Python3:文字识别
1. 环境
操作系统 |
Win10 |
IDE |
Eclipse (Oxygen 4.7)+ PyDev 5.9.2 (JDK1.8) |
Python |
3.5 |
Pytesseract |
0.2.0 |
Pillow |
Pillow-5.0.0-cp35-cp35m-win_amd64.whl |
2. 安装pytesseract、pillow
被坑死了!晚上酒足饭饱洗漱完毕,闲来无事,在网上随便看看,就看到了这么一篇博文《Python3一行代码实现图片文字识别》,能不试试吗?!
看代码中导包语句,有用到pytesseract和PIL,在Python命令行试了一下,没有这两个包,那就装pytesseract吧,装PIL吧。 装pytesseract还挺顺利,在命令行pip install pytesseract就好了
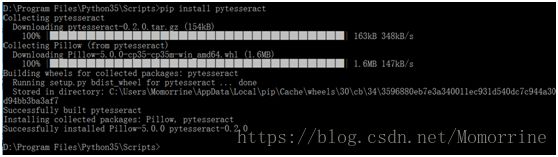
但装PIL的时候告诉我找不到合适的版本:

好吧,问一下百度吧,说是PIL只支持Python2.7,不支持Python3.x,可以装pillow支持Python3.x,仔细看了一下上面安装pytesseract时的提示信息,其实已经安装了pillow。
这下子敲上例子中的四行代码,就可以看到输出文字了吧?你太天真了!
3. 修改pytesseract.py+安装tesseract-ocr
又报错了:
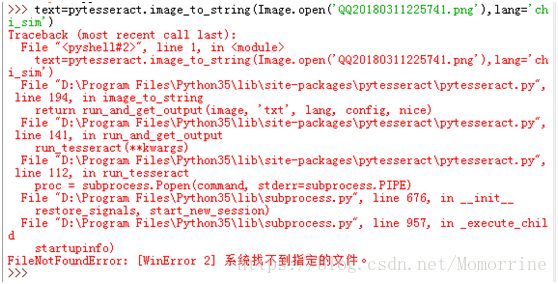
继续百度吧,说是要把Python根目录\Lib\site-packages\pytesseract\pytesseract.py中的tesseract_cmd ='tesseract'改成tesseract_cmd= r'C:\Program Files (x86)\Tesseract-OCR \tesseract.exe',改吧。
可是等等,我的C:\ProgramFiles (x86)\下没有Tesseract-OCR更没有tesseract.exe啊,怎么我装了pytesseract没tesseract.exe的啊,再一搜,Tesseract-OCR需要单独安装的,下了安装包安装吧。
装完,把tesseract_cmd也改了,满心欢喜地以为这下该搞定了,还是错,错,错……
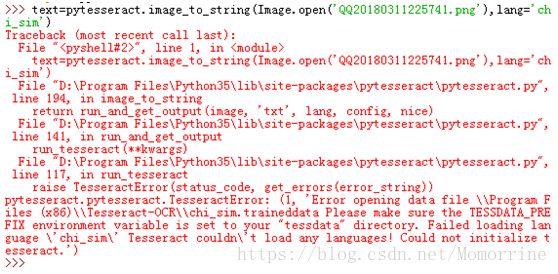
4. 安装中文文字识别库
这大晚上的,我真的好无助啊,手脚都冰凉冰凉的了,唯一陪伴我的只有百度,只能继续找她商量啊。
原来还缺少简体中文识别包,下了chi_sim.traineddata放到D:\Program Files(x86)\Tesseract-OCR\tessdata下,再次哆哆嗦嗦地敲下那行代码,打回车,还好还好,没报错,打印吧。

虽然有错字,呃,图片如下,用的是原文作者的,总算是能看到结果了,也算是大差不差的。

唉,什么事情还是得自己动手试试才知道是怎么回事,所谓一行代码,原来背后这么多故事,哈!
5. Eclipse中的尝试
上面都是在 Python 命令行中试的,在 Eclipse 中创建了 PyDev Module 将之前的代码拷贝过去后运行,又报错了: 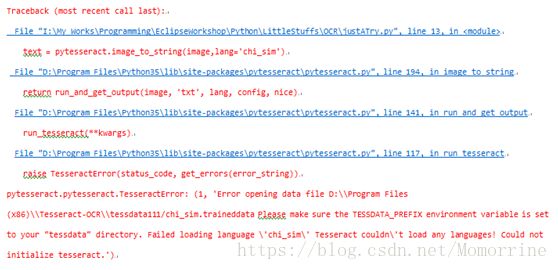
需要设置环境变量TESSDATA_PREFIX为tesseract-ocr的tessdata,并重启Eclipse。

最后只想说一句,用pytesseract+tesseract-ocr的识别度并不高,而且对图片上字体变化的适应性很差,可以看一下下面两个图片识别结果对比:

识别结果为
江雪
千山鸟飞绝 , 万径人蹈灭。
孤舟褪笠翁 , 独钓寒江雪。

识别结果为
江雪
无山恩飞纳 , 万径人医
答翩 , 独钎銮
6. 参考文献
[1] Python3一行代码实现图片文字识别 http://blog.csdn.net/qiushi_1990/article/details/78041375
[2] python 安装PIL (Python Imaging Library )出错Could not find a version that satisfies therequirement PIL https://www.3sh.cc/detail-325-python_pil_image_library.html
[3] Python pytesseract WinError 2 https://blog.csdn.net/supercooly/article/details/51314659