python提升计算速度的方法
文章目录
- 传统方法
- 1对称矩阵(symmetric matrix)
- 2 数据提取
- 3 使用numpy
- 4. 避免函数互相调用
持续更新中…
传统方法
这里传统方法指的是可以显而易见的方法,比如for循环等等的优化
1对称矩阵(symmetric matrix)
比如如下矩阵

沿着主对角线,左右两边是对称的。
传统情况下,大家可能在给矩阵元素赋值时,采用的是
for i in range(len(matrix)):
for j in range(len(matrix)):
if i == j:
mat[i][j]=...
else:
mat[i][j]=...
这里对i,j都循环,比如矩阵大小为10*10,那么循环了100次
由于矩阵对称,所以实际上可以减少循环次数。
在循环体时,j的循环可以从i开始,然后另对角线两边相等即可,如下
for i in range(4):
for j in range(i,4):
if i==j:
mat[i][j] = ...
else:
mat[i][j] = ...
mat[j][i] = mat[i][j]
在计算数据量比较大的时候,特别是循环体比较多的时候,这个时候一般有比较好的提升速度。
比如我在计算某稍微复杂的循环时候,速度从0.18分钟提升到0.13分钟,提升27%的速度。增加循环次数之后从1.61提升到1.185,提升26%
2 数据提取
假如已经在文本中保存有 x = x ( ℓ ) x=x(\ell) x=x(ℓ)的数据( ℓ 从 1 变 化 到 1000 \ell从1变化到1000 ℓ从1变化到1000),当存在循环体时,不要将文本在循环体中调用,而应该放到循环体外。即避免多次调用,实现一次调用即可
data = np.loadtxt('x.txt')
for l in range(len(x))
data[l]...
避免如下
for l in range(len(x))
data = np.loadtxt('x.txt')
data[l]...
3 使用numpy
1, 使用numpy进行矩阵数组计算,矢量运算等,而不是python自身函数。
由于numpy很多是c-based, 运算速度可以接近c,我们选择numpy来进行数据处理。
以numpy.sum()求和为例
a) 使用for来求和
import numpy as np
import time
np.random.seed(0) #种子生成器
x = np.random.randint(1,100,20000000) #产生2千万个1-100之间的整数矢量
y = 0
s = time.time()
for i in range(len(x)): #用for来求和
y+=x[i]
e = time.time()
print(y)
print('time cost: %.5f'%(e-s))
b) 使用np.sum()
import numpy as np
import time
np.random.seed(0)
x = np.random.randint(1,100,20000000)
s = time.time()
y = np.sum(x)
e = time.time()
print(y)
print('time cost: %.5f'%(e-s))
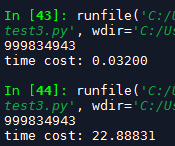
第一个是np.sum结果,花了0.03秒,for花了22.89秒,相差763倍。
更多numpy相关见:https://blog.csdn.net/zhangxinyu11021130/article/details/76736038
https://juejin.im/entry/599aa96c518825242860fb28/
2 两层for循环时改为矩阵,然后使用numpy的矩阵运算
4. 避免函数互相调用
比如有两个文件。
run.py
program.py
其中program.py文件有两个函数test1和test2,当运行run.py文件时都要调用test1和test2,而test2又需要调用test1里的结果,比如
# program.py
def test1():
ans = 0
for i in range(10000):
ans += i**2
return ans
def test2():
ans = test1()
k = ans**2
return k
# run.py
import program
import time
s = time.time()
ans = test3.test1()
k = test3.test2()
e = time.time()
print(ans)
print(k)
print('time cost: %.5f'%(e-s))
运行时间为
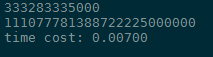
上面test2掉用了test1的结果ans,所以在run里面运行test2时实际上重新再运行了一遍test1,相当于多运行了一遍,所以花了一倍的时间。改进如下:
#program.py
#将test1和test2合并
def test1():
ans = 0
for i in range(10000):
ans += i**2
k = ans**2
return ans,k
#run.py
import program
import time
s = time.time()
ans,k = test3.test1()
e = time.time()
print(ans)
print(k)
print('time cost: %.5f'%(e-s))
运行时间为
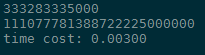
总结:虽然有时候将不同函数分开写可读性很好,但有时会限制速度,在提高速度的前提下,可以适当将多个函数合并,避免互相调用。