未看RL Algorithms部分!未完待续...

视频: https://goo.gl/pyMd6p
环境code:https://goo.gl/jAESt9
demo code:https://github.com/bulletphysics/bullet3/blob/master/examples/pybullet/gym/pybullet_envs/baselines/enjoy_kuka_diverse_object_grasping.py
Abstract
Question--the proliferation of algorithms makes it difficult to discern which particular approach would be best suited for a rich, diverse task like grasping.
Goal--propose a simulated benchmark for robotic grasping that emphasizes off-policy learning and generalization to unseen objects.
Method--evaluate the benchmark tasks against a variety of Q-function estimation methods, a method previously proposed for robotic grasping with deep neural network models, and a novel approach based on a combination of Monte Carlo return estimation and an off-policy correction.
Results--several simple methods provide a surprisingly strong competitor to popular algorithms such as double Qlearning, and our analysis of stability sheds light on the relative tradeoffs between the algorithms.
I. INTRODUCTION
解决grasping problem的有很多方法,比如:
- analytic grasp metrics [43], [36]
- learning-based approaches [2]
虽然基于计算机视觉的的learning-based方法在今年取得了不错的表现[22],但是这些方法不涉及抓取任务的 sequential aspect。
要么选择a single grasp pose [33]
要么重复选择the next most promising grasp greedily[24].
后来引入了RL方法作为robotic grasping in a sequential decision making context下的框架,但是局限于:
single object [34]
simple geometric shapes such as cubes [40].
本实验中,使用realistic simulated benchmark比较了多种RL方法。
由于成功的generalization通常需要训练大量的objects和scenes [33] [24],需要多个视角和control,因此on-policy不适用于多样化的grasping scenarios,而Off-policy reinforcement learning methods不错~
Aim:to understand which off-policy RL algorithms are best suited for vision-based robotic grasping.
Contributions:
- a simulated grasping benchmark for a robotic arm with a two-finger parallel jaw gripper, grasping random objects from a bin.
- present an empirical evaluation of off-policy deep RL algorithms on vision-based robotic grasping tasks. 包括一下6种算法:
1. the grasp success prediction approach proposed by [24],
2. Q-learning [28],
3. path consistency learning (PCL) [29],
4. deep deterministic policy gradient (DDPG) [25],
5. Monte Carlo policy evaluation [39],
6. Corrected Monte-Carlo, a novel off-policy algorithm that extends Monte Carlo policy evaluation for unbiased off-policy learning.
Results show that deep RL can successfully learn grasping of diverse objects from raw pixels, and can grasp previously unseen objects in our simulator with an average success rate of 90%.
II. RELATED WORK
Model-free algorithms for deep RL的两个主要领域:
- policy gradient methods [44], [38], [27], [45]
- value-based methods [35], [28], [25], [15], [16], with actor-critic algorithms combining the two classes [29], [31], [14].
但是Model-free algorithms的通病就是很难tune。
但是Model-free algorithms的相关工作,including popular benchmarks [7], [1], [3]主要集中在
- applications in video games
- relatively simple simulated robot locomotion tasks
而没有我们所需要的,能进行多样化的任务,且能泛化到新环境中。
有很多RL方法应用到了真实的机器人任务上,比如:
- guided policy search methods用于解决一些操作任务:contact-rich, vision-based skills [23], non-prehensile manipulation [10], and tasks involving significant discontinuities [5], [4]
- 或者直接应用model-free algorithms用于机器人学习技能:fitted Qiteration [21], Monte Carlo return estimates [37], deep deterministic policy gradient [13], trust-region policy optimization [11], and deep Q-networks [46]
这些成功的强化学习的应用通常只能tackle individual skills,而不能泛化去完成机器没有训练到的技能。
铺垫了这么多,就是为了强调The goal of this work is to provide a systematic comparison of deep RL approaches to robotic grasping,而且能泛化到新物体in a cluttered environment where objects may be obscured and the environment dynamics are complex(不像[40], [34], and [19]只考虑抓取形状简单的物体,我们的实验是很高级的!)。
用于抓取diverse sets of objects的不是强化学习的其他学习策略,也有很多,这里作者推荐我们看看下面这篇survey。
[2].J. Bohg, A. Morales, T. Asfour, and D. Kragic.
Data-driven grasp synthesisa survey. Transactions on Robotics, 2014.
以前的方法主要依赖这三种sources of supervision:
- human labels [17], [22],
- geometric criteria for grasp success computed offline [12],
- robot self-supervision, measuring grasp success using sensors on the robot’s gripper [33]
后来也有DL的方法出现:[20], [22], [24], [26], [32].
III. PRELIMINARIES
这里说明了论文中的一些符号,不赘述
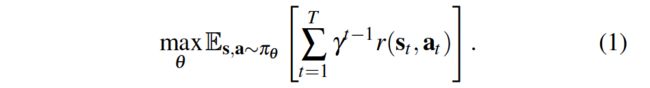
IV. PROBLEM SETUP
- 仿真环境:Bullet simulator
- timesteps:T = 15
- 在最后一个step给出二进制的reward
-
抓取成功的reward:
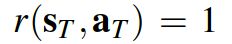 Snip20190226_34.png
Snip20190226_34.png - 抓取失败的reward:0
- 当前的状态st包括当前视角的RGB image和当前的timestep t,用于让policy知道在这个episode结束前还有多少steps,用于做一些决定,如事都有时间做一个pre-grasp manipulation,或者是否要立即移动到a good grasping position。
-
机械臂使用position control of the vertically-oriented gripper进行控制
连续的action使用笛卡尔displacement来表示。其中fai是wrist绕着z轴的旋转
 Snip20190226_36.png
Snip20190226_36.png - 当夹爪移动到低于某个fixed height threshold时,夹爪自动合上
- 新episode开始时,物体的位置和方向在bin中随机放置
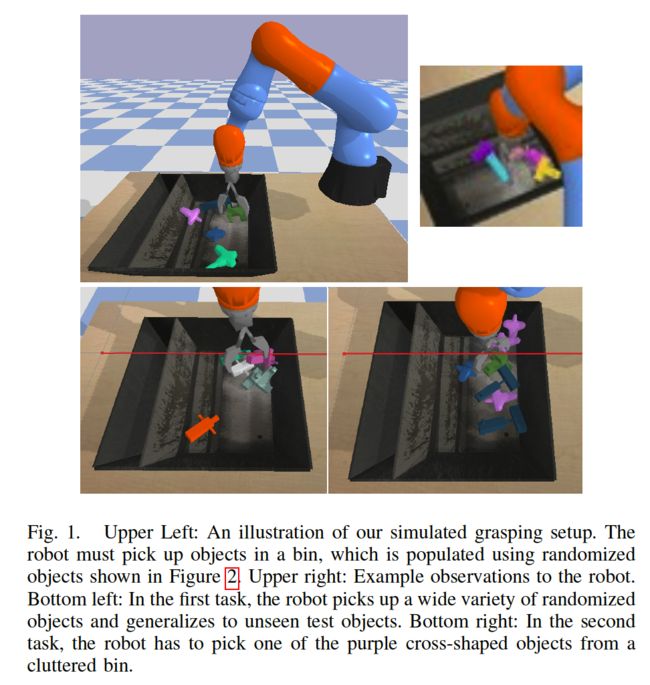
1) Regular grasping.
900个for训练集,100for测试集
每个episode有5个objects in the bin
每20个episodes换一次objects

2) Targeted grasping in clutter
所有的episodes用一样的objects
7个objects中选择3个target objects
当抓取到target objetc时机械臂奖励reward
V. REINFORCEMENT LEARNING ALGORITHMS
A. Learning to Grasp with Supervised Learning
Levine et al. [24]. This method does not consider long-horizon returns, but instead uses a greedy controller to choose the actions
with the highest predicted probability of producing a successful grasp.
B. Off-Policy Q-Learning
C. Regression with Monte Carlo Return Estimates
D. Corrected Monte Carlo Evaluation
E. Deep Deterministic Policy Gradient
F. Path Consistency Learning
G. Summary and Unified View
VI. EXPERIMENTS
评估RL算法的四个要点:
- overall performance
- data-efficiency
- robustness to off-policy data
- hyperparameter sensitivity
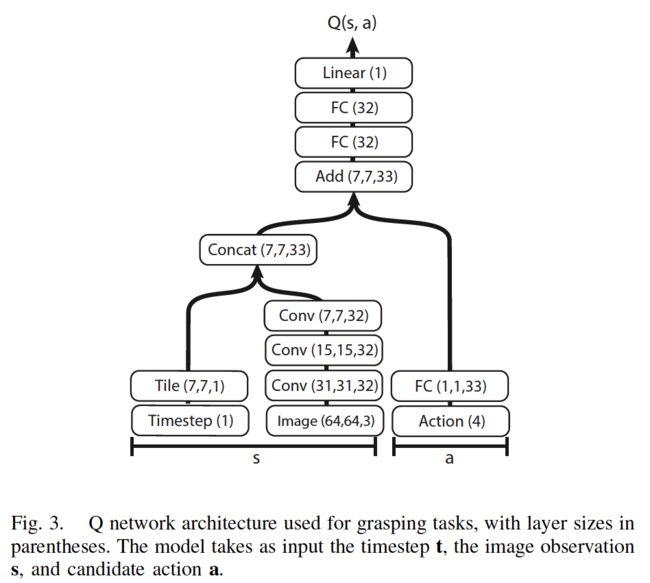
All algorithms use variants of the deep neural network architecture shown in Figure 3 to represent the Q-function.