Elasticsearch6.5+Logstash6.5安装和配置
1、Elasticsearch6.5
1.1 ElasticSearch 简介
(1)基于 Apache Lucene 构建的 开源搜索引擎,提供一个分布式多用户的全文搜索引擎;
(2)提供了简单易用的 Java Restful API,是当前流行的企业级搜索引擎;
(3)轻松的横向扩展,可支持 PB 级的结构化或非结构化数据处理;
(4)可以准确实时地快速存储、搜索、分析海量的数据。在云计算中可以实时搜索。
1.2 ElasticSearch 名称说明
索引:含有相同属性的文档集合;
类型:索引可以定义一个或多个类型,文档必须属于一个类型;
文档:文档是可以被索引的基本数据单位;
分片:每个索引都有多个分片,每个分片是一个 Lucene 索引;
备份:拷贝一份分片就完成了分片的备份;
关系数据库和 ElasticSearch 定义对比:
关系数据库 ==> 数据库(database) ==> 表(table) ==> 行 ==> 列(Columns)
Elasticsearch ==> 索引(Index) ==> 类型(type) ==> 文档(Document) ==> 字段(Fields)
字段类型:这里强调两个地方:(1) ES6.5 开始不支持 string 类型,由 text 和 keyword 类型替代;text类型:当一个字段需要被全文搜索时,如项目名称、描述等等,应该使用 text 类型。当字段被设置为 text 类型之后,其内容会被分词器(如 analysis-ik)分成一个个词项。text 类型的字段不用于排序,很少用于聚合。一般需要模糊查询某个字段内容时应该将该字段设置 为text 类型。keyword 类型:keyword 类型适用于索引结构化的字段,且 keyword 类型的字段只能通过精确值搜索到。其他类型参见后面的参考博客链接。
1.3 ElasticSearch6.5安装和配置
为了方便和熟悉起 mac 系统,本次项目主要安装在 macbook pro 上。
首先需要安装 JDK8,注意一定要是 jdk8 及以上版本。mac 上安装 jdk8 也很方便,但是要记住 jdk 解压缩目录和环境的配置。
ES 选择的是 6.5 版本,直接在官网下载 elasticsearch-6.5.0.tar.gz 解压即可;
启动 ES,查看是否安装成功。进入解压完的 ES 目录下,输入:sh ./bin/elasticsearch 即可启动程序。启动后,看到的是starting...,最后是 started 即代表启动成功。
一般都是后台启动(为了不至于开那么多的 terminal 标签页),进入 ES 目录下输入:./bin/elasticsearch -d
有时候需要重启 es,但是又不知道它是否已经在启动了时,可以查看所有的进程:

杀死某个进程:kill 732
配置 ES:进入 elasticsearch 安装目录下的 config 目录下 vim elasticsearch.yml ,在此配置文件末尾追加如下配置信息并保存:
http.cors.enabled: true #如果启用了 HTTP 端口,那么此属性会指定是否允许跨源 REST 请求。
http.cors.allow-origin: "*"#若http.cors.enabled的值为true,那么该属性会指定允许REST请求来自何处
cluster.name: wali #集群名称
node.name: master #节点名称
node.master: true #是否是父节点
network.host: 0.0.0.0 #设置为0.0.0.0表示允许其他电脑通过 ip 即可访问安装 ES 的可视化操作插件 elasticsearch-head-master:
1)首先需要安装 Node6.X。mac 系统安装 node 很简单,下载完之后双击一步步安装即可。然后输入 node -v 即可查看安装版本;
2)下载elasticsearch-head包,在Github【elasticsearch-head】上面,直接选择下载的DownLoad zip到本地!
3)对 elasticsearch-head 进行解压;
4)在 /Users/mac/Documents/2018/imooc/elasticsearch-head-master 目录下使用 npm install
5)在 /Users/mac/Documents/2018/imooc/elasticsearch-head-master 目录下 npm run start
注意:第一次需要第 4)步,其他都不需要;
6)验证服务,在浏览器中输入 http://localhost:9100 ,出现如下图即代表启动成功
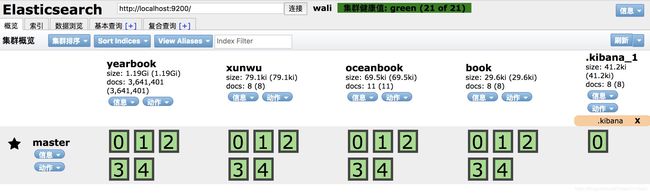
其中集群健康值有:red(差):集群 健康状况很差,虽然可以查询,但是已经出现了丢失数据的现象 ;yellow(中):集群健康状况不是很好,但是集群可以正常使用 ;green(优):集群健康状况良好,集群正常使用。
注:这里面是我已经建立了好几个索引,所以有很多个,并且安装了 kibana,所以有 .kibana
至此,Elasticsearch6.5 启动和安装成功!
2、Logstash6.5安装和配置
1.1 Logstash6.5简介
Logstash 主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。一般工作方式为 c/s 架构,client 端安装在需要收集日志的主机上,server 端负责将收到的各节点日志进行过滤、修改等操作在一并发往 elasticsearch 上去。
可以理解为Logstash主要是往 elasticsearch 里面导入数据。
1.2 Logstash安装配置
注意 Logstash 的版本要和 Elasticsearch 版本保持一致!
直接在官网下载 Logstash6.5(https://www.elastic.co/cn/downloads)
解压下载下来的压缩文件:
tar -zxvf logstash-6.5.0.tar.gz启动 Logstash6.5:进入 logstash 目录下,输入:
bin/logstash -e "input{stdin{}}output{stdout{}}"terminal 输出 hello world 即表示启动成功
1.3 把 csv 文件导入到 elasticsearch 里面
input {
file {
path => ["/Users/mac/Documents/2018/imooc/data/test.csv"]
start_position => "beginning"
}
}
filter{
csv {
separator => ","
columns => ["id","citytr","classes","code","countytr","distinct","from","full_name","MD5","index_name","origin","provincetr","statistic_num","tag","unit","year"]
}
}
output {
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "oceanbook"
}
}
其中:
input
input组件负责读取数据,使用以下插件读取不同的数据类型。
file插件读取本地文本文件,
stdin插件读取标准输入数据,
tcp插件读取网络数据,
log4j插件读取log4j发送过来的数据等等。
path:csv文件路径
start_position:可以设置为beginning或者end,beginning表示从头开始读取文件,end表示读取最新的,这个也要和ignore_older一起使用。
filter
filter插件负责过滤解析input读取的数据
读取csv文件:
separator:拆分符
columns:csv文件中的字段,注意:要和 csv文件中字段顺序一致
mutate:字段类型转换,具体可转换的数据类型,根据es版本而定,可查看官网:https://www.elastic.co/guide/en/logstash/5.5/plugins-filters-mutate.html
output
hosts:主机ip
index:设置es中的索引名称
document_type:索引下的type名称
对于csv文件需要注意一下几点:
1、第一行不需要存储字段名称,直接就是字段值信息
2、最后一行要换行
参考博客:
https://blog.csdn.net/u010648555/article/details/81841188
https://blog.csdn.net/chengyuqiang/article/details/79048800
https://blog.csdn.net/resilient/article/details/79296083?utm_source=blogxgwz1
https://blog.csdn.net/qq_34624315/article/details/83009482