堆(heap)和栈(stack)有什么区别?
一、Java内存模型
1.哪里用到了内存划分?
(1)虚拟机执行Java代码时,首先要把字节码文件加载到内存,那么这些类的信息都存放在哪个区域呢?
(2)当我们创建一个对象实例的时候,虚拟机要为对象分配内存,虚拟机是如何分配内存的呢?
2.Java内存模型(Java虚拟机的内存是如何划分的?虚拟机内存划分机制?)

(1)程序计数器:是线程私有的,JVM支持多线程同时执行,存放当前正在执行的指令地址,通过改变这个计数器的值来确定下一行需要执行的字节码指令;
(2)虚拟机栈:是线程私有的,每一个线程在这个区域都有一块所属的区域,生命周期和线程相同。虚拟机栈描述的是Java方法执行的内存模型。
当创建一个线程的时候就会存在一个虚拟机栈,当方法执行时就会创建一个栈帧,栈帧用于存储局部变量表(方法参数、方法内部定义的局部变量,包括各种基本数据类型和对象引用类型等信息)、操作数栈、动态连接等消息。方法的调用到执行完成就对应着一个栈帧在虚拟机栈中入栈到出栈的过程。
(3)本地方法栈:线程私有的,为虚拟机使用到的native方法(本地方法)服务。
(4)堆:线程共享的一块区域,是Java虚拟机管理内存最大的一块,在虚拟机启动时创建,此内存区域用来存放对象实例。————从垃圾回收(内存回收)角度来看,分代就是在这里分的,堆是垃圾收集器管理的主要区域。
(5)方法区:是线程共享的内存区域,主要存放已被虚拟机加载的类信息,常量、静态变量、即时编译器编译后的代码数据。
运行时常量池:是方法区的一部分,用于存放编译期间生成的各种字面量(文本字符串,声明为final的常量值)和符号引用(虚拟机在类加载时将符号引用转换为直接引用)。比如,static常量、int常量、String常量;
二、堆(heap)和栈(stack)有什么区别?
1.区别
(1)栈(stack)与堆(heap)都是Java用来在Ram中存放数据的地方。Java自动管理栈和堆,程序员不能直接地设置栈或堆。
三、栈(8种基本类型):的存取速度比堆快,栈的数据可以共享,缺点是,存在栈中的数据大小与生存期必须是确定的。
1.int a = 3;
2.栈的数据是共享的,int a = 3;int b = 3;。编译器先处理int a = 3;首先它会在栈中创建一个变量为a的引用,然后查找有没有字面值为3的地址,没找到,就开辟一个存放3这个字面值的地址,然后将a指向3的地址。接着处理int b = 3;在创建完b的引用变量后,由于在栈中已经有3这个字面值,便将b直接指向3的地址。这时就会出现了a与b同时均指向3。
四、堆(包装类数据):可以在运行时动态分配内存,Java的垃圾收集器会自动收走这些不再使用的数据,存取速度较慢。包装类数据
1.new()一个新的对象;
2.String是一个特殊的包装类数据。即可以用String str = new String("abc");的形式来创建,也可以用String str = "abc";的形式来创建。(存放在栈中)
3.String str = "abc"内存分配情况(特殊的常量池)
JVM首先在这个常量池中查询"abc"的对象。若找不到内容为"abc"的字符串对象,那么会创建一个数值为"abc"的字符串对象,然后将刚创建的对象的引用放入到字符串常量池中, 并且将引用返回给变量 str。若找到,则将已经储存在堆中的这个字符串对象的引用,传给 str。保证了常量池中的每一个相同内容的字符串对象只能有一个。

五、举例
1.String str = new String("abc");JVM将产生的对象存储在堆中,但是将它的引用 str 存储在 栈 stack 。
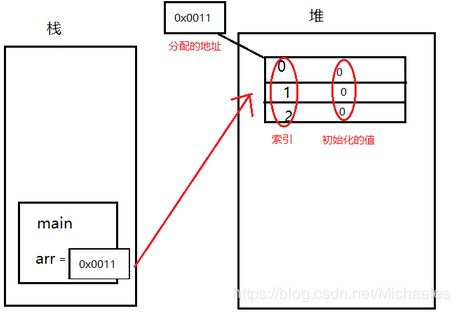
2.int [] arr=new int [3];
(1)基本类型存储在栈中,不用new,包装类存储在堆里,可以为null;