linux查看磁盘使用情况(一)
妈的今天由于传输文件到服务器上,真的是被坑死了,"/"根目录下面挂载了 40G的磁盘空间,由于传输量比较大 ,次数比较多,导致磁盘空间不足,妈的,坑了我半天,一直在找方法,怎么传软件到服务器,因为这边服务器有那个安全认证,运维工具,所以很难受。。。
直到最后才意识到会不会是空间的问题,一查果然,磁盘空间不足了,我的妈耶,搞了我大半天的时间。所以呢,为了加深一下印象,特此写篇博客,把磁盘空间操作,恶补一下,要有这种意识了以后。。。
一、df 相关
df 是来自于coreutils 软件包,系统安装时,就自带的;我们通过这个命令可以查看磁盘的使用情况以及文件系统被挂载的位置;
其它的参数请参考 #man df
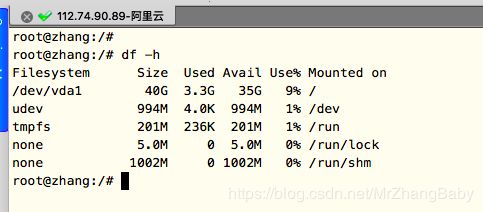
1.查看当前目录
命令: df -h (统一每个目录下磁盘的整体情况)
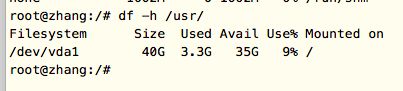
2.查看指定目录
在命令后直接放目录名,比如查看“usr”目录使用情况:
命令: df -h /usr/
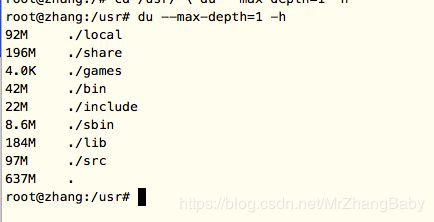
第二:具体查看文件夹的占用情况。
1.查看当前目录每个文件夹的情况。
命令: du --max-depth=1 -h (最后一行统计整体占用多少磁盘空间)
2.指定目录
只要在命令后直接根目录名,以目录“/usr/local”为例
命令如下: du --max-depth=1 -h /usr/local
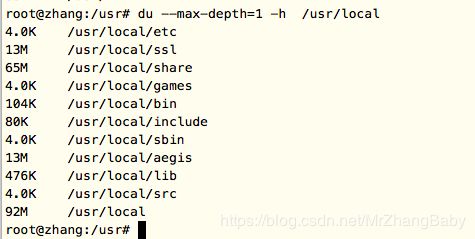
第三:计算文件夹大小
为了快算显示,同时也只是想查看目录整体占用大小。可以直接使用du -sh 命令,如果想查看指定目录,直接在命令后根目录即可。
命令: du -sh /usr/

第四:小结
其中df -h和du -sh使用的比较多,一个统计整体磁盘情况,一个看单独目录点用情况,而命令du --max-depth=1 -h查看了目录下文件夹占用情况,使用比较少,可以用du -sh代替,而且命令较长,当然并不是说它没用。
Linux df命令:
Linux df命令用于显示目前在Linux系统上的文件系统的磁盘使用情况统计。
语法
df [选项]... [FILE]...
- 文件-a, --all 包含所有的具有 0 Blocks 的文件系统
- 文件--block-size={SIZE} 使用 {SIZE} 大小的 Blocks
- 文件-h, --human-readable 使用人类可读的格式(预设值是不加这个选项的...)
- 文件-H, --si 很像 -h, 但是用 1000 为单位而不是用 1024
- 文件-i, --inodes 列出 inode 资讯,不列出已使用 block
- 文件-k, --kilobytes 就像是 --block-size=1024
- 文件-l, --local 限制列出的文件结构
- 文件-m, --megabytes 就像 --block-size=1048576
- 文件--no-sync 取得资讯前不 sync (预设值)
- 文件-P, --portability 使用 POSIX 输出格式
- 文件--sync 在取得资讯前 sync
- 文件-t, --type=TYPE 限制列出文件系统的 TYPE
- 文件-T, --print-type 显示文件系统的形式
- 文件-x, --exclude-type=TYPE 限制列出文件系统不要显示 TYPE
- 文件-v (忽略)
- 文件--help 显示这个帮手并且离开
- 文件--version 输出版本资讯并且离开
实例
显示文件系统的磁盘使用情况统计:
# df Filesystem 1K-blocks Used Available Use% Mounted on /dev/sda6 29640780 4320704 23814388 16% / udev 1536756 4 1536752 1% /dev tmpfs 617620 888 616732 1% /run none 5120 0 5120 0% /run/lock none 1544044 156 1543888 1% /run/shm
第一列指定文件系统的名称,第二列指定一个特定的文件系统1K-块1K是1024字节为单位的总内存。用和可用列正在使用中,分别指定的内存量。
使用列指定使用的内存的百分比,而最后一栏"安装在"指定的文件系统的挂载点。
df也可以显示磁盘使用的文件系统信息:
# df test Filesystem 1K-blocks Used Available Use% Mounted on /dev/sda6 29640780 4320600 23814492 16% /
用一个-i选项的df命令的输出显示inode信息而非块使用量。
df -i Filesystem Inodes IUsed IFree IUse% Mounted on /dev/sda6 1884160 261964 1622196 14% / udev 212748 560 212188 1% /dev tmpfs 216392 477 215915 1% /run none 216392 3 216389 1% /run/lock none 216392 8 216384 1% /run/shm
显示所有的信息:
# df --total Filesystem 1K-blocks Used Available Use% Mounted on /dev/sda6 29640780 4320720 23814372 16% / udev 1536756 4 1536752 1% /dev tmpfs 617620 892 616728 1% /run none 5120 0 5120 0% /run/lock none 1544044 156 1543888 1% /run/shm total 33344320 4321772 27516860 14%
我们看到输出的末尾,包含一个额外的行,显示总的每一列。
-h选项,通过它可以产生可读的格式df命令的输出:
# df -h Filesystem Size Used Avail Use% Mounted on /dev/sda6 29G 4.2G 23G 16% / udev 1.5G 4.0K 1.5G 1% /dev tmpfs 604M 892K 603M 1% /run none 5.0M 0 5.0M 0% /run/lock none 1.5G 156K 1.5G 1% /run/shm
我们可以看到输出显示的数字形式的'G'(千兆字节),"M"(兆字节)和"K"(千字节)。
这使输出容易阅读和理解,从而使显示可读的。请注意,第二列的名称也发生了变化,为了使显示可读的"大小"。
二、fdsik
fdisk 是一款强大的磁盘操作工具,来自util-linux软件包,我们在这里只说他如何查看磁盘分区表及分区结构;参数 -l ,通过-l 参数,能获得机器中所有的硬盘的分区情况;
代码:
[root@localhost beinan]# fdisk -l Disk /dev/hda: 80.0 GB, 80026361856 bytes 255 heads, 63 sectors/track, 9729 cylinders Units = cylinders of 16065 * 512 = 8225280 bytes Device Boot Start End Blocks Id System /dev/hda1 * 1 765 6144831 7 HPFS/NTFS /dev/hda2 766 2805 16386300 c W95 FAT32 (LBA) /dev/hda3 2806 7751 39728745 5 Extended /dev/hda5 2806 3825 8193118+ 83 Linux /dev/hda6 3826 5100 10241406 83 Linux /dev/hda7 5101 5198 787153+ 82 Linux swap / Solaris /dev/hda8 5199 6657 11719386 83 Linux /dev/hda9 6658 7751 8787523+ 83 Linux |
在上面Blocks中,表示的是分区的大小,Blocks的单位是byte ,我们可以换算成M,比如第一个分区/dev/hda1的大小如果换算成M,应该是6144831/1024=6000M,也就是6G左右,其实没有这么麻烦,粗略的看一下把小数点向前移动三位,就知道大约的体积有多大了;
System 表示的文件系统,比如/dev/hda1 是NTFS格式的;/dev/hda2 表示是fat32格式的文件系统;.
在此例中,我们要特别注意的是/dev/hda3分区,这是扩展分区;他下面包含着逻辑分区,其实这个分区相当于一个容器;从属于她的有 hda5,hda6,hda7,hda8,hda9 ;
我们还注意到一点,怎么没有hda4呢?为什么hda4没有包含在扩展分区?一个磁盘最多有四个主分区; hda1-4算都是主分区;hda4不可能包含在扩展分区里,另外扩展分区也算主分区;在本例中,没有hda4这个分区,当然我们可以把其中的一个分区设置为主分区,只是我当时分区的时候没有这么做而已;
再仔细统计一下,我们看一看这个磁盘是不是还有空间?hda1+hda2+hda3=实际已经分区的体积,所以我们可以这样算 hda1+hda2+hda3=6144831+16386300+39728745 = 62259876 (b),换算成M单位,小数点向前移三位,所以目前已经划分好的分区大约占用体积是62259.876(M),其实最精确的计算62259876/1024=60800.67(M);而这个磁盘大小是80.0 GB (80026361856byte),其实实际大小也就是78150.744(M);通过我们一系列的计算,我们可以得出这个硬盘目前还有使用的空间;大约还有18G未分区的空间;
fdisk -l 能列出机器中所有磁盘的个数,也能列出所有磁盘分区情况;比如:
代码: fdisk -l
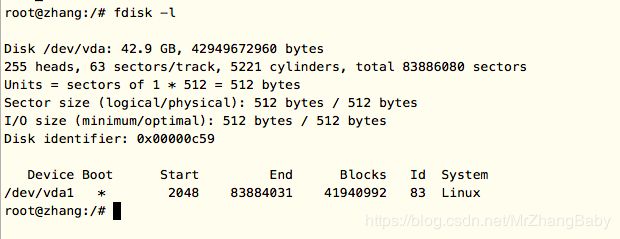
通过上面我们可以知道此机器有两块硬盘,我们也可以指定fdisk -l 来查看其中一个硬盘的分区情况;
代码: fdisk -l /dev/vda1
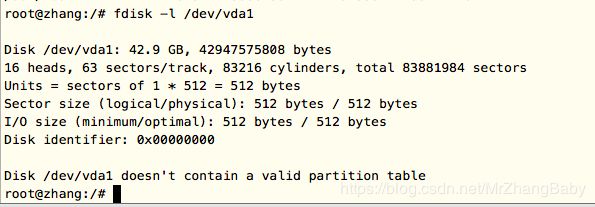
通过上面情况可以知道,在/dev/sda 这个磁盘中,只有一个分区;使用量差不多是百分百了;
我们还可以来查看 /dev/hda的
代码: fdisk -l /dev/vda
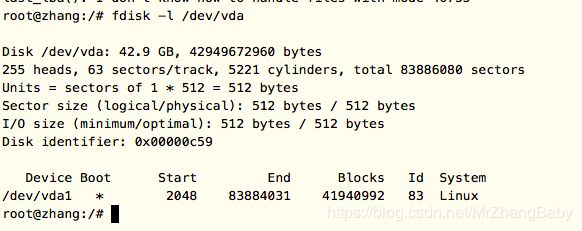
自己试试看?
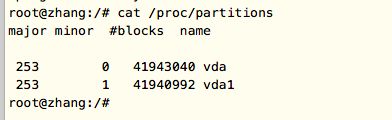
查看目前机器中的所有磁盘及分区情况:
代码: cat /proc/partitions