多标签分类:多标签学习资源(NLP)
磕盐狗一枚,多标签文本分类疯狂踩坑,现将自己整理的一些资源分享给大家,整理不易,如果对您有帮助,请点赞或评论支持,谢谢!
一、适合入门的三篇文章
(1)Mining Multi-label Data(2010)
文章下载地址:https://link.springer.com/chapter/10.1007/978-0-387-09823-4_34#citeas
(2)A Review on Multi-Label Learning Algorithms(2014)
文章下载地址:https://ieeexplore.ieee.org/abstract/document/6471714
(3)A Tutorial on Multilabel Learning(2015)
文章下载地址:https://www.researchgate.net/publication/270337594_A_Tutorial_on_Multi-Label_Learning
阅读完以上三篇文章,可以对文本的多标签分类的方法(包括传统的机器学习方法和深度学习方法)有一定的了解。
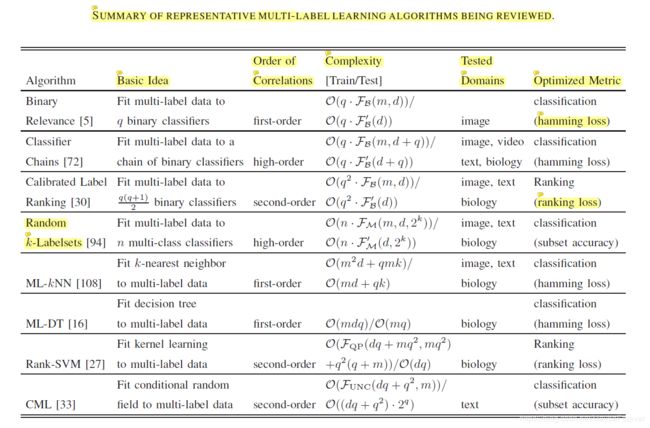
二、具有代表性的多标签学习方法综述
下图来源于论文:A Review on Multi-Label Learning Algorithms
三、多标签学习的目的
围绕着多标签数据的学习,目前为止主要的研究方面可以分为几种类型(按照研究关注度的顺序):
(1)多标签数据的分类:多标签数据的分类要实现通过数据挖掘算法运用已有多标签样本创建模型,实现对未知标签集的数据集标注。
(2)多标签数据的标签排序:多标签排序需要创建能够对预先定义的标签排名的模型。对于给定的样本,排序模型按照预测的与这个样本的相关性顺序输出所有标签。
(3)多标签数据的降维:高维数据广泛的存在于文本分类,多媒体等应用领域,而多标签数据的降维对于提高多标签学习的性能有重要的作用。
使用训练数据集构建多标签模型,然后将其应用于新的(未标记的)数据集,以获得预测。
四、代码、开源库及数据集
1、Mulan:A Java Library for Multi-Label Learning

网站地址:http://mulan.sourceforge.net/index.html (The MULAN [93] open-source Java library)
Mulan是一个用于从多标签数据集学习的开源Java库。多标签数据集由具有多个二进制目标变量的目标函数的训练示例组成。这意味着多标签数据集的每个项可以是多个类别的成员,也可以是由许多标签(类)注释的。这实际上是许多现实世界问题的本质,如图像和视频的语义注释、网页分类、直接营销、功能基因组学和音乐分类到流派和情感。
目前,该lib库包括各种最先进的算法,以执行以下主要的多标签学习任务:
- 分类。该任务涉及为给定的输入实例将标签的一个二分区输出到相关的和不相关的标签中。
- 排名。此任务涉及根据标签与给定数据项的相关性输出标签的顺序
- 分类和排名。上述两项任务的组合。
此外,lib库还提供以下功能:
- 特征选择。目前支持简单的基线方法。
- 评估。通过持续评估和交叉验证来计算各种评估度量。
如上所述,Mulan是一个lib库。因此,它只向库用户提供编程API。没有可用的图形用户界面(GUI)。通过命令行使用库的可能性目前也不受支持。
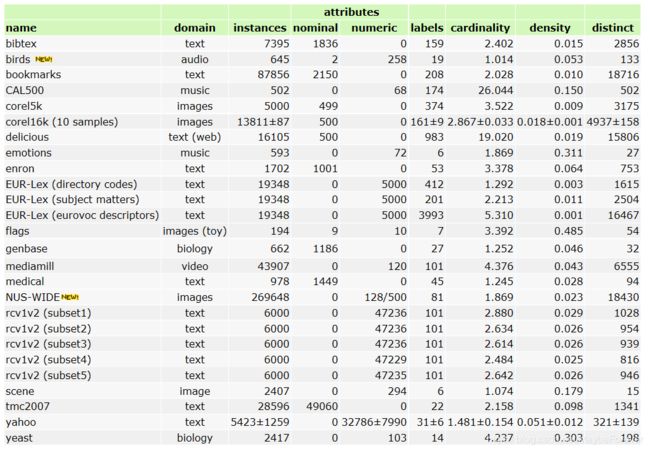
此外,MuLan还提供了多标签分类数据集,如下图所示:
2、MEKA
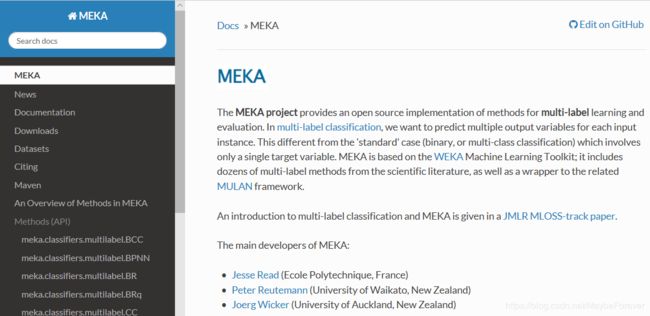
网站地址:http://meka.sourceforge.net/ (The MEKA project based on WEKA [38])
MEKA项目提供了多标签学习和评估方法的开源实现。在多标签分类中,我们希望为每个输入实例预测多个输出变量。这与只涉及单个目标变量的“标准”情况(二进制或多类分类)不同。MEKA是基于WEKA机器学习工具包的;它包括几十种多标签方法,从科学文献,以及包装到相关的Mulan框架。
此外,MEKA还提供了多标签分类数据集,如下图所示:

N = 样本个数(测试+训练)
L = 与该数据集相关的预定义标签的数量
LC = 标记基数。每个文档分配标签的平均数量
PU = 具有唯一标签组合的文档的百分比
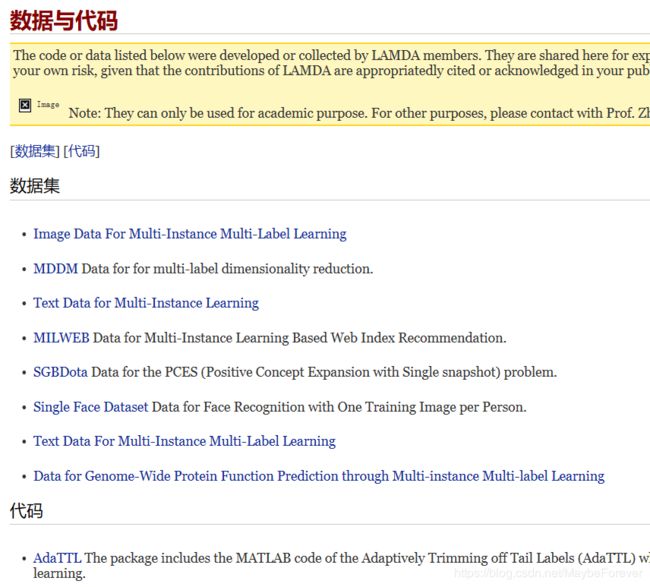
3、LAMDA(南京大学机器学习与数据挖掘研究所)

LAMDA隶属于 计算机软件新技术国家重点实验室 和 南京大学计算机科学与技术系. LAMDA 位于南京大学仙林校区计算机科学技术楼, 总部在910室,负责人是 周志华 教授.
" LAMDA" 的含义是 “Learning And Mining from DatA”. LAMDA 的主要研究兴趣包括机器学习、数据挖掘、模式识别、信息检索、演化计算、神经计算,以及相关的其他领域. 目前的主要研究内容包括:集成学习、半监督与主动学习、多示例与多标记学习、代价敏感和类别不平衡学习、度量学习、降维与特征选择、结构学习与聚类、演化计算的理论基础、增强可理解性、基于内容的图像检索、 Web 搜索与挖掘、人脸识别、 计算机辅助医疗诊断、生物信息学等.
网站地址:http://lamda.nju.edu.cn/CH.MainPage.ashx
在上述网站中,有该实验室历年发表的会议文章以及部分源代码和数据集,如下所示:
4、张敏灵 教授

网站地址:http://palm.seu.edu.cn/zhangml/
在上述网站上,有张老师历年发表的会议文章,如下图所示:

以及部分源代码和数据集,如下图所示:

5、国外的一些公开的多标签数据集
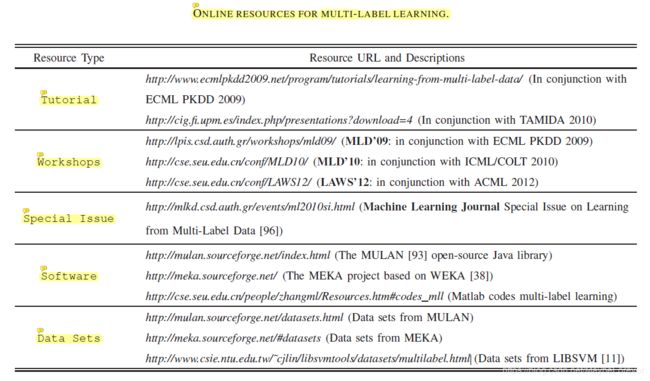
除此上述数据外,还有比较有名的库比如:RCV1-V2。在多个自然语言顶级会议的文章中,均用到此库。数据集RCV1-V2是一个路透社英文新闻文本及对应新闻类别的数据,可用于文本分类和其他自然语言处理任务。统计数据如下:
| DataSet | Total Samples | Label Sets | Words/Sample | Labels/Sample |
|---|---|---|---|---|
| RCV1-V2 | 804,414 | 103 | 123.94 | 3.24 |
五、多标签分类工具——Magpie

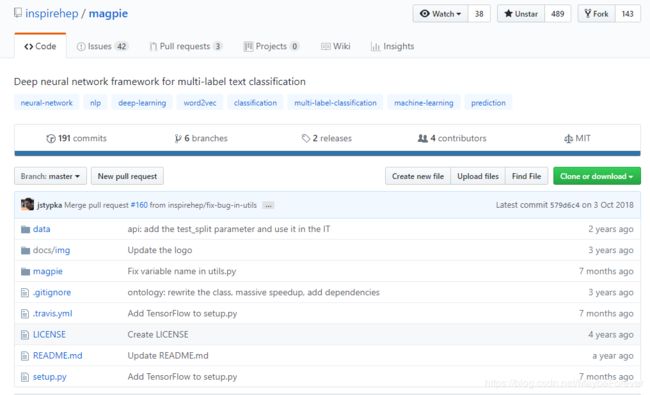
网站地址:https://github.com/inspirehep/magpie
Magpie是一个多标签标记工具,基于Tensor flow,大体分为以下三层:
- 底层:CNN/RNN 从已经分类好的文本中学习文本特征
- 中层:Keras实现CNN/RNN算法
- 顶层:封装好方法,用Python实现功能调用
由于原版Magpie只支持英文,出于需要我已手动改进使其支持中文,先占个坑,后续再写一篇文章介绍Magpie。
六、GitHub上比较完善的文本多标签分类项目
- brightmart大神
网站地址:https://github.com/brightmart/text_classification
以上,先写这么多了,后续想到的再补充!