pytorch+LeNet+cifar10图像识别+gpu运行
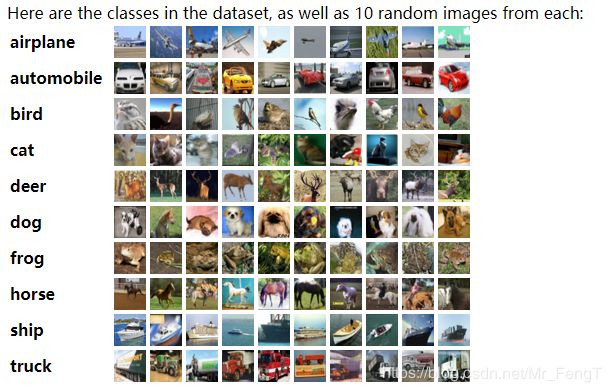
CIFAR-10
先介绍一下cifar10这个数据集。The CIFAR-10 dataset;这个数据集一共有60000张10个不同种类的图片。其中50000张训练图片(分为5个批次),10000张测试图(每个种类1000张图片)。
DownLoad
下载这个数据集,你可以要在这儿下载,点击你想要的版本

或者用这个下载,如果下载过了就将True改为False。就不会重复下载
DOWNLOAD_CIFAR = True
train_data=torchvision.datasets.CIFAR10(root='./cifar10/', train=True, transform=torchvision.transforms.ToTensor(), download=DOWNLOAD_CIFAR,)
train_loader = Data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)这个数据集的内容分布:存档包含文件data_batch_1,data_batch_2,...,data_batch_5以及test_batch。 这些文件中的每一个都是使用cPickle生成的Python“pickled”对象。使用下面的代码打开将返回一个字典。
def load_CIFAR_batch(filename):
with open(filename,'rb')as f:
datadict=p.load(f,encoding='latin1')
x=datadict['data']
y=datadict['labels']
return x,y其中datadict就是字典,内容你可以print(datadict)看一下。内容大概这样
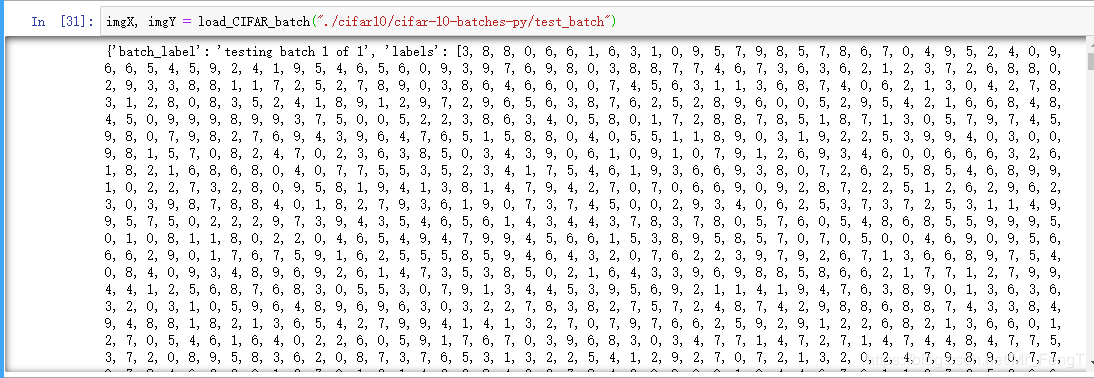
每个批处理文件都包含一个包含以下元素的字典:
数据 - 一个10000x3072 numpy数组的uint8s。 阵列的每一行都存储一个32x32的彩色图像。 前1024个条目包含红色通道值,下一个1024表示绿色,最后1024个表示蓝色。 图像以行主顺序存储,因此数组的前32个条目是图像第一行的红色通道值。
labels - 0-9范围内的10000个数字列表。 索引i处的数字表示阵列数据中第i个图像的标签。数据集包含另一个名为batches.meta的文件。 它也包含一个Python字典对象。 它有以下条目:
label_names - 一个10元素列表,为上述标签数组中的数字标签提供有意义的名称。 例如,label_names [0] ==“airplane”,label_names [1] ==“cars”等。
换句话说,第一个字节是第一个图像的标签,它是0-9范围内的数字。 接下来的3072个字节是图像像素的值。 前1024个字节是红色通道值,下一个1024是绿色,最后1024个是蓝色。 值以行主顺序存储,因此前32个字节是图像第一行的红色通道值。每个文件包含10000个这样的3073字节“行”图像,尽管没有划分行的任何内容。 因此,每个文件应该是30730000字节长。
还有另一个名为batches.meta.txt的文件。 这是一个ASCII文件,它将0-9范围内的数字标签映射到有意义的类名。 它只是10个类名的列表,每行一个。 第i行上的类名对应于数字标签i。
代码:
import torch
import torchvision
import torch.utils.data as Data
import matplotlib.pyplot as plt
import numpy as np
import pickle as p
import matplotlib.image as plimg
from PIL import Image
import torch.nn as nn
EPOCH=1
BATCH_SIZE=50
LR=0.01
DOWNLOAD_MNIST = False
train_data=torchvision.datasets.CIFAR10(root='./cifar10/', train=True, transform=torchvision.transforms.ToTensor(), download=DOWNLOAD_MNIST,)
train_loader = Data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
def load_CIFAR_batch(filename):
with open(filename,'rb')as f:
datadict=p.load(f,encoding='latin1')
x=datadict['data']
y=datadict['labels']
x=x.reshape(10000,3,32,32)
y=np.array(y)
return x,y
def load_CIFAR_Lables(filename):
with open(filename,'rb')as f:
lines=[x for x in f.readlines()]
print(lines)
testx, testy = load_CIFAR_batch("./cifar10/cifar-10-batches-py/test_batch")
img_x=torch.from_numpy(testx)[:2000]
img_y=torch.from_numpy(testy)[:2000]
test_x=img_x.type(torch.FloatTensor).cuda()/255.
test_y=img_y.cuda()
class _LeNet(nn.Module):
def __init__(self):
super(_LeNet,self).__init__()#输入是28*28*1
self.conv1=nn.Sequential(
nn.Conv2d(in_channels=3,out_channels=16,kernel_size=5,stride=1,padding=2),#28*28*16 #32*32*16
nn.MaxPool2d(kernel_size=2),#14*14*16
)
self.conv2=nn.Sequential(
nn.Conv2d(in_channels=16,out_channels=32,kernel_size=5,stride=1,padding=2),#14*14*32 #16*16*32
nn.MaxPool2d(kernel_size=2),#7*7*32 #8*8*32
)
self.linear1=nn.Linear(8*8*32,120)
self.linear2=nn.Linear(120,120)
self.linear3=nn.Linear(120,84)
self.out=nn.Linear(84,10)
def forward(self,x):
x=self.conv1(x)
x=self.conv2(x)
#x=x.view(x.size(0),-1)
x=x.view(x.size(0),-1)
x=self.linear1(x)
x=self.linear2(x)
x=self.linear3(x)
output=self.out(x)
return output
cnn=_LeNet()
cnn.cuda()
optimizer=torch.optim.Adam(cnn.parameters(),lr=LR)
loss_func=nn.CrossEntropyLoss()
i=0
#训练过程,train_loader加载训练数据
for epoch in range(EPOCH):
for step,(data,labels) in enumerate(train_loader):
c_x=data.cuda()
#c_x=x
c_y=labels.cuda()
#c_y=y
output=cnn(c_x)
loss=loss_func(output,c_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
i=i+1
# print(i)
#########训练到此结束##########
if step%50==0:
test_out=cnn(test_x)
pred_y= torch.max(test_out, 1)[1].cuda().data
num=0
for i in range(test_y.size(0)):
if test_y[i].float()==pred_y[i].float():
num=num+1
accuracy = num / test_y.size(0)
print('Epoch: ', epoch, '| train loss: %.4f' % loss.data.cpu().numpy(), '| test accuracy: %.2f' % accuracy)
test_output = cnn(test_x[:10])
pred_y = torch.max(test_output, 1)[1].cuda().data
print(pred_y, 'prediction numbe')
print(test_y[:10], 'real number')最后的训练结果:
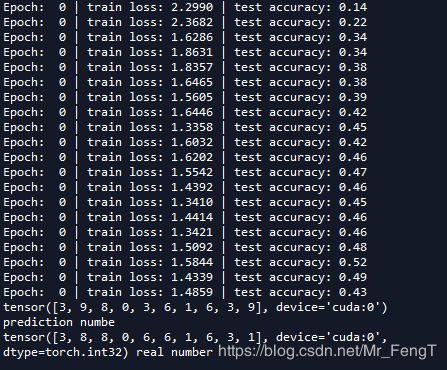
从图中可以看出来,LeNet并不适合对这个cifar-10进行分类。最大的正确率才0.52。 在训练中我又增添了一层全连接层,但是正确率却是没有大的变化,所以一定程度上讲增加层数可能并不会增加训练效果。这需要另外的网络来实现cifar-10的分类。