数据结构之链表
上一篇文章里我介绍了顺序表的实现,这一篇我将介绍链表的实现。
链表
概念:
链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的引用链接次序实现的。
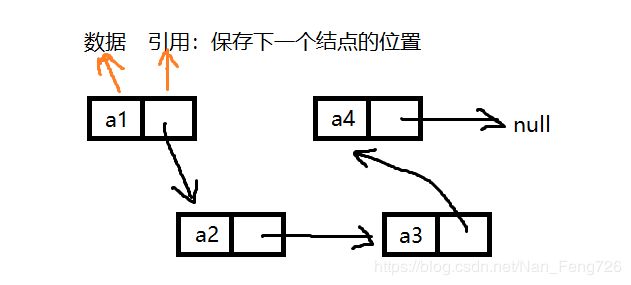
实际中链表的结构非常多,比如说:
1、单向、双向
2、带头、不带头
3、循环、非循环
以上各种组合起来又是很多种链表的结构,但是最常用的还是以下三种:
1、无头单向非循环链表
2、带头循环单链表
3、不带头双向循环链表
实现:
与顺序表相同,主要实现头插/头删,尾插/尾删等功能。我们首先定义一个内部类,创建一个结点,value保存的是有效数据,next是下一个结点的引用,再定义一个head结点,用来保存链表中第一个结点的引用,如果当前链表中一个结点都没有,head==null。
public class Node {
public int value;
public Node next;
Node(int value) {
this.value = value;
this.next = null;
}
}
private Node head;
MyLinkedList() {
this.head = null;
}
链表的头插比较简单,将要插入的结点的next引用指向当前头结点,插入后再更新当前头结点的位置即可。
//时间复杂度O(1)
public void pushFront(int item) {
Node node = new Node(item);
node.next = this.head;
this.head = node;
}
链表的头删更简单,直接将头结点指向当前头结点的下一个结点即可。
//时间复杂度O(1)
public void popFront() {
if (this.head == null) {
throw new Error();
}
this.head = this.head.next;
}
链表的尾插需要考虑两种情况,链表为空和不为空,链表为空的话,直接将头结点的指向改为要插入的这个结点就行。链表不为空的话,就需要遍历整个链表,找最后一个结点,将最后一个结点的next引用指向要插入的结点node。需要注意的是,链表的遍历只能从前往后遍历。
可是在链表中,怎么确定它就是最后一个结点呢,很简单,只要这个结点的next引用指向空,那么它就是最后一个结点。
//时间复杂度O(n)
private Node getLast() {
Node cur = this.head;
while (cur.next != null) {
cur = cur.next;
}
return cur;
}
//时间复杂度O(n)
public void pushBack(int item) {
Node node = new Node(item);
if (this.head == null) {
this.head = node;
} else {
Node last = getLast();
last.next = node;
}
}
链表的尾删,按照前面的思路很容易可以想到,找出倒数第二个结点,将这个结点的next引用指向空就行。但是会存在一些问题,如果当前链表只有一个结点的话,自然就找不到倒数第二个结点,解决方法很简单,直接将头结点的next引用指向空就行。
//时间复杂度O(n)
private Node getPenult() {
Node cur = this.head;
while (cur.next.next != null) {
cur = cur.next;
}
return cur;
}
//时间复杂度O(n)
public void popBack() {
if (this.head == null) {
throw new Error();
}
if (this.head.next == null) {
this.head = null;
} else {
Node penult = getPenult();
penult.next = null;
}
}
链表的在任意位置插入,举例子来说会比较形象,看下面这幅图:
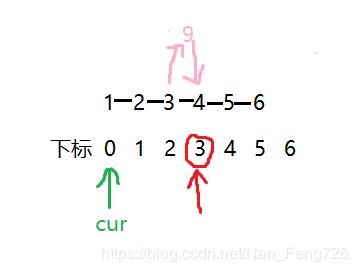
红色标记的是指定要插入的位置,要在数据4这个位置插入一个数据,我们需要找到它的前一个结点3,更改它的next指向,而如果要找这个数据3,需要将cur引用向后挪动2步,也就是index-1步。
如果指定位置为0呢,这就相当于头插,直接更改头结点指向为要插入的结点就行,最后记得更新头结点的指向。
但是在插入过程中需要考虑一点特殊情况,如果链表只有6个数据,要求你在下标为6的位置插入一个数据呢,很明显这个下标并不存在,这点需要特殊处理一下。看代码:
//任意位置插入
boolean addIndex(int index, int v) {
Node node = new Node(v);
if (index == 0) {
node.next = this.head;
this.head = node;
} else {
Node cur = this.head;
for (int i = 0; cur != null && i < index - 1; i++) {
cur = cur.next;
}
if (cur == null) {
return false;
}
node.next = cur.next;
cur.next = node;
}
return true;
}
查看关键字key是否在单链表中,这个比较简单,遍历链表,直接比较cur引用的值与给定值就行,代码大家也都看得懂,就不多说了:
//查找关键字key是否在单链表当中
public boolean contains(int v) {
for (Node c = this.head; c != null; c = c.next) {
if (c.value == v) {
return true;
}
}
return false;
}
删除链表中第一次出现关键字key的结点,关于这个问题,我们可以定义一个prev引用指向当前头结点,如果prev引用的下一个结点的值和给定key值相等,那么就让prev引用指向下下一个结点,这样很容易就可以删除。然而如果我们要删除的结点在第一个呢,也很简单,直接让头结点指向下一个结点就行,看代码:
//删除第一次出现关键字为key的节点
public void remove(int v) {
if (this.head == null) {
} else if (this.head.value == v) {
this.head = this.head.next;
} else {
Node prev = this.head;
while (prev.next != null) {
if (prev.next.value == v) {
prev.next = prev.next.next;
break;
}
}
}
}
删除链表中所有值为key的结点,这个问题的处理方法是定义一个结果链表,再结合尾插的方法来实现。
定义一个last引用,指向结果链表的最后一个节点,cur引用指向给定链表的第一个节点。遍历链表,如果节点的值与给定值val不相等,就把它尾插到结果链表。尾插的时候要考虑到两种情况,结果链表为空和不为空,需要注意的是,插入一个新节点后要记得更新结果链表的最后一个节点,即last引用的指向,看代码:
//删除所有值为key的节点
public void removeAll(int v){
Node result = null;
Node last = null;
Node cur = this.head;
while (cur!=null){
Node next = cur.next;
if (cur.value!=v){
//尾插到result链表
cur.next=null;
if (result==null){
result=cur;
}else {
last.next=cur;
}
last=cur;
}
cur=next;
}
}
求链表的长度和打印链表都比较简单,遍历链表就行,这里就不多做解释,直接看代码:
//求链表长度
public int getLength(){
Node cur = this.head;
int len = 0;
while (cur!=null){
len++;
cur=cur.next;
}
return len;
}
//依次打印链表中每一个结点
public void display() {
//如何通过循环遍历链表的每一个结点
Node cur = this.head;
while (cur != null) {
System.out.format("%d-->", cur.value);
cur = cur.next;
}
System.out.print("null");
}
完整代码在我的Github上:
https://github.com/Nanfeng11/DataStructure/tree/master/linkList
双向链表
概念:
双向链表,顾名思义,既有一个指向下一个节点的引用,也有指向前一个节点的引用,就像下图中这样:

实现:
定义一个节点类,里面包含了一个节点值value,指向下一个节点的引用next,以及指向前一个节点的引用prev。
public class Node{
int value;
Node next;
Node prev;
}
//双向+保存最后一个结点
Node head;
Node last;
头插:让要插入的节点的next引用指向当前头节点,插入成功后更改头节点的指向,如果当前最后一个节点指向为空的话,也就是说当前链表为空,让它指向新插入的这个节点。
public void addFirst(Node node){
node.next=this.head;
this.head=node;
if (this.last==null){
this.last=node;
}
}
头删:更改头节点的指向就可以实现头删,即让头节点指向头节点的下一个节点。如果头节点指向空,也就是链表为空的话,让last引用也指向空。
public void removeFirst(){
this.head=this.head.next;
if (this.head==null){
this.last=null;
}
}
尾插:如果当前双向链表为空的话,让头节点和尾节点同时指向新插入的节点就行。如果双向链表不为空,要在尾部插入一个新节点,首先需要让要插入节点的prev引用指向当前链表的最后一个节点last,然后让之前链表的最后一个节点的next引用指向新插入的节点,最后更新当前链表的最后一个节点。
public void addLast(Node node){
node.next=null;
if (this.head==null){
this.head=this.last=node;
}else {
node.prev=this.last;
this.last.next=node;
this.last=node;
}
}
尾删:双向链表的尾删,就是找到最后一个节点的前一个节点,让这个节点的next引用指向空就行,而如果双向链表中只有一个节点,那么直接让当前链表头节点和尾节点同时指向空就可以了,看代码:
public void removeLast(){
if (this.head.next==null){
this.head=this.last=null;
}else {
this.last.prev.next=null;
}
}
最后,我再总结一下链表和顺序表的区别:
顺序表VS链表
顺序表:
原理:
顺序表就相当于一个数组,将数据元素放到一块连续的内存中。
优点:
1)空间利用率高。因为是连续存放,所以如果查找一个元素,命中率也比较高。
2)存取速度快,通过下标来直接存储。
缺点:
1)插入/删除比较麻烦。插入或者删除的时候,整个表需要遍历挪动元素来实现。
2)空间有限制。因为数组长度是固定的,当需要存取的元素个数多于顺序表的个数时,就会出现溢出问题,而当元素个数远远小于当初分配的空间时,又会造成空间的浪费。
时间复杂度:
查找:O(1),插入/删除:O(n)
链表:
原理:
链表存储是在程序运行过程中动态分配空间,相邻元素可以随意存放。所占内存空间分为两部分,一部分存储结点值,另一部分存放下一个节点的地址。
优点:
1)插入和删除速度快,只需要改变当前节点存储的下一个结点的位置就行。
2)没有空间限制,存储元素的个数无上限,基本只与内存空间大小有关。
缺点:
1)存取某个元素速度慢。
2)占用额外的空间来存储下一个结点的位置,不连续存放,浪费空间,空间碎片多。
3)查找速度慢。因为查找某个元素的时候,需要遍历链表,一个一个去查找。
时间复杂度:
查找:O(n),插入/删除:O(1)