mtcnn论文阅读及pytorch实现
论文信息
论文名称:Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks[2016-IEEE-Signal Processing Letters]
作者列表:Kaipeng Zhang, Zhanpeng Zhang, Zhifeng Li, Yu Qiao.
Github : mtcnn-pytorch
论文解读
- Novelty & Contribution
- 提出了实时的人脸detection和alignment的联级卷积网络框架;
- 提出了Online-Hard-sample-Mining策略来提高检测效果[对每个mini-batch样本的loss进行降序排列,取前70%的样本作为hard-samples,然后只采用这些难样本对应的gradient对网络进行训练];
- 网络设计
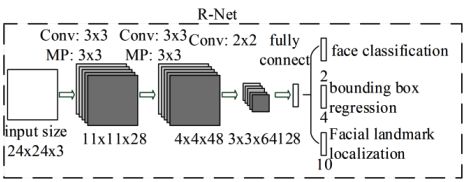
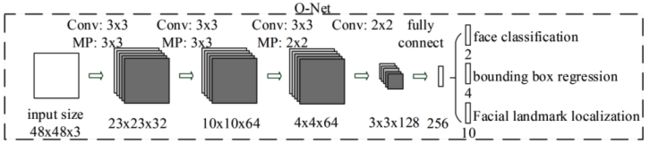
mtcnn由RNet、RNet、ONet 3个简单的子网络构成:
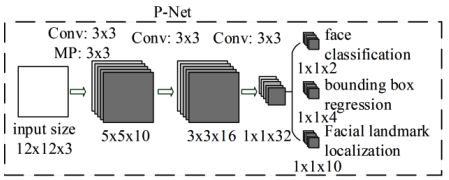
PNet:对由原图生成的金字塔图片生成大量潜在的proposals,然后利用NMS去除IoU过高的proposal;
RNet:拒掉PNet产生的大量的错误的proposal,执行bbox regression,继续提升proposal的质量;
ONet:作用和RNet类似,不过给为精细,输出bbox_score, bbox, landmark;
- 损失函数
分类损失: ![]() ;其中,
;其中,![]() .
.
回归损失: ![]() ;其中,
;其中,![]() .
.
lmk损失:![]() ,其中,
,其中,![]() .
.
训练网络采用的损失函数:
![]()
其中,alpha_j表示不同任务的loss的权重,对PNet、RNet而言,三个任务loss的权值依次为:1:0.5:0.5;对ONet而言,三个任务loss的权重依次为:1:0.5:1. beta表示训练样本的标记,若它取0,表示该样本属于负类样本,不参与bbox回归、landmark点检测的损失计算。
工程实现
- 原始数据集信息
Wide face : 12880 | bbox标注格式 [x1, y1, x2, y2]
CUHKMM : [ lfw_5590, net_7876 ], 共计13466;
划分结果 : num_train = 1w, num_validate = 3466, split_ratio = 3:1
标注风格 : bbox [x1, x2, y1, y2]; lmk_pts [x1, y1, x2, y2, …, x5, y5]
- 实验数据集划分
文件预处理, 将CUHKMM给定的划分文件合并为一个文件,然后按照统一的比例【3:1】来产生训练集和验证集。
根据bbox与gt_boxes的IoU值来划分positive、part、negative face,具体划分依据:
positive : IoU >= 0.65; part :0.4<=IoU<0.65; negative : IoU<0.3.
----------------------------------------------------------------------------------------------------------------------
* P-net : negative:1011486; positive:472633; part:1162745; landmark :67840;
* assemble.py文件中的base_num设置为25W
* train_anno : 922488; eval_anno : 395352
* 分类样本:bbox样本:landmark样本 = (75+25):(25+25): 6.8 = 14 : 7 : 1
* factors权重设置 : 1 : 0.5 : 0.5
----------------------------------------------------------------------------------------------------------------------
* R-net: negative: 772430; positive: 132566; part: 472144; landmark :68126;
* assemble.py文件中的base_num设置为25W
* train_anno : 922688; eval_anno : 395438;
* 分类样本:bbox样本:landmark样本 = (75+25):(25+25): 6.8 = 14 : 7 : 1
* factors权重设置 : 1 : 0.5 : 0.5
----------------------------------------------------------------------------------------------------------------------
* O-net: negative: 1118053; positive: 209349; part:204135; landmark :68171;
* assemble.py文件中的base_num设置为25W
* train_anno : 922719; eval_anno : 395452;
* 分类样本:bbox样本:landmark样本 = (75+25):(25+25): 6.8 = 14 : 7 : 1
* factors权重设置 : 0.05 : 0.3 : 3
----------------------------------------------------------------------------------------------------------------------
- 训练&测试
生成PNet的训练数据较快,约5min;RNet的训练数据较慢,大概需要5~7个小时;ONet的训练数据大概需要5个小时
训练单个模型:40mins左右 ,需要训练PNet、RNet、ONet;
测试图片,img_size = 400x600, cost_time = 30ms [GPU], cost_time = 80ms [CPU]
- 结果展示


