机器学习理论篇之SVM(python实现)

参考:
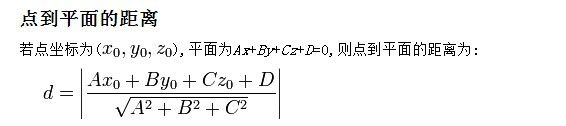
那如何寻找超平面,确定w和b呢?答案是寻找两条边界端或极端划分直线中间的最大间隔(之所以要寻最大间隔是为了能更好的划分不同类的点。
Hard-margin:(无噪声点情况,硬分隔)
如果训练数集是线性可分的,我们可以选择两个平行的线,来分开两个数据集,因此我们要确保,这两条平行线的距离尽可能的大,两条平行线组成的区域就是叫做Margin
我们可以定义分类函数:![]()
显然,如果 f(x)=0 ,那么 x 是位于超平面上的点。我们不妨要求对于所有满足 f(x)<0 的点,其对应的 y 等于 -1 ,而 f(x)>0 则对应 y=1 的数据点。
我们在进行分类的时候,将数据点 x代入 f(x) 中,如果得到的结果小于 0 ,则赋予其类别 -1 ,如果大于 0 则赋予类别 1
在超平面w*x+b=0确定的情况下,|w*x+b|能够相对的表示点x到距离超平面的远近,而w*x+b的符号与类标记y的符号是否一致表示分类是否正确,所以,可以用量y*(w*x+b)的正负性来判定或表示分类的正确性和确信度。即y*(w*x+b)为正数时,分类正确,值为点x到超平面的函数间隔,否则错误。
我们定义函数间隔functional margin 为:(是指点x到超平面的函数间隔)
![]()
接着,我们定义超平面(w,b)关于训练数据集T的函数间隔为:超平面(w,b)关于T中所有样本点(xi,yi)的函数间隔最小值,其中,x是特征,y是结果标签,i表示第i个样本,有:
然与此同时,问题就出来了。
= min
上述定义的函数间隔虽然可以表示分类预测的正确性和确信度,但在选择分类超平面时,只有函数间隔还远远不够,因为如果成比例的改变w和b,如将他们改变为2w和2b,虽然此时超平面没有改变,但函数间隔的值f(x)却变成了原来的4倍。
其实,我们可以对法向量w加些约束条件,使其表面上看起来规范化,如此,我们很快又将引出真正定义点到超平面的距离--几何间隔geometrical margin的概念(很快你将看到,几何间隔就是函数间隔除以个||w||,即yf(x) / ||w||)。

不过这里的![]() 是带符号的,我们需要的只是它的绝对值,因此类似地,也乘上对应的类别 y即可,因此实际上我们定义 几何间隔geometrical margin 为(注:别忘了,上面
是带符号的,我们需要的只是它的绝对值,因此类似地,也乘上对应的类别 y即可,因此实际上我们定义 几何间隔geometrical margin 为(注:别忘了,上面![]() 的定义,
的定义,![]() =y(wTx+b)=yf(x) ):
=y(wTx+b)=yf(x) ):

注意对两![]() 的区分,等式右边的为几何间隔,等式左边的为函数间隔
的区分,等式右边的为几何间隔,等式左边的为函数间隔
我们已经很明显的看出,函数间隔functional margin 和 几何间隔geometrical margin 相差一个
那么这两个margin用哪一个呢?
1、functional margin 明显是不太适合用来最大化的一个量,因为在 hyper plane超平面 固定以后,我们可以等比例地缩放 w 的长度和 b 的值,这样可以使得![]() 的值任意大,亦即 functional margin
的值任意大,亦即 functional margin![]() 可以在 hyper plane 保持不变的情况下被取得任意大,
可以在 hyper plane 保持不变的情况下被取得任意大,
这样一来,我们的 maximum margin classifier 的目标函数可以定义为:
当然,还需要满足一些条件,根据 margin 的定义,我们有
这里的
为了方便推导和优化的目的,我们可以令![]() =1(函数间隔)
=1(函数间隔)
(因为函数间隔的扩大和缩小不会影响到超平面的位置,所以这里可以随意定值,为了方便我们訂了1),
所以几何间隔![]() = 1 / ||w|
= 1 / ||w|
所以上述的目标函数可以转化为(其中,s.t.,即subject to的意思,它导出的是约束条件):

通过求解这个问题,我们就可以找到一个 margin 最大的 classifier
因此总结下来,就是我们先要定义一个数据集到超平面的最小函数间隔,即支持向量点,然后在此基础上求出超平面到支持向量的最大距离间隔。
(一般为方便运算,直接令最小函数间隔为1。因为函数间隔的放大对超平面没有影响)
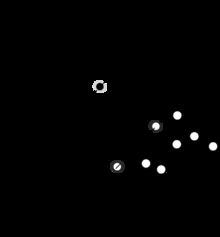
注意:上面图片中的-b和b是一样的,就是b 取值符号不同而已,后面都是-b了,因为图的原因
距离超平面最近的这几个颜色加深的训练样本点,就是“支持向量”
很显然,由于这些 supporting vector 刚好在边界上,所以它们满足![]() ,而对于所有不是支持向量的点,也就是在“阵地后方”的点,则显然有
,而对于所有不是支持向量的点,也就是在“阵地后方”的点,则显然有![]()
Soft-margin(有噪声点的情况,软分隔)
我们引入了损失函数:
因为如果预测正确的情况下![]() 肯定大于1,所以,当预测正确的情况下,损失函数是0
肯定大于1,所以,当预测正确的情况下,损失函数是0
当预测错误的情况下,损失函数就是函数间隔。
我们想要最小化:
参数表示对噪声的容忍度,如果 λ {\displaystyle \lambda } 过小,那么和硬分隔没有区别。。
最简单的线性可分离数据的实现,这里主要是要了解实现SVM的具体思路
# -*- coding: utf-8 -*-
import numpy as np
from matplotlib import pyplot
import math
import sys
class SVM(object):
def __init__(self, visual=True):
self.visual = visual
self.colors = {1: 'r', -1: 'b'}
if self.visual:
self.fig = pyplot.figure()
self.ax = self.fig.add_subplot(1, 1, 1)
def train(self, data):
self.data = data
opt_dict = {}
transforms = [[1, 1],
[-1, 1],
[-1, -1],
[1, -1]]
# 找到数据集中最大值和最小值
"""
all_data = []
for y in self.data:
for features in self.data[y]:
for feature in features:
all_data.append(feature)
print(all_data)
self.max_feature_value = max(all_data)
self.min_feature_value = min(all_data)
print(self.max_feature_value, self.min_feature_value)
"""
self.max_feature_value = float('-inf') # -sys.maxint - 1 Python3替换为了sys.maxsize
self.min_feature_value = float('inf') # sys.maxint
for y in self.data:
for features in self.data[y]:#features 就是一个坐标点(x,y)
for feature in features:#x和y分别取出
if feature > self.max_feature_value:
self.max_feature_value = feature
if feature < self.min_feature_value:
self.min_feature_value = feature
print(self.max_feature_value, self.min_feature_value)
# 和梯度下降一样,定义每一步的大小;开始快,然后慢,越慢越耗时
step_sizes = [self.max_feature_value * 0.1, self.max_feature_value * 0.01, self.max_feature_value * 0.001]
b_range_multiple = 5
b_multiple = 5
lastest_optimum = self.max_feature_value * 10
for step in step_sizes:#改变w下降的速度
w = np.array([lastest_optimum, lastest_optimum])
optimized = False
while not optimized:
# arange用法
# np.arange(1,3,0.3)
#array([ 1. , 1.3, 1.6, 1.9, 2.2, 2.5, 2.8])
#改变超平面和原点的距离,b表示距离,w表示方向
for b in np.arange(self.max_feature_value * b_range_multiple * -1,
self.max_feature_value * b_range_multiple, step * b_multiple):
#四个方向都要尝试
for transformation in transforms:
w_t = w * transformation# 改变超平面方向
found_option = True
#for循环是判断当前w方向的预测情况
for i in self.data: # i 为data的分类,这里为1 和-1
for x in self.data[i]:
y = i
#大于等于1才表示预测正确,这个表示只要有一次识别错误就不保存值
if not y * (np.dot(w_t, x) + b) >= 1:
found_option = False
# print(x,':',y*(np.dot(w_t, x)+b)) 逐渐收敛
if found_option:
"""
np.linalg.norm(x, ord=None, axis=None, keepdims=False)
这里我们只对常用设置进行说明,x表示要度量的向量,ord表示范数的种类.
ord=2(默认) 二范数:ℓ2 元素平方和,然后开根号
ord=1 一范数:ℓ1 元素绝对值之和,|x1|+|x2|+…+|xn|
ord=np.inf 无穷范数:ℓ∞ max(|xi|)
"""
opt_dict[np.linalg.norm(w_t)] = [w_t, b]
if w[0] < 0:#这里的w没有符号,全是正值,w[0]<0表示当前step下的最优解肯定已经训练出来了,可以跳出循环了
optimized = True
else:
w = w - step
#找到当前最优的w值,要想1/||w||最大,找到||w||最小值即可
norms = sorted([n for n in opt_dict])
opt_choice = opt_dict[norms[0]]
self.w = opt_choice[0]
self.b = opt_choice[1]
print(self.w, self.b)
#当前下降速度训练完毕后,对lastest_optimum 进行修改,保存当前w下降后的值
#opt_choice[0]存储了两个相同的值
#加上step×2是防止step过大,已经把最优解训练过,
lastest_optimum = opt_choice[0][0] + step * 2
def predict(self, features):
#np.sign(a),返回数组中各元素的正负符号,用1和-1表示
classification = np.sign(np.dot(features, self.w) + self.b)
if classification != 0 and self.visual:
self.ax.scatter(features[0], features[1], s=300, marker='*', c=self.colors[classification])
return classification
def visualize(self):
for i in self.data:
for x in self.data[i]:
self.ax.scatter(x[0], x[1], s=50, c=self.colors[i])
#通过超平面算出另外的x
def hyperplane(x, w, b, v):
return (-w[0] * x - b + v) / w[1]
data_range = (self.min_feature_value * 0.9, self.max_feature_value * 1.1)
hyp_x_min = data_range[0]
hyp_x_man = data_range[1]
psv1 = hyperplane(hyp_x_min, self.w, self.b, 1)
psv2 = hyperplane(hyp_x_man, self.w, self.b, 1)
self.ax.plot([hyp_x_min, hyp_x_man], [psv1, psv2], c=self.colors[1])
nsv1 = hyperplane(hyp_x_min, self.w, self.b, -1)
nsv2 = hyperplane(hyp_x_man, self.w, self.b, -1)
self.ax.plot([hyp_x_min, hyp_x_man], [nsv1, nsv2], c=self.colors[-1])
db1 = hyperplane(hyp_x_min, self.w, self.b, 0)
db2 = hyperplane(hyp_x_man, self.w, self.b, 0)
self.ax.plot([hyp_x_min, hyp_x_man], [db1, db2], 'y--')
pyplot.show()
if __name__ == '__main__':
data_set = {-1: np.array([[1, 7],
[2, 8],
[3, 8]]),
1: np.array([[5, 1],
[6, -1],
[7, 3]])}
print(data_set)
svm = SVM()
svm.train(data_set)
for predict_feature in [[0, 10], [1, 3], [4, 3], [5.5, 7.5], [8, 3]]:
print(svm.predict(predict_feature))
svm.visualize()
理论部分参考:http://eric-gcm.iteye.com/blog/1981771
代码部分参考:http://blog.topspeedsnail.com/archives/10326