notepad++使用正则提高机械化文字处理速度
摘要:
本文旨在提高大家对notepad++正则的使用,从而减少不必要的机械动作,提高大家的开发或者文字处理速度
本文分三部分
第一部分:notepad++正则基础知识的介绍
第二部分:结合基础知识的具体练习
第三部分:本人的具体案例
第一部分:notepad++正则基础知识的介绍
1.1 常用基本正则表达式
正则 含义
/t 制表符。
/n 新行。
. 匹配除新行(\ n)之外的任何字符。注意:这意味着“。” 也会匹配\ r \ n,当您使用\ r和\ n编辑文件时可能会造成一些混淆。以匹配所有字符,包括新行,你可以使用\ S \ S。
| 匹配表达式左边和右边的字符. 例如, "ab|bc" 匹配 "ab" 或者 "bc".
[...] 这表示一组字符,例如,[abc]表示字符a,b或c中的任何一个。您还可以使用范围,例如[az]表示任何小写字符。
[^...] 集合中字符的补充。例如,[^A-Za-z]表示除字母字符外的任何字符。"[^0-9]" 匹配任意非数字字符。
(...) 这标志着用于标记匹配的区域。可以使用第一个标记的语法\ 1来访问这些标记,第二个标记使用\ 2,使用\ 3 \ 4 ... \ 9。这些标记可以在当前正则表达式中使用,也可以在搜索/替换中的替换字符串中使用。
` `
\1, \2, etc 这是指替换时的第一个到第九个(\ 1到\ 9)标记区域。例如,如果搜索字符串是Fred([1-9])XXX并且替换字符串是Sam \ 1YYY,则当应用于Fred2XXX时,这将生成Sam2YYY。注意:由于只能使用9个区域,因此您可以安全地使用替换字符串\ 10 \ 2来生成“来自区域1的文本”0“来自区域2的文本”。
^ 这匹配一行的开头(除非在一个集合中使用,见上文)。
$ 这匹配一行的结尾。
* 这匹配0次或更多次。例如,Sa * m匹配Sm,Sam,Saam,Saaam等。
+ 这匹配1次或更多次。例如,Sa + m匹配Sam,Saam,Saaam等。
? 这匹配0或1次出现。例如,Sa?m匹配Sm,Sam。
/ 转义字符. 如果你要使用 "/" 本身, 则应该使用 "//"。
{n} 这恰好匹配n次。例如,'Sa {2} m'与Saam匹配。
{m,n} 这至少与m次匹配至多n次(如果n被排除,那么任意次数)。例如,'Sa {2,3} m'与Saam或Saaam匹配。'Sa {2,} m'与'Saa + m'相同
*?, +?, ??, {n,m}? 非贪婪的比赛 - 匹配第一个有效比赛。通常'<。>'将匹配整个字符串'内容' - 但'<。?>'会匹配''和'”。
这标志着用于标记匹配的区域。可以使用第一个标记的语法\ 1来访问这些标记,第二个标记使用\ 2,使用\ 3 \ 4 ... \ 9。这些标记可以在当前正则表达式中使用,也可以在搜索/替换中的替换字符串中使用。
如果以上表达式不能解决你的大部分实际问题,请参考 notepad++官网正则使用指南
1.2 非正则快捷操作, 批量添加删除多行同样位置数据
shift+alt+上下方向键 或者 alt+鼠标左键按住上下拖动 实现批量添加删除多行同样位置数据,类似于java中的面向切面编程哦.
第二部分:结合基础知识的具体练习
2.1 shift+alt+上下方向键 或者 alt+鼠标左键按住上下拖动 实例练习
因为 批量添加删除多行同样位置数据实际上比正则使用的频率更多,所有优先讲解
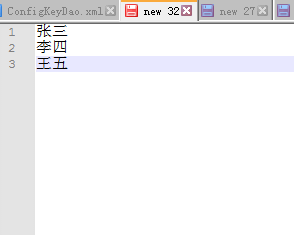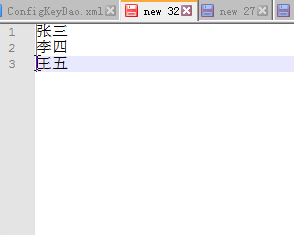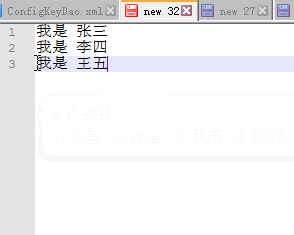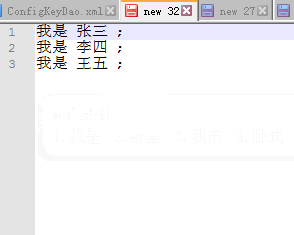
原始数据:
张三
李四
王五
目标数据:
我是 李四 ;
我是 王五 ;
我是 张三 ;
2.2 行匹配正则表达式
notepad的行匹配正则表达式是仅次于2.1的操作,而且行匹配必须和1.1的常用正则表达式组合使用
何为行匹配表达式,就是一次匹配一行开始到结尾的目标文字,匹配到目标字段则标记这一行的数据,而不是仅仅标记关键字
原始数据
hello word;
aha hello word;
hello word ;
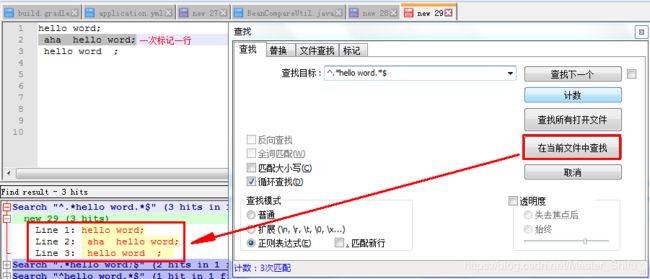
一、包含“hello word”的行
^.*hello word.*$
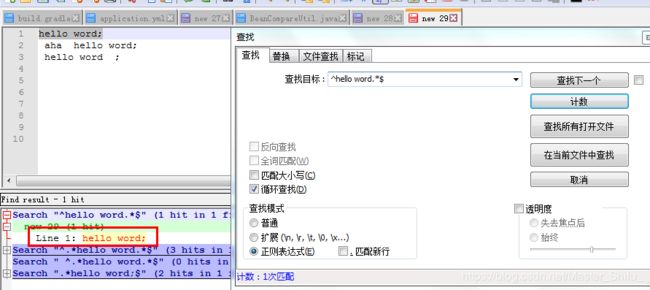
二、以“hello word”开始的行
^hello word.*$
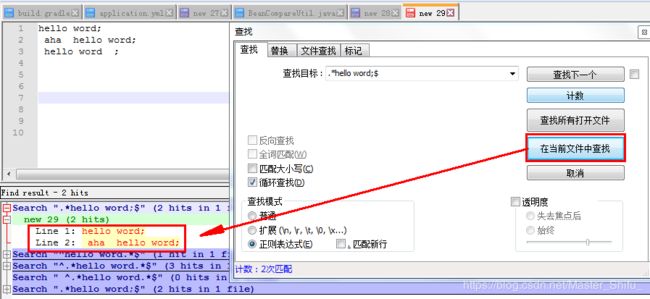
三、以“hello word;”结尾的行
.*hello word;$
2.3 使用正则以行为单位批量提取数据并替换
原始数据
str1abc991;
str2abc992;
str11abc993;
str22abc994;
str111abc995;
str222abc996;
str1111abc997;
str2222abc999;
目标数据:
select '1' from dual;
select '2' from dual;
select '11' from dual;
select '22' from dual;
select '111' from dual;
select '222' from dual;
select '1111' from dual;
select '2222' from dual;
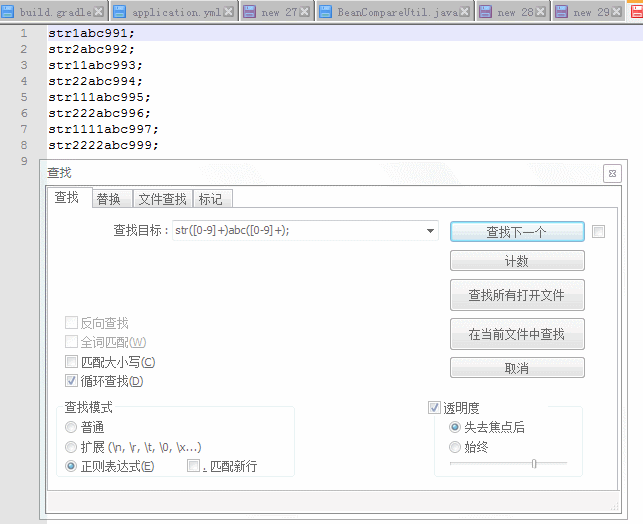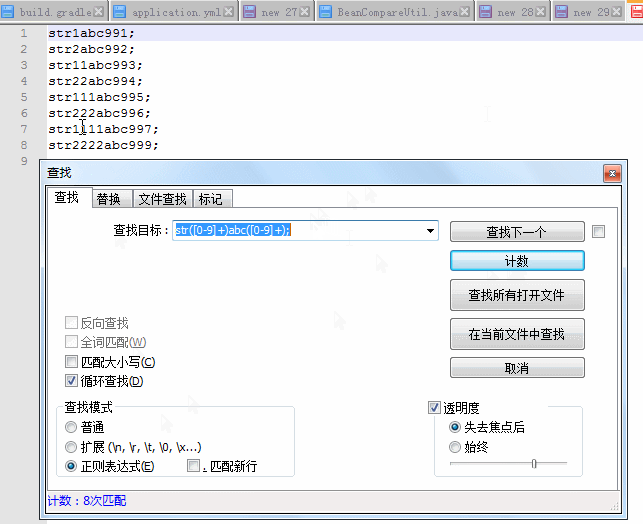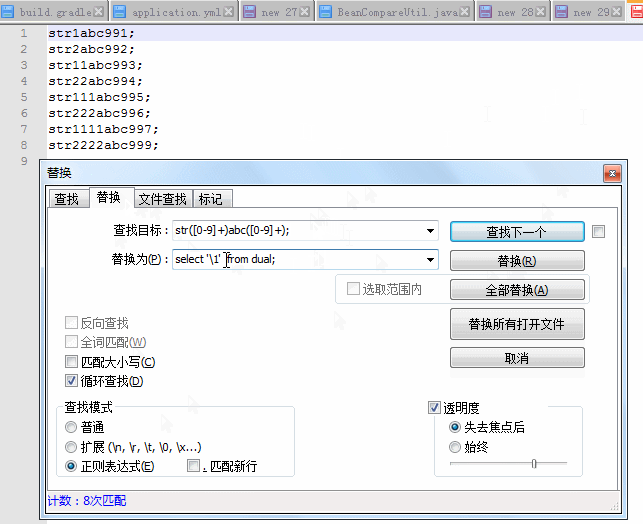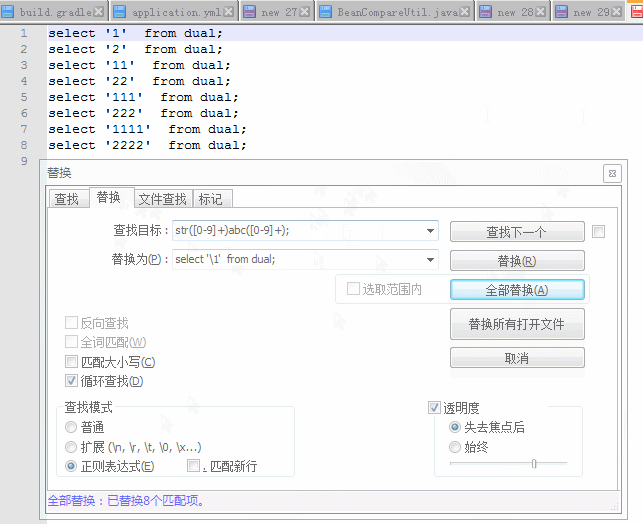
查找目标正则:str([0-9]+)abc([0-9]+);
替换目标正则:select ‘\1’ from dual;
查找目标正则解析:
str 1 abc 991 ;
str([0-9]+)abc([0-9]+);
\1 \2
1.匹配第一段
str为匹配字符串第一段str文字,如果前面还有空格或者 其他非目标字符串可以在前面加 .+ 具体含义参考1.1
2.匹配第二段
([0-9]+) 括号为用于标记匹配的区域,该区域是变动的不确定的值,每一行数据都会不一样,
这里括号中只选中0-9出现的数据,之后的**+** 代表前面的数据可以出现多次
3.匹配第三段
abc 又是匹配该位置固定出现的字符创
4.匹配第四段
([0-9]+) 如前2,略
5.匹配第五段
**;**匹配最后一个固定出现字符串,如果后面还有空格或者 其他非目标字符串可以在后添加 .+ 具体含义参考1.1
替换目标正则:
select ‘\1’ from dual;
\1为查找目标正则解析中第一个括号中匹配到的数据,用\1代替,具体为何使用 \1代替匹配的第一个动态字符串参考1.1
2.3 使用正则删除没有文字的空行
原始数据
str1abc991;
str2abc992;
str11abc993;
str22abc994;
str111abc995;
str222 abc996;
str1111abc997;
str2222abc999;
目标数据:
str1abc991;
str2abc992;
str11abc993;
str22abc994;
str111abc995;
str222 abc996;
str1111abc997;
str2222abc999;
查找目标正则:^\r|\s$
替换目标正则:
查找目标正则解析:
匹配开头到结尾都只有换行符 ^\r$$ 或者开头到结尾都是空白文字 ^\s$
替换目标正则解析:
直接替换为空,什么都不输入即可
到这里,基本上授人以鱼已经完成,其他的变化万变不离其宗,各位请参考1.1的正则或者参考notepad++官方的更多正则公式进行变化
第三部分:本人的具体案例
3.1有一个原始写好的update语句,目前需要改造为动态根据参数有无来判断更新
原始数据:
update configKey
set
configKey = #{configKey,jdbcType=VARCHAR},
configValue = #{configValue,jdbcType=VARCHAR},
configGroup = #{configGroup,jdbcType=VARCHAR},
status = #{status,jdbcType=VARCHAR},
lastUpdate = sysdate
where objCode = #{objCode,jdbcType=VARCHAR}
目标数据:
update configKey
configKey = #{configKey,jdbcType=VARCHAR},
configValue = #{configValue,jdbcType=VARCHAR},
configGroup = #{configGroup,jdbcType=VARCHAR},
status = #{status,jdbcType=VARCHAR},
lastUpdate = sysdate
where objCode = #{objCode,jdbcType=VARCHAR}
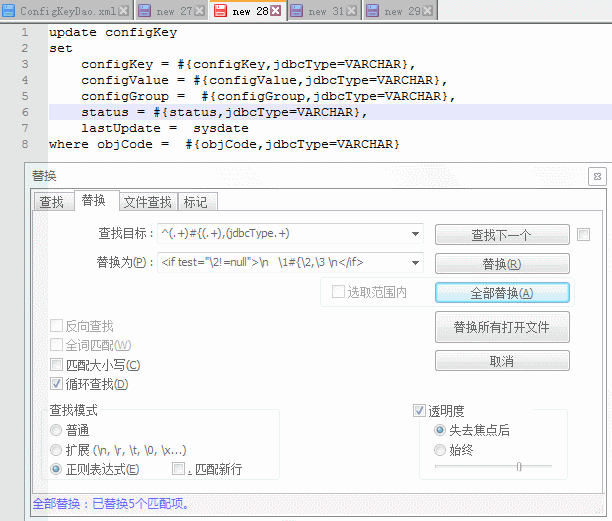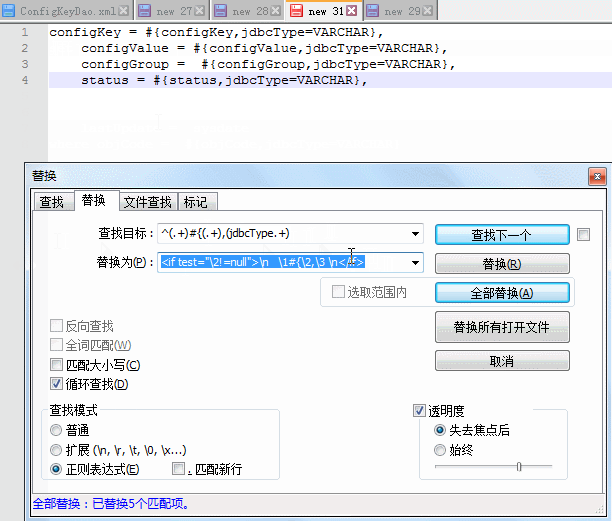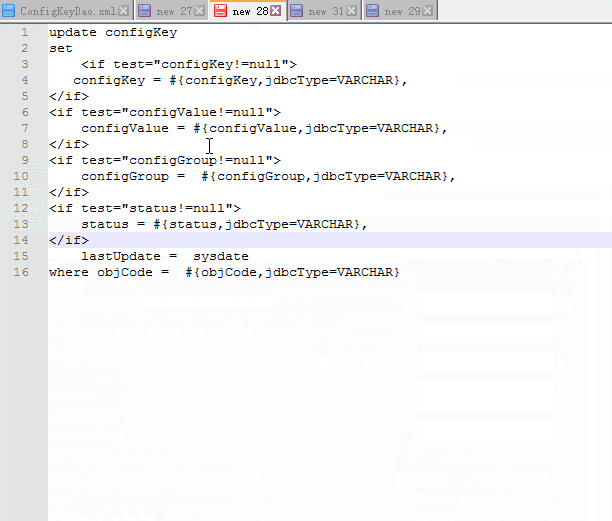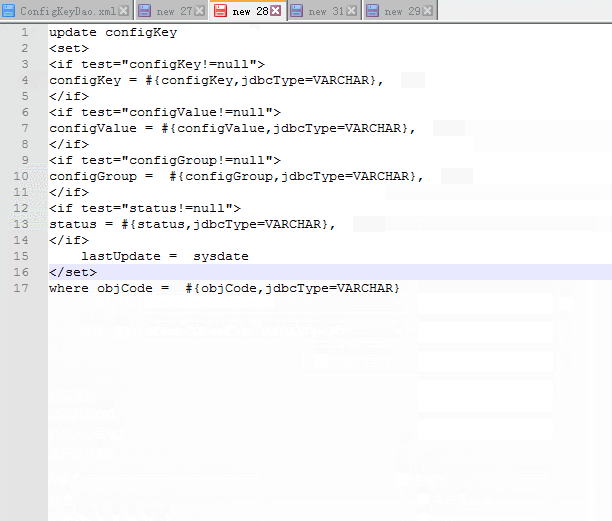
查找目标正则:^(.+)#{(.+),(jdbcType.+)
替换目标正则:\n \1#{\2,\3 \n
查找目标正则解析:
configKey = #{configKey,jdbcType=VARCHAR},
^(.+)#{(.+) ,(jdbcType.+)
\1 \2 \3
记住一点,()括号中的参数为匹配到的需要在替换表达式中使用的动态值,()括号外的参数为该行固定位置的固定标识字符
1.匹配第一段
^(.+) 为匹配字符串第一行开头到下一个标志位 #之前的所有动态字符串
2.匹配第二段
#{ 匹配该行字符串固定位置出现的固定标志位 #{
3.匹配第三段
(.+) 匹配 # 到下一个标志位 , 的所有动态字符串
4.匹配第四段
, 匹配该行字符串固定位置出现的固定标志位 ,
5.匹配第五段
(jdbcType.+) 匹配 **,**之后 jdbcType开头的到结尾的动态字符串
替换目标正则解析:
configKey = #{configKey,jdbcType=VARCHAR},
^(.+)#{(.+) ,(jdbcType.+)
\1 \2 \3
匹配到的动态字符串依次为:
\1 = configKey =
\2 = configKey
\3 = jdbcType=VARCHAR},
3.1 首字母大写转小写,其他不变
原始数据:
{
"Customer_Name": "Tom",
"Product": "car",
"Date": "2019-07-01"
}
目标数据:
{
"customer_Name": "Tom",
"product": "car",
"date": "2019-07-01"
}
查找目标正则:"([A-Z])(.+:)
替换目标正则:"\L\1\E\2
\U 将匹配项转为大写(Upper)
\L 将匹配项转为小写(Lower)
\E 终止转换(End)