深度学习(BOT方向) 学习笔记(2) RNN Encoder-Decoder 及 LSTM 学习
深度学习(BOT方向) 学习笔记(2) Sequence2Sequence 学习2
PS:这一个系列比较语无伦次,后期会有一个refined版的,这个系列相当于草稿
1 前言
这个系列的笔记拖了很久了,一直没时间仔细详细写,一来是因为自己能力不足,学习进度也很慢,二是真的很懒,也没有什么outline,所以一直拖着没写,现在终于挤出第二篇来了。
话说之前的第一篇,我很匆忙的写了写Sequence2Sequence RNN-Encoder-Decoder的框架,写的不是很认真,这篇博客则主要想仔细写写这个框架。最主要的目的是帮助自己理解,其次是做个留底和分享。
2 再看 RNN Encoder-Decoder框架
这里复习下Sequence2Sequence任务到底是什么,所谓的Sequence2Sequence任务主要是泛指一些Sequence到Sequence的映射问题,Sequence在这里可以理解为一个字符串序列,当我们在给定一个字符串序列后,希望得到与之对应的另一个字符串序列(如 翻译后的、如语义上对应的)时,这个任务就可以称为Sequence2Sequence了。
在现在的深度学习领域当中,通常的做法是将输入的源Sequence编码到一个中间的context当中,这个context是一个特定长度的编码(可以理解为一个向量),然后再通过这个context还原成一个输出的目标Sequence。
如果用人的思维来看,就是我们先看到源Sequence,将其读一遍,然后在我们大脑当中就记住了这个源Sequence,并且存在大脑的某一个位置上,形成我们自己的记忆(对应Context),然后我们再经过思考,将这个大脑里的东西转变成输出,然后写下来。
那么我们大脑读入的过程叫做Encoder,即将输入的东西变成我们自己的记忆,放在大脑当中,而这个记忆可以叫做Context,然后我们再根据这个Context,转化成答案写下来,这个写的过程叫做Decoder。其实就是编码-存储-解码的过程。
而对应的,大脑怎么读入(Encoder怎么工作)有一个特定的方式,怎么记忆(Context)有一种特定的形式,怎么转变成答案(Decoder怎么工作)又有一种特定的工作方式。
好了,现在我们大体了解了一个工作的流程Encoder-Decoder后,我们来介绍一个深度学习当中,最经典的Encoder-Decoder实现方式,即用RNN来实现。
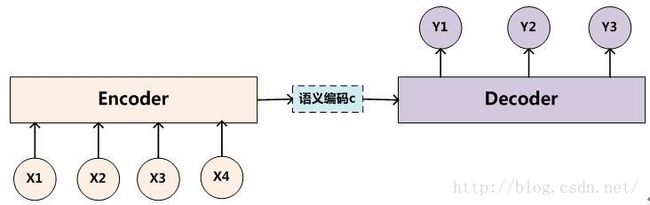
在RNN Encoder-Decoder的工作当中,我们用一个RNN去模拟大脑的读入动作,用一个特定长度的特征向量去模拟我们的记忆,然后再用另外一个RNN去模拟大脑思考得到答案的动作,将三者组织起来利用就成了一个可以实现Sequence2Sequence工作的“模拟大脑”了。
而我们剩下的工作也就是如何正确的利用RNN去实现,以及如何正确且合理的组织这三个部分了。
那么接下来,我们将详细介绍下这个模型当中经常说的RNN到底是什么?
RNN & LSTM
RNNs,即循环神经网络(Recurrent Neural Networks,RNNs)已经在众多自然语言处理(Natural Language Processing, NLP)中取得了巨大成功以及广泛应用。
RNNs通常用来处理序列数据。在传统的神经网络模型中,是从输入层到隐含层再到输出层,层与层之间是全连接的,每层之间的节点是无连接的。这种神经网络结构在很多领域取得了不俗的成绩,但是由于其网络结构的问题,使得其在面对序列问题或者和时间密切相关的问题时,表现不佳。例如,你要预测句子的下一个单词是什么,一般需要用到前面的单词,因为一个句子中前后单词并不是独立的。RNNs之所以称为循环神经网路,即一个序列当前的输出与前面的输出也有关。具体的表现形式为网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再无连接而是有连接的,并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。理论上,RNNs能够对任何长度的序列数据进行处理。但是在实践中,为了降低复杂性往往假设当前的状态只与前面的几个状态相关。
在RNN中神经元的输出可以在下一个时间戳直接作用到自身,即第i层神经元在m时刻的输入,除了(i-1)层神经元在该时刻的输出外,还包括其自身在(m-1)时刻的输出!表示成图就是这样的:
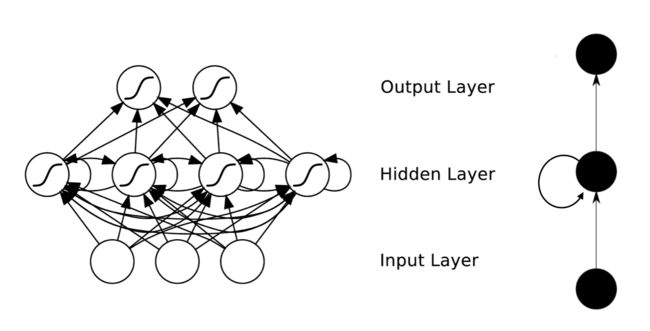
在这个典型的RNN示意图当中,RNN包含一个输入层Input Layer,一个隐含层Hidden Layer,一个输出层Output Layer。其中非常值得注意的是,在Hidden Layer部分,Hidden Layer不仅连接了Input Layer Output Layer,而且也同时连接了自己本身,所以这也是称作循环神经网络的原因所在。或许上面那张图有点不太容易懂,那么如果我们将它展开看一下,或许你就会对此有一个更加清楚的理解了:
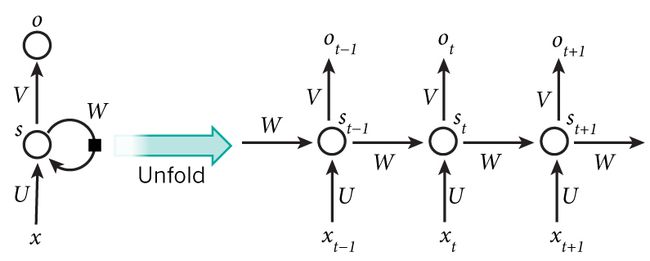
可以看到的是,对于每一个时刻输入的数据xt,rnn的隐含层的Cell都会重复使用同一个参数W b 进行计算,并且得到当前的隐含层状态St和一个输出Ot,而这个Ot是之前所有输入(x0~xt-1)的共同作用结果,这也就解决了那些当前的输出,要求考虑到之前n个元素的问题,rnn在某一个时刻的输入,是之前所有输入的共同结果。而RNN之所以是深度学习中常用的一种网络结构,其深度之处就在于其网络时间的长度(也就是网络的深度!)
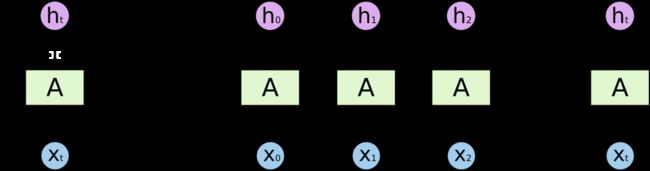
然而,RNNs虽然看起来在处理时间t的内容时,会综合考虑到之前所有时刻的内容,但是实际情况是,随时t的增大(即输入的序列很长的时候),其会面临长期依赖(Long-Term Dependencies)问题,即最开始输入到RNN的内容对当前Ot的影响会越来越小,究其原因是一开始输入RNN的内容,随着t的推进其在不停的循环传播,造成了信息的丢失。形象来说,这种丢失,就像我们人的大脑一样,短一点的句子我们看一眼还记得住,要是长一点,我们看着看着,之前看过的就忘了,只记得附近看过的几个?为了解决这个问题,发展了诸如GRU和LSTM在内的机制,用于解决这个记忆问题。简单说,GRU和LSTM并不算是一个完全独立的结构,其看起来和上图的RNN很像(其实也都是认为对RNN Cell的一种改进),GRU和LSTM主要是通过加强原RNN当中隐含层的Unit,增加了多个“门”,实现对内容的记忆、遗忘,一定程度改善了RNN的长句记忆问题。我们这里主要着重说下LSTM。
LSTM(Long Short Term Memory) ,是一种 RNN 特殊的类型,可以学习长期依赖信息。LSTM 由Hochreiter & Schmidhuber (1997)提出,并在近期被Alex Graves进行了改良和推广。在很多问题,LSTM 都取得相当巨大的成功,并得到了广泛的使用。LSTM通过记住一些长期的记忆,来改善长期依赖的问题。
首先需要再次强调的是,LSTM可以看做是RNN的一种改进版,主要是替换了其Hidden Unit的Cell,但是其依然有每一个隐含层输出的状态ht,结果的输出也是基于ht,使用方式并没有任何改变,而改变之处在于其在循环时,如何使用之前的ht-1和当前输入的xt去生成ht,下面这两张图片的对比就可以很好的说明这个问题了:
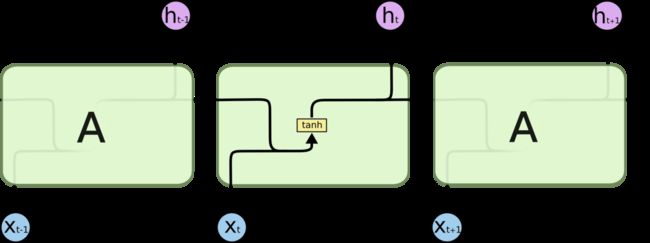
(标准RNN)
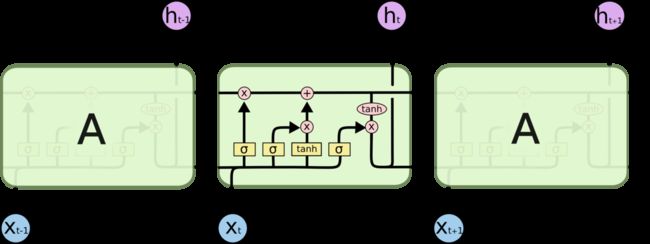
(LSTM)

(LSTM Cell结构标识在上面的图例中,每一条黑线传输着一整个向量,从一个节点的输出到其他节点的输入。粉色的圈代表 pointwise 的操作,诸如向量的和,而黄色的矩阵就是学习到的神经网络层。合在一起的线表示向量的连接,分开的线表示内容被复制,然后分发到不同的位置。)
可以看到,无论是原始的RNN还是LSTM,其基本的网络结构都是一样的,都是一个循环的网络结构,而不同在于标准RNN的在处理一个元素时其Cell的结构很简单,即将上一个时间的隐含层状态h(这里是h,上面的图是s,这里的h不是上面图的o,注意区分),同当前输入的x,使用tanh函数计算得到当前时间状态的h。而在LSTM当中就复杂了许多,可以看到其由各种五花八门的“门”构成,这里我也不想详细的讲,我只介绍其大概,如果想要仔细了解的话,请点击这里,强烈推荐阅读这个。
首先,LSTM和核心在于如何维护每一个Cell的状态(记忆),首先这里在每一个Cell当中,我们用Ct来标识当前的一个细胞状态,你可以理解为Cell的状态是LSTM单元实现记忆的核心因素。在每一个LSTM Cell中,其基本的处理流程如下图,从Ct-1输入上一个状态,途径了两个操作(第一个是“忘记门:忘记一部分之前的知识”,第二个是“更新门:记住当前时间输入的内容”)
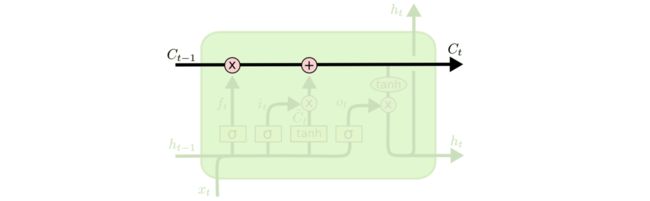
首先对于第一个忘记门:
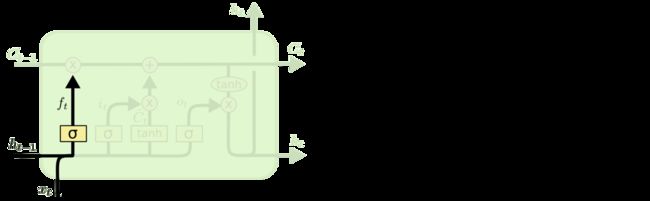
通俗解释他的作用就是,因为一个Cell的记忆内容是有限的,所以在记住新的内容(Xt)之前,势必需要忘记一部分内容,才能记住新的内容。那么在LSTM中,使用上一个LSTM里原RNN部分的隐藏层状态ht,和当前的输入xt,结合sigmod函数输出一个0~1的值,确定需要忘记的幅度ft(所以你看第一个操作就是 Ct-1 * ft)
确定了如何忘记后,就来看下如何将新的内容xt添加到Cell记忆中
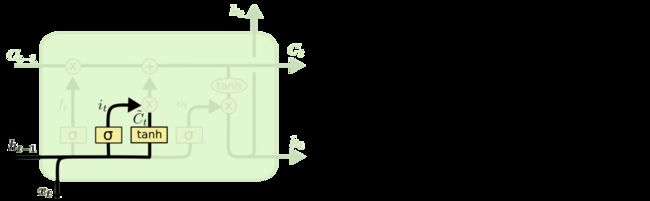
在这里,我们同样适用ht-1和x以及sigmod tanh函数去计算,这里包含两个部分。第一,sigmoid 层称 “输入门层” 决定什么值我们将要更新。然后,一个 tanh 层创建一个新的候选值向量。
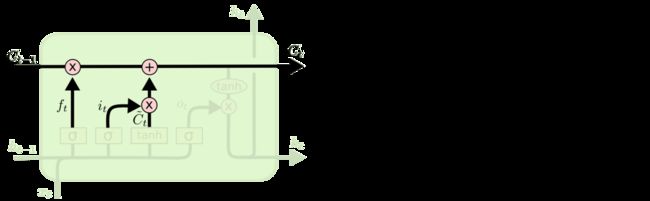
随后,我们确定好了需要更新的内容后,就可以添加到记忆当中(同部分忘记后的记忆内容相加),然后就可以得到新的记忆
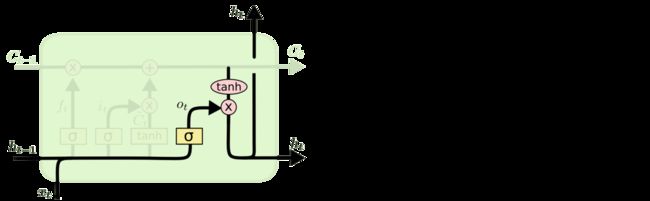
好了,当我们得到细胞状态后,我们也可以相应的计算出当前隐藏层的状态ht了:
总结
在今天介绍的Encoder-Decoder模型中,Encoder部分负责依次读入输入序列的每个单位,将其编码成一个模型的中间表示(一般为一个向量),在这里我们将其称为上下文向量c,Decoder部分负责在给定上下文向量c的情况下预测出输出序列。
并且在在自然语言处理应用中,Encoder和Decoder部分通常选择了RNN(LSTM)实现。
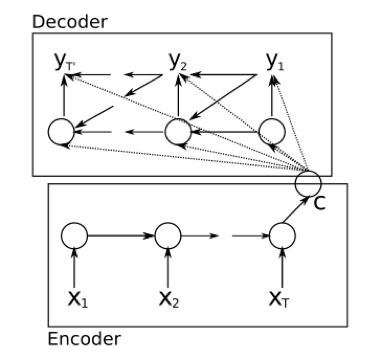
为什么我们要选择以RNN为基础的结构去实现Encoder-Decoder呢?:首先,RNN可以方便地处理可变长序列的数据。其次,由于RNN中的隐层状态随着按时序读取的输入单元而不断发生变化,因此它具有对序列顺序的建模的能力,体现在自然语言处理任务中,即为对词序的建模能力。而词序也恰恰是自然语言处理任务中需要建模的重点。最后,RNN可以作为一个语言模型来预测出给定前文的基础上下一个字符出现的概率,这个特性使得其可以应用在各种文本生成任务中预测出语法正确的输出序列,从而实现Decoder的功能。
好了,今天的内容就介绍到这里,到目前为止介绍的Encoder-Decoder模型还很初级,还有很多问题有待解决,且听下回分解。
系列目录:
Seq2Seq Chatbot 聊天机器人:基于Torch的一个Demo搭建 手札
深度学习(BOT方向) 学习笔记(1) Sequence2Sequence 学习
深度学习(BOT方向) 学习笔记(2) RNN Encoder-Decoder 及 LSTM 学习
Reference
1、http://blog.csdn.net/heyongluoyao8/article/details/48636251
2、https://www.zhihu.com/question/34681168
3、http://www.jianshu.com/p/9dc9f41f0b29
4、http://mp.weixin.qq.com/s?__biz=MzIxMjAzNDY5Mg==&mid=2650791045&idx=1&sn=823a38bc49e4ade8c8462605a85fed9f