蜥蜴书(Hands on Machine Learning)读书笔记-第一章 机器学习landscape
A. Geron, Hands on Machine Learning with Scikit-learn and TensorFlow.
第一章 机器学习Landscape
机器学习
机器学习就是从数据中学习。
EPT定义:从经验(E)中学习去完成任务(T),任务完成的表现用P衡量,如果说随着经验E的增加,完成任务T的表现P也会得到提升,那么这个计算机程序就可以说是从数据中学习了(learn from data)。
为什么要用ML?
- 有些问题传统方法用起来过于复杂甚至并没有已知的算法来解决的。 机器学习可以简化代码并且表现的更好。
- ML能增进人类对很多事情的理解:有时候一些未曾预料的模式关系会被机器学习所发现,这将增进人们对问题的认识。比如data mining. 也就是可以对复杂问题或者大量数据有更深的洞见吧。
- 对于变化的环境(fluctuating enviroments):机器学习系统可以很方便地被训练以适用于新数据。
- …
机器学习的主要类型
- 根据是否有人类的监督介入分类:监督学习、无监督学习、半监督学习和强化学习
- Whether or not they can learn incrementally on the fly: online earning versus batch learning
- 根据算法系统是简单地把新数据和已有数据进行对比,还是在训练数据中探测pattern并建立预测模型:instance based versus model-based learning
在你设计一个机器学习算法的时候,以上分类完全可以有互相重叠。
监督学习
- 输入给算法的数据带有了已知的答案–labels.
- 典型的监督学习比如分类问题,其解的结果是判断输入数据属于哪个类别。
- 另一类问题成为回归,输入带很多feature的数据,其输出的答案是一个数值。
几种比较重要的监督学习算法:
- k-Nearest Neighbors
- Linear Regression
- Logistic Regression
- Support Vector Machines(SVMs)
- Decision Trees and Random Forests
- Neural networks [注]
[注]:有些神经网络结构可以是无监督的,比如autoencoders 和 restricted Boltzmann machines. 神经网也可以是半监督的,比如说 在deep belief network 和 unsupervised pretraining(无监督预训练)中.
无监督学习
无监督学习的训练数据是没有label的。
有一些比较重要的无监督学习算法:
- 聚类: k-Means, Hierarchical Cluster Analysis(HCA), Expectation Maximization
- 可视化与维度约化(Visualization and dimensionality reduction): PCA, Keral PCA, Locally-Linear Embedding(LLE), t-distributed Stochastice Negbor EMbedding(t-SNE)
- 关联性规则学习(Association rule learning): Apriori, Eclat
聚类是将输入数据按照自己发现的类别区分开来。HCA会将分开的每个group再进行子类的划分。
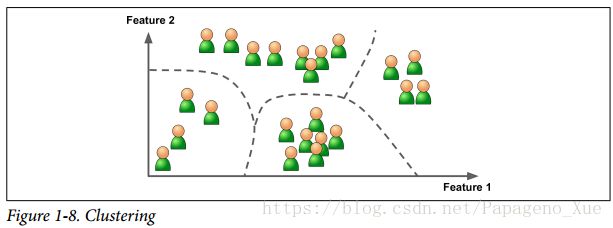
可视化算法:你输入一堆复杂无标签的数据,输出是2D或者3D的数据表示,可以直接画出来了。
数据降维:目标是简化数据的同时并且没有损失太多的信息。一种途径是把几个相互关联的feature合并成一个,也叫feature extraction。通常在给一个机器学习算是输入数据之前尝试进行数据维度约化是个很好的做法。程序会运行的更快,并且占用内存和硬盘更少。
反常性检测:检测一些异常行为

关联性规则学习:挖掘大量数据里面属性之间有趣的关系,比如超市用售卖日志的内容来发现,购买尿布的人一般会同时购买啤酒,买番茄酱和烤肉架的人一般会购买牛排。
半监督学习
半监督学习的算法可以处理部分labeled的训练数据,通常是大量的未加标签的数据和少量的加标签了的数据。
举个例子,集体活动时候,手机里拍了很多照片,你不需要给每个人贴上标签:张三、李四。。。,手机会自动识别不同照片里面的相同的人(clustering),但是它不知道这是谁,你需要给某张照片里面人加上了名字之后所有照片里面都会完成标注。有时候你也需要给两个看起来很像的人添加少量的标签以区分开来。
大多数半监督学习的算法都是无监督学习和监督学习算法的一个组合。比如说 deep belief networks(DBNs)是一个个的restricted Boltzmann machines(RBMs)堆叠起来,RBM以无监督学习的方式一个个接受训练,之后整个系统使用监督学习的方式来微调。
强化学习
强化学习和以上算法有很明显的不同。学习系统称为agent,可以观察环境,选择实施哪些动作actions,并且获得奖励(或者惩罚)作为反馈;算法系统是自己学会什么是最优的策略(policy), 这个策略的目的是最大化奖励积累。

Batch and online Learning
Another criterion used to classify Machine Learning systems is whether or not the
system can learn incrementally from a stream of incoming data.
Batch learning
学习系统并非增量式的学习,系统使用所有可用的数据来训练模型。这样耗费时间和计算资源,因此通常是在offline的情况下操作的。
系统首先训练好之后,在使用中就不在进行学习了,只是把之前学习的东西应用下去。 This is called offline learning.
如果有新的数据更新进来,那么要将原有的数据和新的数据在一起,重新训练模型,再投入使用中去。实际应用中,你可以间隔一段时间再重新训练模型以适应新数据的加入,比如垃圾邮件检测的问题你,你没必要每次多一个垃圾邮件就训练一次垃圾邮件检测模型,每周一次训练或者更长都可以的,这是考虑到训练的资源消耗问题。
Online learning(更合适的名字是步进式学习)
在线学习是一种步进式(incrementally)的学习。你可以一步步的输入数据,或者单个的,或者一组组的(mini-batched)。每个学习的阶段都很快且资源消耗小,因此系统可以在线实时响应很快的学习新数据。 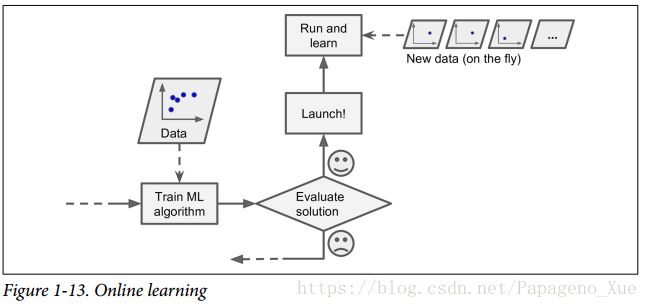
对于数据集比较大,无法一下子在主内存中处理的问题,在线学习是比较适合的,(这也被叫做out-of-core学习)。也就是说计算资源有限的时候在线学习是个不错的选择。
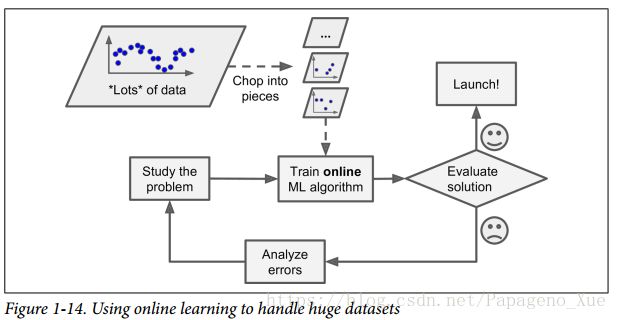
步进式学习里面一个很重要的参数是学习率,它决定系统应该以多快进度学习新数据。如果学习率过大,系统学习接受新数据很快,但是会很快的忘记旧数据中学习到的东西。反过来说,如果学习率太慢,系统又会有很大的惯性,就是前面的数据对后面训练的影响很大,学的也慢,但是这样对输入数据的噪声不敏感。 对于在线学习,数据质量很重要,后面数据不好,学习的结果就会变得很差劲,客户不开心啊。所以要经常监测系统,甚至需要回复到之前学习的状态,监测输入数据的质量也很必要!
Instance-Based Versus Model-Based Learning(按泛化方式分:基于事例的和基于模型的学习)
大多数机器学习的任务是预测,训练完了之后,再对新数据进行预测。在训练数据上具有好的表现是不够的,最终的目的是在未见过的数据上表现良好!
Instance-based learning
Trivial, simple, learning by heart.
Use measure of similarity to make predictions.
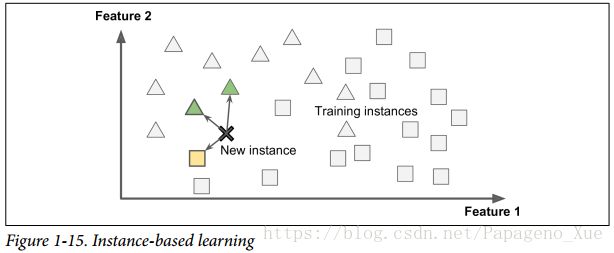
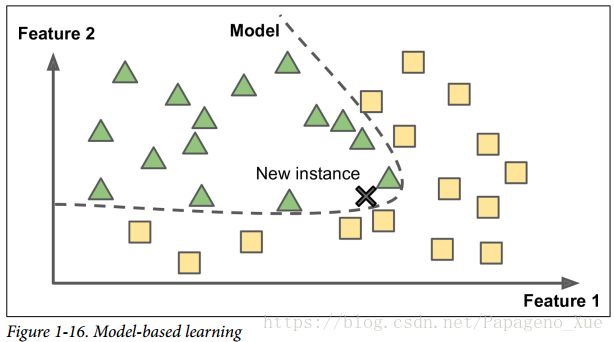
Model-based learning
为输入数据的样例建立一个模型,训练模型的参数,用模型来做预测。
机器学习的main challenges
- 训练数据量不足
- 训练数据不具备代表性(if sampling bias exists)
- 数据质量差: 数据测量的时候噪音大,有错误等等,这会很大地影响学习系统寻找pattern的过程。
- 无关的features: feature selection, feature extraction, creating new featurs by gathering new data.
“garbage in, garbage out…”
_ (以上是数据不好。)
(以下是算法不够好。)_
-
训练数据过拟合(whe the model is too complex relative the amout and noiseness of the training data):
训练数据表现好,泛化差。解决方法:
- 简化模型,比如减少模型参量,减少训练数据的属性数量,或者对模型参数的取值加以限制。
- 获取更多的训练数据;
- 降低训练数据的噪音(修正数据错误,移除异常值)
-
underfitting : 现实比模型要复杂,因此fitting总存在偏差。
how to fix:
- 换用更有效的模型,比如拥有更多模型参数
- feeding better features to the learning alogorithm(feature engineering)
- 降低对模型参数的约束(比如降低正则化超参数)
Testing and Validating
将数据集分为 training set 和 test set (一般习惯将数据集20%-80%分作为测试集和训练集), 用训练集的数据训练模型,用测试集的数据测试模型。 在测试集上计算模型,可以得到对_泛化误差_的估计。
Cross validation
现将数据集分成k个互斥的子集,每次选其中k-1个子集作为训练集,剩下一个作为测试集。可以进行k次训练和测试,最终返回k此训练和测试结果的平均值作为输出的模型。