【机器学习】python实践笔记 -- 经典监督学习模型之分类学习模型
《Python机器学习实践》笔记
参考资料:
《python机器学习及实践 从零开始通往Kaggle竞赛之路》范淼,李超2016
常用python库
- Numpy & Scipy 高级数学运算、科学计算
- Matplotlib 绘图工具包
- Scikit-learn 封装了大量机器学习模型
- Pandas 针对数据分析和处理的工具包,常用于数据预处理
监督学习经典模型

分类学习
分类学习包括二分类问题、多类分类问题、多标签分类问题等。
1.线性分类器
- 简要介绍
线性分类器是一种假设特征与分类结果存在线性关系的模型,通过累加计算每个维度的特征与各自权重的成绩来帮助类别决策。
定义x =
- 肿瘤预测代码实现
1. 关键函数
train_test_split #用于将数据集划分,一部分用于训练,一部分用于测试
一个关于train_test_split的例子,使用iris数据集
>>> import numpy as np
>>> from sklearn.model_selection import train_test_split
>>> from sklearn import datasets
>>> from sklearn import svm
>>> iris = datasets.load_iris()
>>> X_train,X_test,y_train,y_test = train_test_split(iris.data,iris.target,test_size=0.4,random_state=0)
>>> iris.data.shape,iris.target.shape
((150, 4), (150,))
>>> X_train.shape, y_train.shape
((90, 4), (90,))
>>> X_test.shape, y_test.shape
((60, 4), (60,))
iris数据集说明:
>>>iris.DESCR
:Number of Instances: 150 (50 in each of three classes)
:Number of Attributes: 4 numeric, predictive attributes and the class
:Attribute Information:
- sepal length in cm
- sepal width in cm
- petal length in cm
- petal width in cm
- class:
- Iris-Setosa
- Iris-Versicolour
- Iris-Virginica
:Summary Statistics:
============== ==== ==== ======= ===== ====================
Min Max Mean SD Class Correlation
============== ==== ==== ======= ===== ====================
sepal length: 4.3 7.9 5.84 0.83 0.7826
sepal width: 2.0 4.4 3.05 0.43 -0.4194
petal length: 1.0 6.9 3.76 1.76 0.9490 (high!)
petal width: 0.1 2.5 1.20 0.76 0.9565 (high!)
============== ==== ==== ======= ===== ====================
:Missing Attribute Values: None
:Class Distribution: 33.3% for each of 3 classes.
:Creator: R.A. Fisher
:Donor: Michael Marshall (MARSHALL%PLU@io.arc.nasa.gov)
:Date: July, 1988sklearn中的iris数据集有5个key:
[‘target_names’, ‘data’, ‘target’, ‘DESCR’, ‘feature_names’]
target_names : 分类名称
[‘setosa’ ‘versicolor’ ‘virginica’]
target:分类(150个)
(150L,)[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
feature_names: 特征名称
(‘feature_names:’, [‘sepal length (cm)’, ‘sepal width (cm)’, ‘petal length (cm)’, ‘petal width (cm)’])
data : 特征值 (150L, 4L)
data[0]:[ 5.1 3.5 1.4 0.2]
其他sklearn常见数据集参考:
代码不说谎: sklearn学习(1) 数据集
2. 分类器
在这里用到的模型是Logistic Regression和SGDClassifier,前者对参数计算采用精确解析方式,计算时间长,模型性能高;后者采用随机梯度上升算法估计模型参数,计算时间短但性能略低。一般在训练规模10万量级以上的数据,更推荐用随机梯度算法
3. 思路
基本的流程大致分为:数据预处理、数据集划分、训练、预测、性能分析。
- 数据预处理包括:将代表缺失数据的值替换为标准numpy中的NaN表示,然后丢掉/处理这些缺失数据
- 数据集划分利用train_test_split()实现
- 训练分别用LogisticRegression()和SGDClassifier(),训练集是第二步中划分出来的X_train,y_train
- 预测采用X_test
- 性能分析:用y_test比较性能,性能指标有准确率、召回率、f1-score等(适用于二分类任务)。
4. 代码
# -*- coding: utf-8 -*-
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.linear_model import SGDClassifier
from sklearn.metrics import classification_report
'''
dataset
Number of Instances: 699 (as of 15 July 1992)
Number of Attributes: 10 plus the class attribute
Attribute Information: (class attribute has been moved to last column)
# Attribute Domain
-- -----------------------------------------
1. Sample code number id number
2. Clump Thickness 1 - 10
3. Uniformity of Cell Size 1 - 10
4. Uniformity of Cell Shape 1 - 10
5. Marginal Adhesion 1 - 10
6. Single Epithelial Cell Size 1 - 10
7. Bare Nuclei 1 - 10
8. Bland Chromatin 1 - 10
9. Normal Nucleoli 1 - 10
10. Mitoses 1 - 10
11. Class: (2 for benign, 4 for malignant)
'''
# feature list
column_names = ['Sample code number','Clump Thickness','Uniformity of Cell Size','Uniformity of Cell Shape',
'Marginal Adhesion','Single Epithelial Cell Size','Bare Nuclei','Bland Chromatin','Normal Nucleoli','Mitoses', 'Class'];
data = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data',names = column_names)
#data pre-processing
#1. replace the omitted data to standard np.nan
data = data.replace(to_replace='?', value = np.nan)
#2. drop those with NaN values
data = data.dropna(how = 'any')
#print data.shape #test processed data set
'''
X_train, X_text, y_train, y_test = train_test_split(train_data, train_target, test_size, random_state)
[params]
train_data: the original data set which will be split
train_target: the splitting result
test_size: test percentage
random_state: randomize
'''
#split the data, reserving 25% of them for testing
X_train, X_text, y_train, y_test = train_test_split(data[column_names[1:10]],data[column_names[10]],test_size=0.25,random_state=33)
#print y_train.value_counts()
print y_test.value_counts()
ss = StandardScaler() #standadize data : variance = 1, mean value = 0
X_train = ss.fit_transform(X_train)
X_text = ss.transform(X_text)
lr = LogisticRegression() #initialize Logistic Regression
sgdc = SGDClassifier() #initialize SGDClassifier
lr.fit(X_train,y_train) #train
lr_y_predict = lr.predict(X_text) #predict
sgdc.fit(X_train,y_train)
sgdc_y_predict = sgdc.predict(X_text)
#print lr_y_predict
#print sgdc_y_predict
'''
True positive: 真阳性/正确预测的恶性
True negative: 真阴性/正确预测的良性
False positive:假阳性/实际是良性
False negative:假阴性/实际是恶性
'''
#prediction performance
print 'Accuracy of LR Classifier:', lr.score(X_text,y_test)
print classification_report(y_test,lr_y_predict,target_names = ['Benign','Malignant'])
print 'Accuracy of SGD Classifier:',sgdc.score(X_text,y_test)
print classification_report(y_test,sgdc_y_predict,target_names=['Benign','Malignant'])
5. 输出

2. 支持向量机
- 简介
Support Vector Classifier是根据训练样本的分布,搜索所有可能的线性分类器中最佳的那个。往往决定直线位置的样本并不是所有训练数据,而是其中两个空间间隔最小的不同类别的数据点(可能跨越直线,造成误差的点),这种可以帮助决策最优线性分类模型的数据点就是“支持向量”。Logistic回归模型由于考虑的是所有训练样本,因此不一定能获得最佳分类器。
- 手写体数据读取
利用支持向量机分类器处理scikit-learn内部集成的手写体数字图片数据集。
代码
# -*- coding:utf-8 -*-
from sklearn.datasets import load_digits #手写体数字加载器
from sklearn.model_selection import train_test_split #数据分割
from sklearn.preprocessing import StandardScaler
from sklearn.svm import LinearSVC #基于线性假设的支持向量机分类器LinearSVC
from sklearn.metrics import classification_report
import matplotlib.pyplot as plt
digits = load_digits() #获得手写体数字的数码图像,存储在digits变量中
#print digits.data.shape
images_and_labels = list(zip(digits.images, digits.target))
for index, (image, label) in enumerate(images_and_labels[:10]):
plt.subplot(2, 5, index + 1)
plt.axis('off')
plt.imshow(image, cmap=plt.cm.gray_r, interpolation='nearest')
plt.title('Image: %i' % label)
X_train,X_test, y_train,y_test = train_test_split(digits.data, digits.target, test_size=0.25, random_state=33)
ss = StandardScaler()
X_train = ss.fit_transform(X_train)
X_test = ss.transform(X_test)
lsvc = LinearSVC() #初始化线性假设的支持向量机分类器
lsvc.fit(X_train,y_train)
y_predict = lsvc.predict(X_test)
print 'The Accuracy of Linear SVC is',lsvc.score(X_test,y_test)
print classification_report(y_test,y_predict,target_names=digits.target_names.astype(str))
plt.show()

性能分析

特点
SVC可以在海量甚至高纬度数据中筛选对预测任务最为有效的少数训练样本,但需要消耗更多的计算代价。
3. 朴素贝叶斯(Naive Bayes)
- 简介
朴素贝叶斯单独考量每一维度特征被分类的条件概率,进而综合这些概率并对其所在的特征向量做分类预测。因此这个模型的基本数学假设是:各个维度上的特征被分类的条件概率之间是相互独立的。
简单来说,朴素贝叶斯的思想就是:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大就认为此待分类项属于哪个类别。
- 贝叶斯定理
注:P(A|B)表示在B发生的前提下,A发生的概率。
- 朴素贝叶斯分类的原理和流程
流程:
- 设x = {a1,a2, … am}为一个待分类项,每个a为x的一个特征属性;
- 类别集合C = {y1, y2, … yn}
- 计算P(y1|x), P(y2|x), … P(yn|x)
- 如果P(yk|x) = max{ P(y1|x), P(y2|x), … P(yn|x) } 则x属于yk
那么,关键步骤就是计算第三步中的各个条件概率。可以这样做:
a. 找到一个已分类的待分类项集合作为训练集;
b. 统计在各个类别下各个特征属性的条件概率估计:
- P(a1|y1), P(a2|y1), P(a3|y1) … P(am|y1);
- P(a1|y2), P(a2|y2), P(a3|y2) … P(am|y2);
P(a1|yn), P(a2|yn), P(a3|yn)… P(am|yn)
c. 如果各个特征属性是条件独立的,就可以有如下推导
P(x|yi)=P(x|yi)P(yi)P(x)P(x|yi)P(yi)=P(a1|yi)P(a2|yi)...P(am|yi)=P(yi)∏j=1mP(aj|yi)
- 读取新闻文本的数据细节
# -*- coding:utf-8 -*-
from sklearn.datasets import fetch_20newsgroups #导入新闻数据抓取器
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer #文本特征向量转化模块
from sklearn.naive_bayes import MultinomialNB #导入朴素贝叶斯
from sklearn.metrics import classification_report
news = fetch_20newsgroups(subset = 'all')
#print len(news.data)
#print news.data[0]
X_train, X_test, y_train,y_test = train_test_split(news.data,news.target,test_size=0.25,random_state=33)
vec = CountVectorizer()
X_train = vec.fit_transform(X_train) #文本转化为特征向量
X_test = vec.transform(X_test)
mnb = MultinomialNB()
mnb.fit(X_train,y_train)
y_predict = mnb.predict(X_test)
print 'The accuracy of Naive Bayes Classifier is ', mnb.score(X_test,y_test)
print classification_report(y_test,y_predict,target_names=news.target_names)

- 总结
朴素贝叶斯模型广泛用于海量互联网文本分类任务,有较强的特征条件独立假设,因此模型预测需要的估计参数规模从幂指数量级降到线性量级。但是这种模型在其他数据特征关联性较强的分类任务上性能表现不佳。
4. k邻近(KNN)
KNN分类算法是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 KNN方法虽然从原理上也依赖于极限定理,但在类别决策时,只与极少量的相邻样本有关。由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合。
# -*- coding:utf-8 -*-
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier #k邻近分类器
from sklearn.metrics import classification_report
iris = load_iris()
X_train,X_test,y_train,y_test = train_test_split(iris.data,iris.target, test_size=0.25, random_state = 33)
ss = StandardScaler()
X_train = ss.fit_transform(X_train)
X_test = ss.transform(X_test)
knc = KNeighborsClassifier()
knc.fit(X_train,y_train)
y_predict = knc.predict(X_test)
print 'The Accuracy of K-nearest Neighbor Classifier is ', knc.score(X_test,y_test)
print classification_report(y_test,y_predict,target_names=iris.target_names)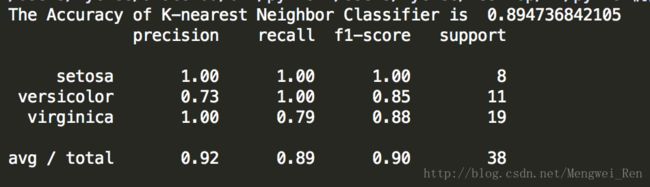
5. 决策树
logistics regression和SVC都是基于线性假设的模型,很多场景都不适用。决策树是描述非线性关系的不二之选。在搭建多层决策树的时候,模型在学习时就需要考虑特征节点的选取顺序,常用方法是信息熵、基尼不纯性(Gini Impurity)
- 用决策树实现泰坦尼克号数据查验
#-*- coding:utf-8 -*-
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction import DictVectorizer #特征转换器,抽取特征
from sklearn.tree import DecisionTreeClassifier #决策树分类器
from sklearn.metrics import classification_report
titanic = pd.read_csv('http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt')
#print titanic.head() #查看数据前几行
#print titanic.info() #查看数据的统计特性
X = titanic[['pclass','age','sex']] #list in list
y = titanic['survived']
#print X.info()
'''
Data columns (total 3 columns):
pclass 1313 non-null object
age 633 non-null float64
sex 1313 non-null object
dtypes: float64(1), object(2)
'''
#preprocessing
X['age'].fillna(X['age'].mean(),inplace=True)
#print 'Filling in the age data: '
#print X.info()
#split the data
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.25,random_state=33)
vec = DictVectorizer(sparse=False)
X_train = vec.fit_transform(X_train.to_dict(orient='record'))
#object类型的特征都被单独剥离,独成一列,数值型的保持不变
'''
print vec.feature_names_
['age', 'pclass=1st', 'pclass=2nd', 'pclass=3rd', 'sex=female', 'sex=male']
'''
X_test = vec.transform(X_test.to_dict(orient = 'record'))
dtc = DecisionTreeClassifier()
dtc.fit(X_train,y_train)
y_predict = dtc.predict(X_test)
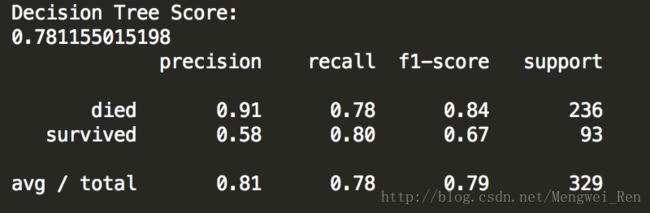
print 'Decision Tree Score: '
print dtc.score(X_test,y_test)
print classification_report(y_predict, y_test,target_names=['died','survived'])
- 总结
决策树的判断逻辑非常直观,有清晰的可解释性,也方便了模型的可视化。决策树模型仍属于有参数模型,需要更多时间在训练数据上。
6. 集成模型
- 简介
集成分类模型是综合考量多个分类器的预测结果,进而做出决策。大体方式分为两种:
1) 利用相同的训练数据同时搭建多个独立的分类模型,然后通过投票的方式,少数服从多数最终做出分类决策。代表性模型是随机森林分类器(Random Forest Classifier),即在相同训练数据上同时搭建多棵决策树。
2) 按照一定次序搭建多个分类模型,这些模型之间彼此存在依赖关系。代表性的是梯度提升决策树(Gradient Tree Boosting),这里的每一棵决策树在生成过程中都会尽量降低整体集成模型在训练集上的拟合误差。
- 比较决策树、随机森林、梯度提升决策树的性能(仍以titanic为例)
#-*- coding:utf-8 -*-
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction import DictVectorizer #特征转换器,抽取特征
from sklearn.tree import DecisionTreeClassifier #决策树分类器
from sklearn.ensemble import RandomForestClassifier #随机森林分类器
from sklearn.ensemble import GradientBoostingClassifier #梯度提升决策树
from sklearn.metrics import classification_report
titanic = pd.read_csv('http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt')
#print titanic.head() #查看数据前几行
#print titanic.info() #查看数据的统计特性
X = titanic[['pclass','age','sex']] #list in list
y = titanic['survived']
#print X.info()
'''
Data columns (total 3 columns):
pclass 1313 non-null object
age 633 non-null float64
sex 1313 non-null object
dtypes: float64(1), object(2)
'''
#preprocessing
X['age'].fillna(X['age'].mean(),inplace=True)
#print 'Filling in the age data: '
#print X.info()
#split the data
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.25,random_state=33)
vec = DictVectorizer(sparse=False)
X_train = vec.fit_transform(X_train.to_dict(orient='record'))
#object类型的特征都被单独剥离,独成一列,数值型的保持不变
'''
print vec.feature_names_
['age', 'pclass=1st', 'pclass=2nd', 'pclass=3rd', 'sex=female', 'sex=male']
'''
X_test = vec.transform(X_test.to_dict(orient = 'record'))
#使用单一决策树
dtc = DecisionTreeClassifier()
dtc.fit(X_train,y_train)
dtc_y_pred = dtc.predict(X_test)
#使用随机森林
rfc = RandomForestClassifier()
rfc.fit(X_train,y_train)
rfc_y_pred = rfc.predict(X_test)
#使用梯度提升决策树
gbc = GradientBoostingClassifier()
gbc.fit(X_train,y_train)
gbc_y_pred = gbc.predict(X_test)
print 'The Accuracy of decision tree: ', dtc.score(X_test,y_test)
print classification_report(dtc_y_pred, y_test)
print '---------------------------------------------------------'
print 'The Accuracy of random forest classifier: ' , rfc.score(X_test,y_test)
print classification_report(rfc_y_pred, y_test)
print '---------------------------------------------------------'
print 'The Accuracy of gradient tree boosting: ' , gbc.score(X_test,y_test)
print classification_report(gbc_y_pred, y_test)

- 总结
集成模型可以整合多种模型, 或者多次就同一个类型的模型建模,但估计参数的过程收到概率影响,所以有一定的不确定性,因此集成模型在训练时要耗费更多时间。