hadoop中mapreduce的jar包执行方式
1准备:
安装一个hadoop本地上传下载文件的插件hadoop-eclipse-plugin-2.5.1.jar,参考:Eclipse中HDFS上传下载插件使用
2创建一个java工程
在此java工程中导入hadoop的众多jar包,在你下载的hadoop安装包下的share/hadoop下的各个目录都有,功能各不相同,都放入工程中也可以
3.在hdfs上创建一个文件存放目录,并上传一个wc.txt文件
(1)
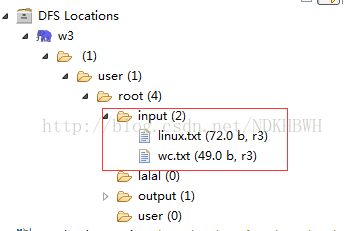
(2).wc.txt中写入随便数据
hadoop hello world
hello hadoop
hbase zookeeper
3.在工程中WordCountMapper继承Mapper
package mapreduce.mapreduce.wc;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.util.StringUtils;
public class WordCountMapper extends Mapper{
// Mapper前两个输入数据的key value 后两个输出数据key value
//Mapper输入为数据行的下角标,和文本 ,输出自定义
//该方法循环调用,从文件中的split中读取每行调用一次,把该行所在的下标为key,该行的内容为value
protected void map(LongWritable key, Text value,
Context context)
throws IOException, InterruptedException {
String[] words = StringUtils.split(value.toString(), ' ');
for(String w :words){
context.write(new Text(w), new IntWritable(1));
}
}
} 4.在工程中创建WordCountReducer继承Reducer
package mapreduce.mapreduce.wc;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordCountReducer extends Reducer{
//洗完牌,循环调用,每一组数据调用一次,每组数据特点,key相同,value可能有多个
protected void reduce(Text arg0, Iterable arg1,
Context arg2)
throws IOException, InterruptedException {
int sum =0;
for(IntWritable i: arg1){
sum=sum+i.get();
}
arg2.write(arg0, new IntWritable(sum));
}
}
5.创建执行类
package mapreduce.mapreduce.wc;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class RunJob {
public static void main(String[] args) {
Configuration config = new Configuration();
try {
FileSystem fs =FileSystem.get(config);
Job job = Job.getInstance(config);
job.setJarByClass(RunJob.class);
job.setJobName("wc");
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//多个文件可以只写文件名 ,单个文件可以写为/user/root/input/wc.txt
FileInputFormat.addInputPath(job, new Path("/user/root/input/"));
Path outpath = new Path("/user/root/output/wc");//输出路径不可以有
if(fs.exists(outpath)){//如果有循环删除
fs.delete(outpath,true);
}
FileOutputFormat.setOutputPath(job, outpath);
boolean waitForCompletion = job.waitForCompletion(true);
if(waitForCompletion){
System.out.println("执行成功");
}
} catch (Exception e) {
System.out.println(e);
e.printStackTrace();
}
}
}
6.打为jar包
传到hadoop服务器上随便的位置,因为hadoop所有配置相同,哪里都可以执行
7.服务器上执行jar包
hadoop jar wc.jar mapreduce.mapreduce.wc.RunJob全限定名加类名
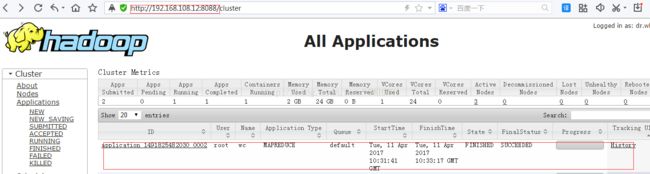
8.验证
(1),
执行界面打印17/04/11 18:20:45 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm2
17/04/11 18:20:46 WARN mapreduce.JobSubmitter: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
17/04/11 18:20:51 INFO input.FileInputFormat: Total input paths to process : 2
17/04/11 18:20:51 INFO mapreduce.JobSubmitter: number of splits:2
17/04/11 18:20:52 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1491825482030_0002
17/04/11 18:20:53 INFO impl.YarnClientImpl: Submitted application application_1491825482030_0002
17/04/11 18:20:53 INFO mapreduce.Job: The url to track the job: http://node2:8088/proxy/application_1491825482030_0002/
17/04/11 18:20:53 INFO mapreduce.Job: Running job: job_1491825482030_0002
17/04/11 18:21:22 INFO mapreduce.Job: Job job_1491825482030_0002 running in uber mode : false
17/04/11 18:21:22 INFO mapreduce.Job: map 0% reduce 0%
17/04/11 18:22:09 INFO mapreduce.Job: map 100% reduce 0%
17/04/11 18:22:29 INFO mapreduce.Job: map 100% reduce 100%
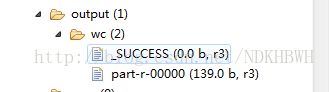
(2),
(3)统计文件生成
hadoop 2
hbase 1
hello 2
world 1
zookeeper 1
9至此执行hadoop的jar包方式介绍完毕