机器学习实战-使用朴素贝叶斯分类器来做垃圾邮件分类
coding:
from numpy import *
import re
def loadDataSet():
postingList = [['my', ' dog', 'has', 'flea', 'problem', 'help', 'please'],
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage', 'to', 'stop', 'him'],
['quit', 'buying', 'worthleaa', 'dog', 'food', 'stupid']]
classsVec = [0, 1, 0, 1]
return postingList, classsVec
def createVocabList(dataSet):
vocabSet = set([])
for document in dataSet:
vocabSet = vocabSet | set(document)
return list(vocabSet)
def setOfWords2Vec(vocabList, inputSet):
returnVec = [0]*len(vocabList)
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] = 1
else:
print("the word: %s is not in my Vocabulary" %word)
return returnVec
def trainNBO(trainMartix, trainCategory):
numTrainDocs = len(trainMartix)
numWords = len(trainMartix[0])
pAbusive = sum(trainCategory)/float(numTrainDocs)
p0Num = ones(numWords)
p1Num = ones(numWords)
p0Demo = 2.0
p1Demo = 2.0
for i in range(numTrainDocs):
if trainCategory[i-1] == 1:
p1Num += trainMartix[i]
p1Demo += sum(trainMartix[i])
else:
p0Num += trainMartix[i]
p0Demo += sum(trainMartix[i])
p1Vect = log(p1Num/p1Demo)
p0Vect = log(p0Num/p0Demo)
return p0Vect, p1Vect, pAbusive
def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1):
p1 = sum(vec2Classify*p1Vec) + log(pClass1)
p0 = sum(vec2Classify*p0Vec) + log(1.0 - pClass1)
if p1 > p0:
return 1
else:
return 0
def testingNB():
listOPosts, listClasses = loadDataSet()
myVocabList = createVocabList(listOPosts)
trainMat = []
for postinDoc in listOPosts:
trainMat.append(setOfWords2Vec(myVocabList, postinDoc))
p0V, p1V, pAb = trainNBO(array(trainMat), array(listClasses))
testEntry = {'love', 'my', 'dalmation'}
thisDoc = array(setOfWords2Vec(myVocabList, testEntry))
print(testEntry,'classified as:', classifyNB(thisDoc, p0V, p1V, pAb))
testEntry = {'stupid', 'garbage'}
thisDoc = array(setOfWords2Vec(myVocabList, testEntry))
print(testEntry,'classified as:', classifyNB(thisDoc, p0V, p1V, pAb))
def textParse(bigSreing):
listOfTokens = re.split(r'\w*', bigSreing)
return (tok.lower() for tok in listOfTokens if len(tok) > 2)
def spamTest():
docList = []
classList = []
fullText = []
for i in range(1, 26):
wordList = textParse(open('email/spam/%d.txt' % i).read())
docList.append(wordList)
fullText.extend(wordList)
classList.append(1)
wordList = textParse(open('email/ham/%d.txt' % i).read())
docList.append(wordList)
fullText.extend(wordList)
classList.append(0)
vocabList = createVocabList(docList)
trainingSet = list(range(50))
testSet = []
for i in range(20):
randIndex = int(random.uniform(0, len(trainingSet)))
testSet.append(trainingSet[randIndex])
del(trainingSet[randIndex])
trainMat = []
trainClasses = []
for docIndex in trainingSet:
trainMat.append(setOfWords2Vec(vocabList, docList[docIndex]))
trainClasses.append(classList[docIndex])
p0V, p1V, pSpam = trainNBO(array(trainMat), array(trainClasses))
errorCount = 0
for docIndex in testSet:
wordVector = setOfWords2Vec(vocabList, docList[docIndex])
if classifyNB(array(wordVector), p0V, p1V, pSpam) != classList[docIndex]:
errorCount += 1
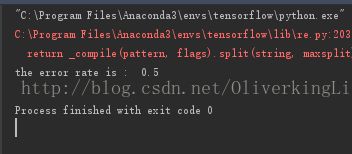
print("the error rate is : ", float(errorCount)/len(testSet))
spamTest()