中国博士生提出最先进AI训练优化器,收敛快精度高,网友亲测:Adam可以退休了...
栗子 鱼羊 晓查 发自 凹非寺
量子位 报道 | 公众号 QbitAI
找到一种快速稳定的优化算法,是所有AI研究人员的目标。
但是鱼和熊掌不可兼得。Adam、RMSProp这些算法虽然收敛速度很快,当往往会掉入局部最优解的“陷阱”;原始的SGD方法虽然能收敛到更好的结果,但是训练速度太慢。
最近,一位来自UIUC的中国博士生Liyuan Liu提出了一个新的优化器RAdam。
它兼有Adam和SGD两者的优点,既能保证收敛速度快,也不容易掉入局部最优解,而且收敛结果对学习率的初始值非常不敏感。在较大学习率的情况下,RAdam效果甚至还优于SGD。
RAdam意思是“整流版的Adam”(Rectified Adam),它能根据方差分散度,动态地打开或者关闭自适应学习率,并且提供了一种不需要可调参数学习率预热的方法。
一位Medium网友Less Wright在测试完RAdam算法后,给予了很高的评价:
RAdam可以说是最先进的AI优化器,可以永远取代原来的Adam算法了。
目前论文作者已将RAdam开源,FastAI现在已经集成了RAdam,只需几行代码即可直接调用。
补众家之短
想造出更强的优化器,就要知道前辈们的问题出在哪:
像Adam这样的优化器,的确可以快速收敛,也因此得到了广泛的应用。
但有个重大的缺点是不够鲁棒,常常会收敛到不太好的局部最优解 (Local Optima) ,这就要靠预热 (Warmup)来解决——
最初几次迭代,都用很小的学习率,以此来缓解收敛问题。
为了证明预热存在的道理,团队在IWSLT’14德英数据集上,测试了原始Adam和带预热的Adam。
结果发现,一把预热拿掉,Transformer语言模型的训练复杂度 (Perplexity) ,就从10增到了500。
另外,BERT预训练也是差不多的情况。
为什么预热、不预热差距这样大?团队又设计了两个变种来分析:
缺乏样本,是问题根源
一个变种是Adam-2k:
在前2000次迭代里,只有自适应学习率是一直更新的,而动量 (Momentum) 和参数都是固定的。除此之外,都沿袭了原始Adam算法。
实验表明,在给它2000个额外的样本来估计自适应学习率之后,收敛问题就消失了:
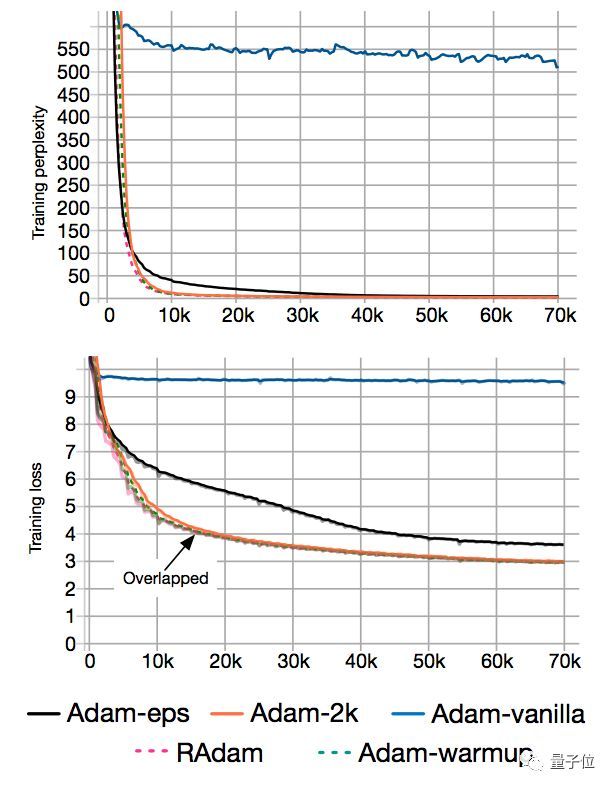
另外,足够多的样本可以避免梯度分布变扭曲 (Distorted) :


这些发现证明了一点:早期缺乏足够数据样本,就是收敛问题的根源。
下面就要证明,可以通过降低自适应学习率的方差来弥补这个缺陷。
降低方差,可解决问题
一个直接的办法就是:

把ψ-cap里面的ϵ增加。假设ψ-cap(. ) 是均匀分布,方差就是1/12ϵ^2。
这样就有了另一个变种Adam-eps。开始把ϵ设成一个可以忽略的1×10^-8,慢慢增加,到不可忽略的1×10^-4。
从实验结果看,它已经没有Adam原本的收敛问题了:
这就证明了,真的可以通过控制方差来解决问题。另外,它和Adam-2k差不多,也可以避免梯度分布扭曲。
然而,这个模型表现比Adam-2k和带预热的Adam差很多。
推测是因为ϵ太大,会给自适应学习率带来重大的偏差 (Bias) ,也会减慢优化的过程。
所以,就需要一个更加严格的方法,来控制自适应学习率。
论文中提出,要通过估算自由度ρ来实现量化分析。
RAdam定义
RAdam算法的输入有:步长αt;衰减率{β1, β2},用于计算移动平均值和它的二阶矩。
输出为θt。
首先,将移动量的一阶矩和二阶矩初始化为m0,v0,计算出简单移动平均值(SMA)的最大长度ρ∞←2/(1-β2)-1。
然后按照以下的迭代公式计算出:第t步时的梯度gt,移动量的二阶矩vt,移动量的一阶矩mt,移动偏差的修正和SMA的最大值ρt。

如果ρ∞大于4,那么,计算移动量二阶矩的修正值和方差修正范围:

如果ρ∞小于等于4,则使用非自适应动量更新参数:
![]()
以上步骤都完成后,得出T步骤后的参数θT。
测试结果
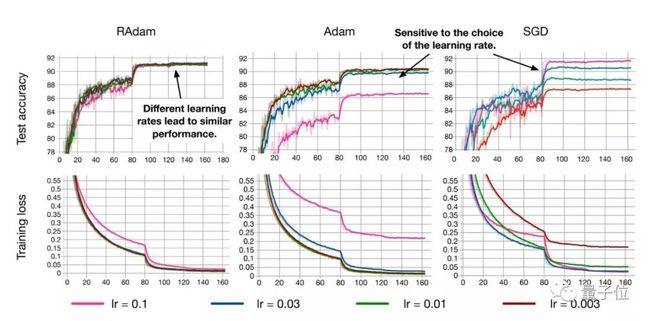
RAdam在图像分类任务CIFAR-10和ImageNet上测试的结果如下:
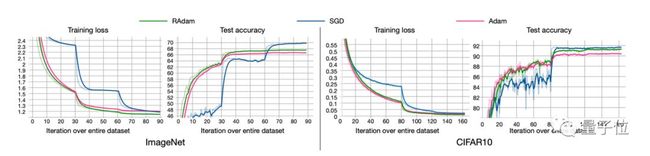
尽管在前几个周期内整流项使得RAdam比Adam方法慢,但是在后期的收敛速度是比Adam要更快的。
尽管RAdam在测试精度方面未能超越SGD,但它可以带来更好的训练性能。
此外,RAdam算法对初始学习率是具有鲁棒性的,可以适应更宽范围内的变化。在从0.003到0.1一个很宽的范围内,RAdam表现出了一致的性能,训练曲线末端高度重合。
亲测过的网友Less Wright说,RAdam和他今年测试的许多其它论文都不一样。
其他方法常常是在特定数据集上有良好的效果,但是放在新的数据集上往往表现不佳。
而RAdam在图像分类、语言建模,以及机器翻译等等许多任务上,都证明有效。
(也侧面说明,机器学习的各类任务里,广泛存在着方差的问题。)
Less Wright在ImageNette上进行了测试,取得了相当不错的效果(注:ImageNette是从ImageNet上抽取的包含10类图像的子集)。在5个epoch后,RAdam已经将准确率快速收敛到86%。
如果你以为RAdam只能处理较小数据集上的训练,或者只有在CNN上有较好的表现就大错特错了。即使大道有几十亿个单词的数据集的LSTM模型,RAdam依然有比Adam更好的表现。
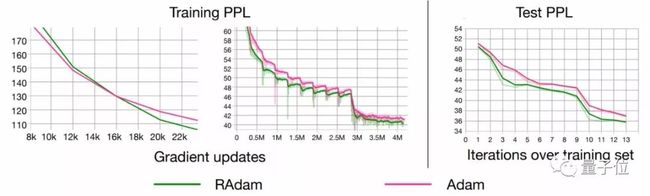
总之,RAdam有望提供更好的收敛性、训练稳定性,以及几乎对所有AI应用都用更好的通用性。
关于作者
论文的作者Liyuan Liu是一位90后,本科毕业于中国科学技术大学,曾在微软亚洲研究院实习。而这项工作,也得益于与微软的合作。

早在本科期间,Liyuan Liu就师从国家杰出青年基金获得者,中科大陈恩红教授,以第一作者的身份在ICDM发表过文章。

2016年,Liyuan Liu小哥本科毕业,加入了美国伊利诺伊大学香槟分校数据挖掘小组(DMG),成为美国计算机协会和IEEE院士韩家炜教授课题组的一名CS博士,从事NLP研究。
读博以来,Liyuan Liu开始在各大顶会上崭露头角。在2018年NLP领域国际顶会EMNLP当中,他的一作论文《Efficient Contextualized Representation: Language Model Pruning for Sequence Labeling》就被收录为口头报告。

又是一位闪闪发光的少年英才啊。
论文地址:
源代码:
— 完 —
活动推荐 | AI计算领域技术盛会
2019人工智能计算大会将于8月27日-28日在北京举办,旨在围绕人工智能的产业需求研讨AI计算,促进AI技术创新、合作发展与人才培养。
门票原价1099元,量子位用户专享福利,识别下图即可限时免费报名。


量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「好看」吧 !