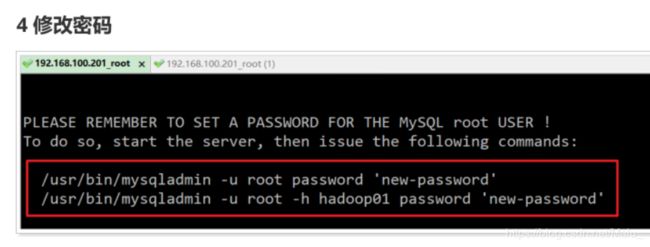 # 设置密码
# 设置密码
/usr/bin/mysqladmin -u root password ‘123’
进入mysql
mysql -uroot -p123
5 问题1: 解决中文乱码
由于MySQL编码原因会导致数据库出现乱码。
解决办法:
修改MySQL数据库字符编码为UTF-8,UTF-8包含全世界所有国家需要用到的字符,是国际编码。
具体操作:
1 进入MySQL控制台
进入mysql
mysql -uroot -p123
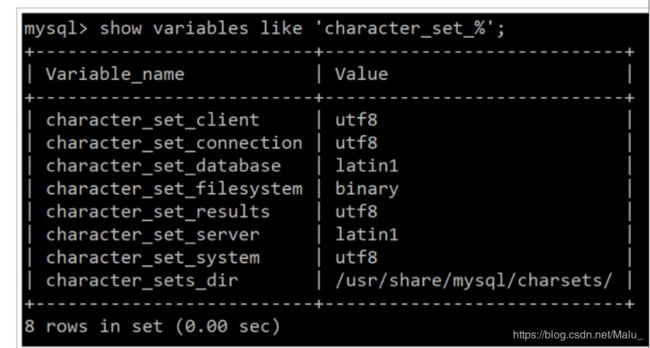
查看编码集 发现不是utf8
show variables like ‘character_set_%’;
 2 修改mysql配置文件
2 修改mysql配置文件
清空 mysql 配置文件内容
[root@Hadoop-NN-01 ~]# >/etc/my.cnf
修改mysql 软件的编码集
[root@Hadoop-NN-01 ~]# vi /etc/my.cnf
修改内容如下:
[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
[mysqld]
character-set-server=utf8
3 重启MySQL服务
[root@Hadoop-NN-01 ~]# service mysqld restart
#查看MySQL字符集
show variables like ‘character_set_%’;
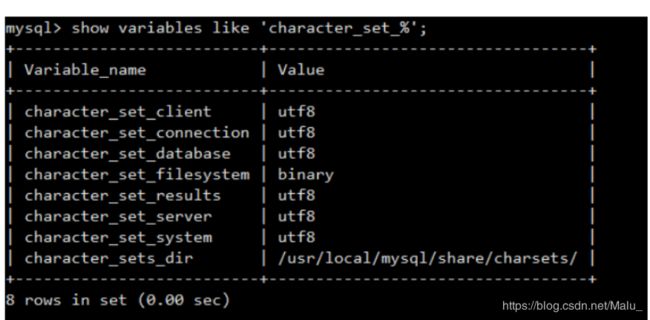 MySQL数据库字符集编码修改完成!
MySQL数据库字符集编码修改完成!
6 问题2: 默认情况下 mysql服务端不允许客户端远程访问
问题: 使用客户端 远程 连接mysql报错?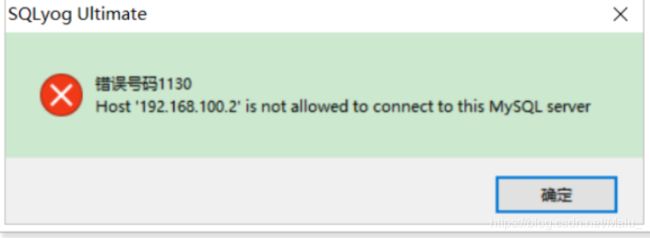 原因: 因为 用户 没有 远程访问的权限
原因: 因为 用户 没有 远程访问的权限
解决: 授权
给root授权:既可以本地访问, 也可以远程访问
grant all privileges on . to ‘root’@’%’ identified by ‘123’ with grant option;
刷新权限(可选)
flush privileges;
7 集群(三台)
7.1 新增linux系统
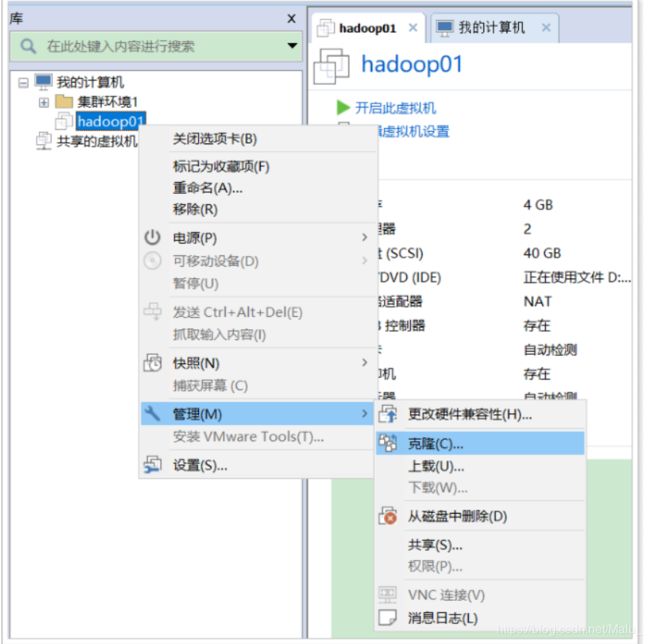
 第一步: 克隆虚拟机
第一步: 克隆虚拟机

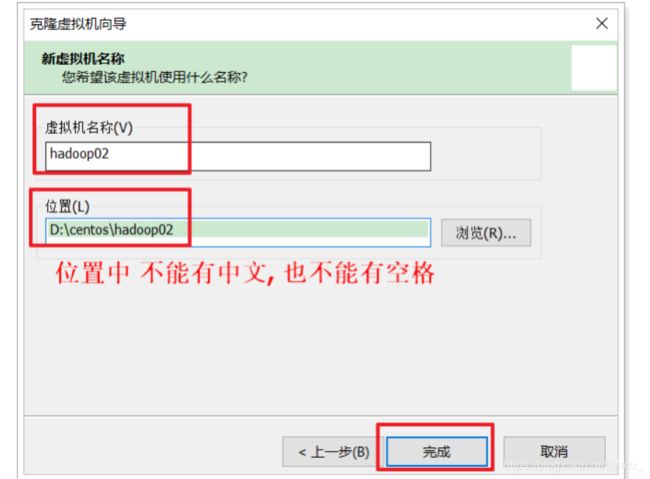
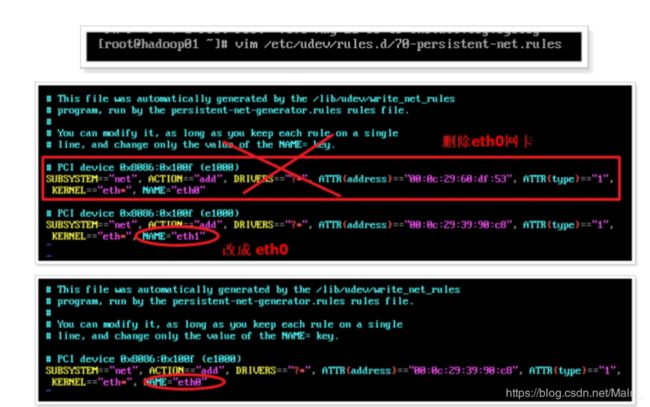
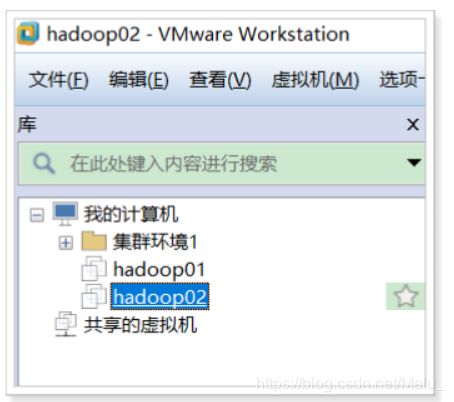 第二步: 更改新增系统的mac地址
第二步: 更改新增系统的mac地址
vim /etc/udev/rules.d/70-persistent-net.rules
 第四步: 重启系统生效
第四步: 重启系统生效
reboot
7.2 三台机器 关闭防火墙
内网环境 安全性比较高, 防火墙开启会影响效率, 所以 关闭防火墙
三台机器执行以下命令(root用户来执行)
查看防火墙的状态
service iptables status
启动防火墙服务
service iptables start
重启 防火墙 服务
service iptables restart
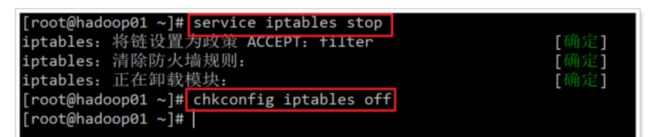
停止 防火墙 服务
service iptables stop
彻底关闭防火墙
chkconfig iptables off
7.3 三台机器关闭selinux
vim /etc/selinux/config
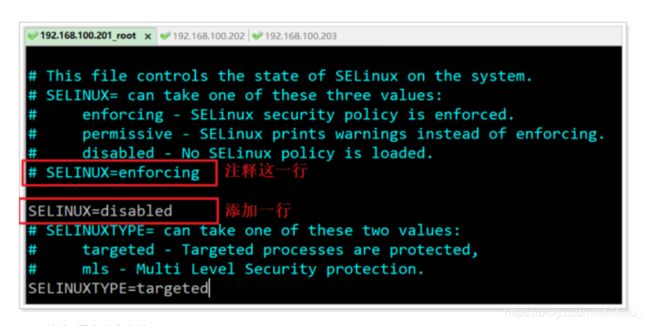 注意: 重启才会生效
注意: 重启才会生效
7.4 三台机器更改主机名
vim /etc/sysconfig/network
 重启才会生效
重启才会生效
7.5 三台机器 给ip地址起别名
7.5.1 给ip地址起别名
vim /etc/hosts
192.168.100.201 hadoop01
192.168.100.202 hadoop02
192.168.100.203 hadoop03
7.5.2 测试
ping 192.168.100.202
ping hadoop02
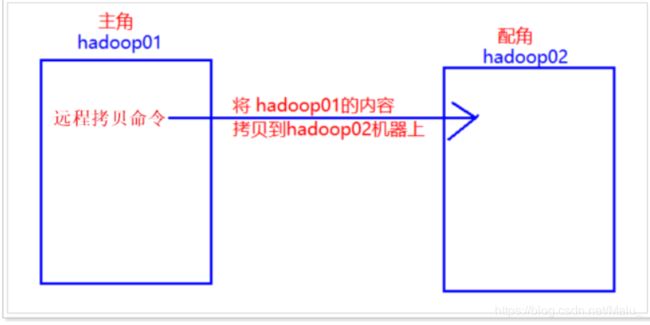
 7.6 scp 远程文件拷贝
7.6 scp 远程文件拷贝
7.6.1 是什么?
scp是 remote file copy program 的缩写, scp是远程文件拷贝命令。
7.6.2 从本地拷贝到远程机器上
 准备工作
准备工作
创建目录
mkdir -p /export/aaa/bbb/ccc
创建文件
touch /export/aaa/01.txt /export/aaa/02.txt
显示
tree /export/aaa
1 文件
语法格式
拷贝文件
scp local_file remote_username@remote_ip:remote_folder
需求: 将本地 01.txt 文件 复制到 192.168.100.202 机器的 /export目录下
scp /export/aaa/01.txt [email protected]:/export
scp /export/aaa/02.txt root@hadoop02:/export
scp /export/aaa/02.txt hadoop02:/export
2 文件夹
语法格式
拷贝目录
scp -r local_folder remote_username@remote_ip:remote_folder
需求: 将本地 aaa 目录 复制到 192.168.100.202 机器的 /export 目录下
scp -r /export/aaa [email protected]:/export
scp -r /export/aaa root@hadoop02:/export
scp -r /export/aaa hadoop02:/export
7.6.3 将远程机器内容复制到本地机器上
 准备工作
准备工作
创建目录
mkdir -p /export/a1/b1/c1
创建文件
touch /export/a1/111.txt
touch /export/a1/222.txt
显示内容
tree /export/a1
1 文件
语法格式
scp remote_username@remote_ip:remote_file local_folder
练习3: 将 hadoop02的 111.txt 文件 复制到 hadoop01的 export目录下
scp [email protected]:/export/a1/111.txt /export
scp root@hadoop02:/export/a1/222.txt /export
scp hadoop02:/export/a1/222.txt /export
2 目录
语法格式
scp -r remote_username@remote_ip:remote_folder local_folder
练习4: 将hadoop02的 /export/a1/ 目录 复制到 hadoop01 的 export目录下
scp -r [email protected]:/export/a1 /export
scp -r hadoop02:/export/a1 /export
7.7 ssh远程登录
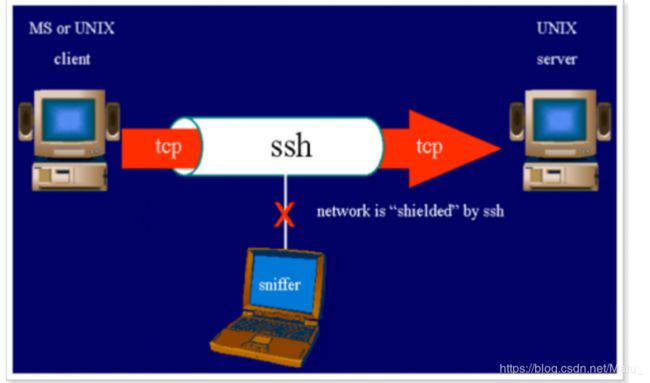 7.7.1 目标
7.7.1 目标
专门用于 远程登录
7.7.2 路径
方式一: 使用 ssh 基于密码的远程登录(了解)
方式二: 使用 ssh + expect 实现 免密码登录(了解)
方式三: 使用 ssh 基于密匙 实现 免密码登录(掌握)
7.7.3 实现
方式一 使用 ssh 基于密码的远程登录
在第三台机器上登录到第二台机器上
 细节: 首次远程登录会询问 yes/no , 以后可能就不会了
细节: 首次远程登录会询问 yes/no , 以后可能就不会了
方式二: 使用 ssh 基于密匙 实现 免密码登录(掌握)
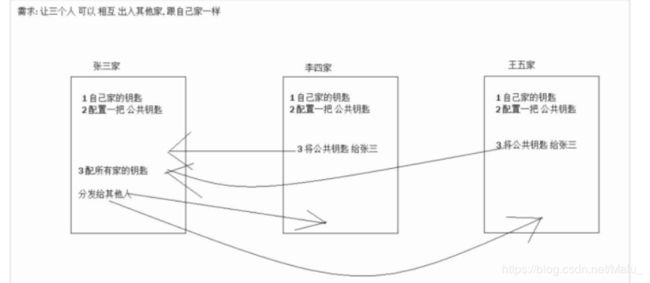 第一步: ssh-keygen -t rsa 在hadoop1和hadoop2和hadoop3上面都要执行,产生公钥和私钥
第一步: ssh-keygen -t rsa 在hadoop1和hadoop2和hadoop3上面都要执行,产生公钥和私钥
第二步:ssh-copy-id hadoop01 将公钥拷贝到hadoop1上面去
第三步:
ssh-copy-id hadoop02
ssh-copy-id hadoop03
注意1: 第三步需要在/root/.ssh/目录下.

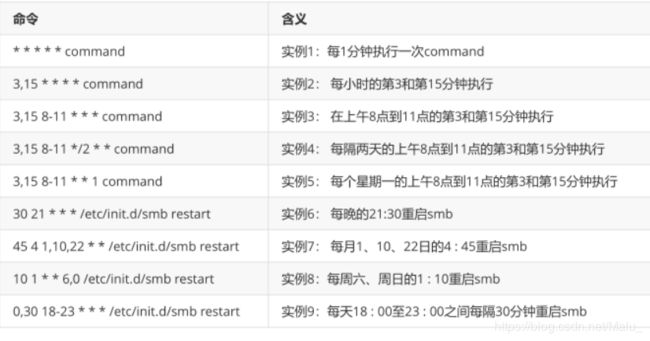
 7.8.3 案例: 每隔1分钟将时间打印到 /export/文件中
7.8.3 案例: 每隔1分钟将时间打印到 /export/文件中
方案一: 直接式
第一步: date >> /export/mydate1.txt 测试命令
第二步: 通过 crontab -e 进入 定时任务
第三步: 编辑定时任务命令
*/1 * * * * date >> /export/mydate1.txt
第四步: 检测是否成功
cd /export/ && tail -f mydate1.txt
方式二: 脚本式
第一步: 书写测试命令
echo date +"%Y-%m-%d %H:%M:%S" >> mydate2.txt
第二步: 将命令放到脚本中 vim /export/task.sh
echo date +"%Y-%m-%d %H:%M:%S" >> /export/mydate2.txt
第三步: 增加可执行权限
chmod +x /export/task.sh
第四步: 执行脚本
/export/task.sh
第五步: 进入 定时任务 crontab -e
*/1 * * * * date >> /export/mydate1.txt
*/1 * * * * /export/task.sh
第六步: 测试 观察结果
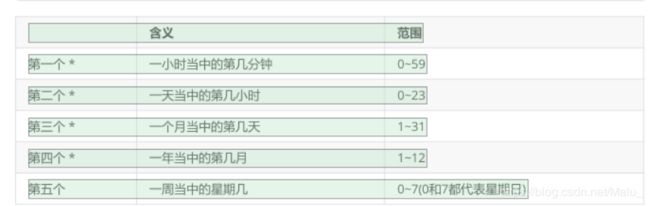
含义 范围
第一个 * 一小时当中的第几分钟 0~59
第二个 * 一天当中的第几小时 0~23
第三个 * 一个月当中的第几天 1~31
第四个 * 一年当中的第几月 1~12
第五个 一周当中的星期几 0~7(0和7都代表星期日)
tail -f /export/mydate2.txt
7.8.4 参数细节说明(学会查)
5个占位符的说明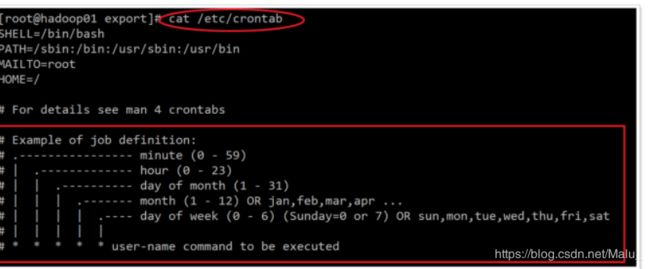
 7.9 三台机器时钟同步
7.9 三台机器时钟同步
7.9.1 同步互联网时间

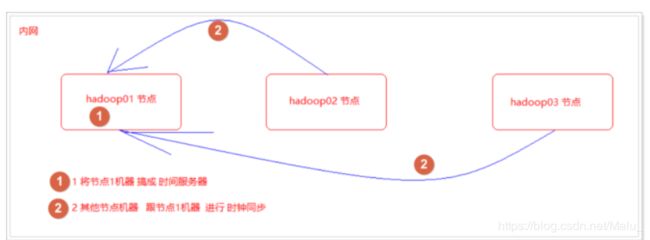
 7.9.2 跟内网某台机器同步时间
7.9.2 跟内网某台机器同步时间
为了安全, 大数据集群的节点不允许连接外网
以192.168.100.201 这台服务器的时间为准进行时钟同步
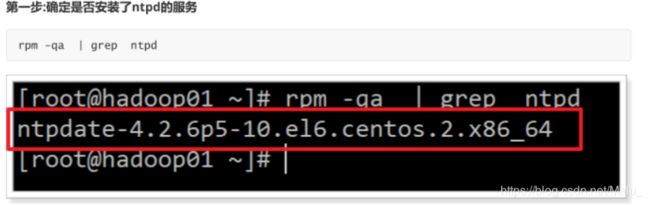 如果 没有安装,可以进行在线安装
如果 没有安装,可以进行在线安装
yum -y install ntpd
查看ntpd的状态
service ntpd status
启动ntpd的服务
service ntpd start
设置ntpd的服务开机启动
chkconfig ntpd on
第二步:编辑 /etc/ntp.conf
编辑第一台机器的 /etc/ntp.conf
vim /etc/ntp.conf
在文件中添加如下内容, 配置我们的时钟广播地址
restrict 192.168.100.0 mask 255.255.255.0 nomodify notrap
注释一下四行内容
#server0.centos.pool.ntp.org
#server1.centos.pool.ntp.org
#server2.centos.pool.ntp.org
#server3.centos.pool.ntp.org
去掉以下内容的注释,如果没有这两行注释,那就自己添加上
server 127.127.1.0 # localclock
fudge 127.127.1.0 stratum 10
 配置以下内容,保证BIOS与系统时间同步
配置以下内容,保证BIOS与系统时间同步
vim /etc/sysconfig/ntpd
添加一行内容
SYNC_HWLOCK=yes

重启ntpd 服务
service ntpd restart
注意: 如果更改ntp时钟服务器的时间,也需要重启 ntpd 服务
第三步:另外两台机器与第一台机器时间同步
先手动同步时间
ntpdate 192.168.100.201
再使用 定时任务 同步时间
crontab -e
*/1 * * * * /usr/sbin/ntpdate 192.168.100.201
另外两台机器与192.168.52.201进行时钟同步
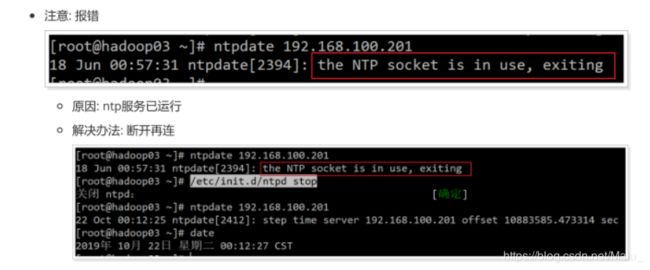
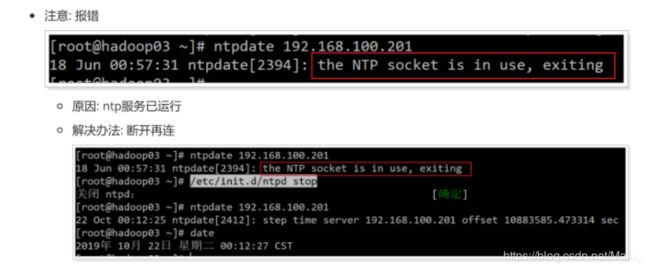
注意: 报错