使用搜狗接口对微信公众号爬虫
搜狗搜索因为有微信公众号搜索的接口,所以通过这个接口就可以实现公众号的爬虫

需要安装几个python的库:selenium,pyquery
还使用到phantomjs.exe,这个需要我们自己去下载,然后放在自己的python工程下即可
在输入框输入想要爬取的公众号的微信号,然后搜公众号,
可出现搜索结果,进入主页可以看到该公众号最近发布的文章,点击标题可查看文章内容
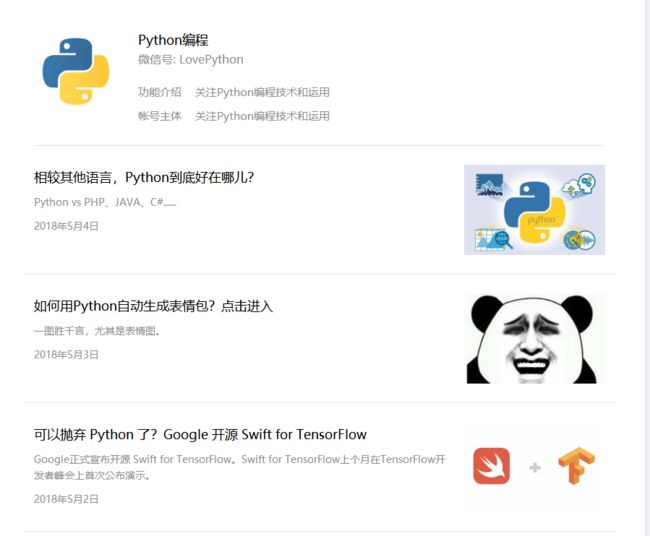
由此思路,能够在网页上查看微信公众号的推送,即可实现公众号爬虫;但搜狗搜索有个不足就是只能查看公众号最近发布的10条推送,再以往的历史记录无法查看。
有了爬虫思路之后就是开始实现的过程,先拿到搜狗搜索的接口
http://weixin.sogou.com/weixin?query=keyword
通过这个接口即能够获取到公众号主页入口,文章列表,文章内容,用python来写爬虫的实现,下面是运行结果,得到文章标题、文章链接、文章简述、发表时间、封面图片链接、文章内容,并且将爬取到的这些信息存入文本文档,公众号的文章爬取就完成了。
话不多说,代码如下:
from pyquery import PyQuery as pq
from selenium import webdriver
import os
import re
import requests
import time
# 使用webdriver 加载公众号主页内容,主要是js渲染的部分
def get_selenium_js_html(url):
browser = webdriver.PhantomJS(executable_path=r'phantomjs.exe')
browser.get(url)
time.sleep(3)
# 执行js得到整个页面内容
html = browser.execute_script("return document.documentElement.outerHTML")
browser.close()
return html
def log(msg):
print('%s: %s' % (time.strftime('%Y-%m-%d %H:%M:%S'), msg))
# 创建公众号命名的文件夹
def create_dir():
if not os.path.exists(keyword):
os.makedirs(keyword)
# 将获取到的文章转换为字典
def switch_articles_to_list(articles):
articles_list = []
i = 1
if articles:
for article in articles.items():
log(u'开始整合(%d/%d)' % (i, len(articles)))
# 处理单个文章
articles_list.append(parse_one_article(article, i))
i += 1
return articles_list
# 解析单篇文章
def parse_one_article(article, i):
article_dict = {}
# 获取标题
title = article('h4[class="weui_media_title"]').text().strip()
log(u'标题是: %s' % title)
# 获取标题对应的地址
url = 'http://mp.weixin.qq.com' + article('h4[class="weui_media_title"]').attr('hrefs')
log(u'地址为: %s' % url)
# 获取概要内容
summary = article('.weui_media_desc').text()
log(u'文章简述: %s' % summary)
# 获取文章发表时间
date = article('.weui_media_extra_info').text().strip()
log(u'发表时间为: %s' % date)
# 获取封面图片
pic = parse_cover_pic(article)
# 获取文章内容(pyQuery.text / html)
#log('content是')
#log(parse_content_by_url(url))
content = parse_content_by_url(url).text()
log('获取到content')
# 存储文章到本地
#content_file_title = keyword + '/' + str(i) + '_' + title + '_' + date + '.html'
#with open(content_file_title, 'w', encoding='utf-8') as f:
# f.write(content)
content_title = keyword + '/' + keyword + '.txt'
with open(content_title, 'a', encoding='utf-8') as f:
print('第', i, '条', file=f)
print('title:', title, file=f)
print('url:', url, file=f)
print('summary:', summary, file=f)
print('date:', date, file=f)
print('pic:', pic, file=f)
print('content:', content, file=f)
print(file=f)
log('写入content')
article_dict = {
'title': title,
'url': url,
'summary': summary,
'date': date,
'pic': pic,
'content': content
}
return article_dict
# 查找封面图片,获取封面图片地址
def parse_cover_pic(article):
pic = article('.weui_media_hd').attr('style')
p = re.compile(r'background-image:url\((.*?)\)')
rs = p.findall(pic)
log(u'封面图片是:%s ' % rs[0] if len(rs) > 0 else '')
return rs[0] if len(rs) > 0 else ''
# 获取文章页面详情
def parse_content_by_url(url):
page_html = get_selenium_js_html(url)
return pq(page_html)('#js_content')
'''程序入口'''
keyword = 'python'
create_dir()
url = 'http://weixin.sogou.com/weixin?query=%s' % keyword
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:51.0) Gecko/20100101 Firefox/51.0'}
try:
log(u'开始调用sougou搜索引擎')
r = requests.get(url, headers=headers)
r.raise_for_status()
print(r.status_code)
print(r.request.url)
print(len(r.text))
#print(r.text)
#print(re.Session().get(url).text)
except:
print('爬取失败')
# 获得公众号主页地址
doc = pq(r.text)
log(u'获取sougou_search_html成功,开始抓取公众号对应的主页wx_url')
home_url = doc('div[class=txt-box]')('p[class=tit]')('a').attr('href')
log(u'获取wx_url成功,%s' % home_url)
# 使用webdriver 加载公众号主页内容,主要是js渲染的部分
log(u'开始调用selenium渲染公众号主页html')
html = get_selenium_js_html(home_url)
#有时候对方会封锁ip,这里做一下判断,检测html中是否包含id=verify_change的标签,有的话,代表被重定向了,提醒过一阵子重试
if pq(html)('#verify_change').text() != '':
log(u'爬虫被目标网站封锁,请稍后再试')
else:
log(u'调用selenium渲染html完成,开始解析公众号文章')
doc = pq(html)
articles = doc('div[class="weui_media_box appmsg"]')
#print(articles)
log(u'抓取到微信文章%d篇' % len(articles))
article_list = switch_articles_to_list(articles)
print(article_list)
log('程序结束')