腾讯云分布式数据库可用性系统实践
欢迎大家前往腾讯云社区,获取更多腾讯海量技术实践干货哦~
在分布式环境当中,总是会遇到诸如 主机宕机 或 网络故障 等各种影响系统可用性的情况发生。轻则会导致投诉,重则导致企业核心数据的丢失,影响企业业绩和商誉。而如何确保分布式系统运行正常,应对各种故障场景,保证系统始终处于高可用状态是每个企业研究的方向之一。
腾讯云数据库技术专家,赵海明在PostgreSQL 2017中国技术大会上,以 腾讯分布式数据库 Tbase 的可靠性系统为例,为大家分享了保障分布式系统可靠性的一些基本思路。
1、Tbase,腾讯自研全功能分布式关系数据库
Tbase 是腾讯在开源的分布式数据库PosgreSQL-XC(简称PGXC)基础上,研发的一款全功能分布式关系数据库系统,相较于PGXC,Tbase 通过在内核中创造性的引入 GROUP 的概念,提出双 KEY 分布策略,有效的解决了数据倾斜的问题;同时,根据数据的时间戳,将数据分为冷数据和热数据,分别存储与不同的存储设备中,有效的解决了存储成本的问题。本文主要以Tbase举例,自上而下向读者深度剖析保障Tbase 可靠性的两大系统:灾备系统 和 冷备系统 。

图 1 Tbase 架构
2、分布式系统容灾中的“脑裂”情况
分布式系统,通常是由若干台物理服务器通过网络搭建而成的,与单机系统不同的是,分布式系统通常由多台设备组成。主机(物理服务器)宕机 或者 网络故障 是大概率事件,而* 脑裂* 场景则是分布式系统中的常见问题(如下图)。
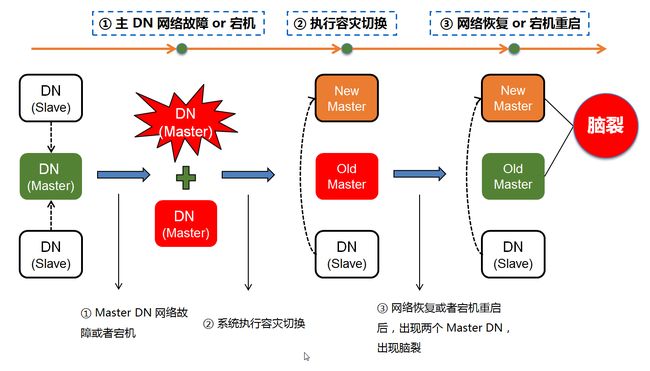
图 2 Tbase 灾备系统——脑裂故障场景
当系统出现节点异常后,为避免脑裂,我们通常需要一个全局的调度集群,出现故障时,通过全局调度集群锁住原Master节点,并通过内部选举,提升某最优Slave节点为Master。到原有故障Master恢复后,在将其降级为Slave重新加入集群,使得系统仍然是一主两备,保障系统始终处于一个高可用的状态。
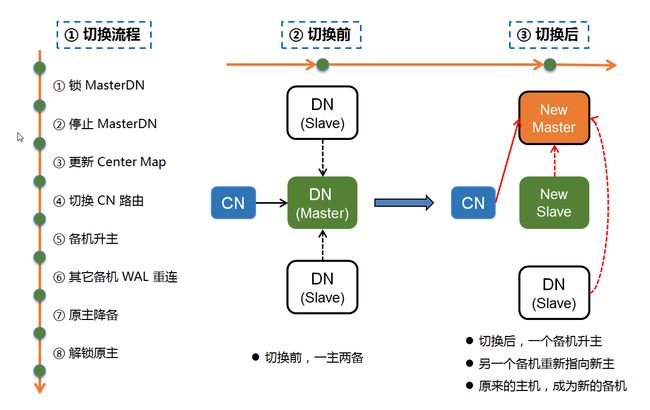
图 3 Tbase 灾备系统——灾备目标
深入到分布式系统调度内部过程,又需要去解决孤岛检测和角色校验两个问题。
* 孤岛检测: 解决由于 Master DN** 网络故障**恢复后,导致 Master DN 脑裂的问题。
* 角色校验: 解决由于 Master DN 主机宕机重启后,导致 Master DN 脑裂的问题。

图 4 Tbase 灾备方案——Master DN 故障
分布式系统的某一主机网络故障时,某一个节点就行是没有通讯的孤岛,因此孤岛检测很形象的比喻这种脑裂场景。因此分布式系统通常将孤岛检测拆分为以下几个步骤
1.检测孤岛:分布式系统通过部署于每个节点的Agent,向集群所有主机发送网络心跳,实时检测连通性。若无法连通Center,意味着自己成为网络孤岛。
2.杀死实例:Agent 发现自己成为网络孤岛后,会主动发起请求杀死本机所有CN/DN实例。
3**.容灾切换:Center 监听到集群 Master DN 异常(或无法连通时),主动容灾切换,以恢复数据库服务。由于原Master DN已被Agent杀死,整个系统只有新 Master DN 提供读写服务,因此系统没有 Master DN 脑裂。**
4.恢复主备:孤岛主机网络恢复后,Center正常连通Agent后,会向该主机上的 Agent 发起做备指令,让原 Master DN 降级成为一个全新的 Slave DN,以恢复系统一主两备的高可用模式。
通过 Agent 的* 孤岛检测* 机制,Tbase 在任意 Master DN 网络故障情况下,都能保证系统一直处于高可用的状态。

图 5Tbase 灾备方案——孤岛检测
当发生 主机宕机 后,分布式系统就需要 通过 角色校验 机制来解决系统 的脑裂问题,如下图所示,仍然以Tbase举例:
1**.宕机切换**:当 Master DN 所在主机发生宕机后,Center发起状态仲裁,生成容灾指令,对该主机上的 Master DN 执行容灾切换,容灾切换后,Tbase 系统中的每组 DN 节点都只有唯一的一个 Master DN 对外提供读写服务。
2.角色校验:当故障主机宕机重启后,Agent 和 Center 会通过心跳包对 Agent 所监控的节点执行一次 主备角色校验。由于宕机后,Center 对故障主机上的原 Master DN 执行了容灾切换,因此 Center 认为该主机上的该 DN 节点角色为 Salve DN,但是在容灾切换的过程中,由于原 Master DN 主机因为宕机,无法接收容灾指令,因此宕机重启后,该主机上的 Agent 认为该 DN 节点角色仍然为 Master DN,此时 Agent 和 Center 发生角色校验失败,
3.杀死实例:角色校验失败后,Agent 会杀死本机所有 CN/DN 节点,以防止主机宕机重启后,原 Master DN 和新 Master DN 并存而出现系统脑裂。
4.恢复主备:在 Agent 由于角色校验失败将 CN/DN 杀死后,Center 会向原 Master DN 所在的 Agent 发起做备指令,将原 Master DN 降级成为新的 Slave DN,以恢复系统一主两备的高可用模式。
通过 Agent 和 Center 的 角色校验 机制,Tbase 在任意 Master DN主机宕机重启的情况下,也能保证系统一直处于高可用的状态。

图 6 Tbase 灾备方案——角色校验
3、两地三中心容灾方案
解决了脑裂问题后,面向分布式系统的另外一个问题是出现机房级故障怎么办? Tbase目前应用于微信支付系统,因此Tbase的在设计时就考虑了两地三中心的架构(如下图所示)。简单来说,通过让Datanode(数据) 节点实现,同城节点强同步,异地节点异步同步的3节点部署架构实现高可用。同时,让每台主机部署Agent,负责采集各个节点运行状态,上报给所有 Center,同时负责执行 Center 下发的各种操作指令。Center负责状态汇总,并将状态信息写入 ZK 集群;单监听各个节点的运行状态,异常时发起仲裁流程,根据仲裁结果,发起容灾切换流程。当然,Center也支持接收外部用户操作指令,生成分布式指令计划,下发给 Agent 执行,并监控 Agent 的执行状态;

图 7Tbase 灾备方案——两地三中心
4、分布式系统容灾中的调度节点容灾问题
前文阐述了通过* 脑裂,两地三中心*方案, 为了解决分布式系统中的节点故障的问题,系统引入了两个组件 Agent、Center,作为调度模块。而如果在运行过程中,Agent、Center 本身也会出现主机宕机、网络故障等异常场景呢?我们梳理了分布式的调度系统中常见的故障:
故障一:Center 宕机:在执行容灾过程当中,Center 主机发生宕机,导致容灾流程中途失败?
**故障二:状态误判:**Tbase 系统本身运行正常,但由于 Center 和 Agent 之间的网络故障,Center 对 Agent 所监控的 DN 状态发生误判,导致 Center 在 Tbase 系统正常运行的情况下,发出错误的容灾倒换指令?
**故障三:指令超时:**Center 向 Agent 发送的指令都是通过网络包进行发送,会出现指令丢失或者指令超时?
**故障四:指令乱序:**Agent 在执行指令的过程中,会向 Center 反馈自身的执行状态,由于各种原因,当 Agent 回复的指令出现了乱序怎么办?
针对上述故障场景,Tbase 容灾系统提出了如下解决方案:
- 任务接管:引入主备 Center,用于解决 Center 在容灾流程中发生宕机或者网络故障等问题。
- 状态仲裁:引入 ZK 集群,保证所有节点状态的一致性,避免 Center 状态误判,发起误容灾。
- 超时重试:通过超时重试机制,解决 Agent、Center 网络通信过程中,出现的网络超时的问题。
- 指令 ID:对每条指令分配全局唯一 ID 号进行编码,解决 Agent、Center 网络通信过程中,出现指令乱序的问题。
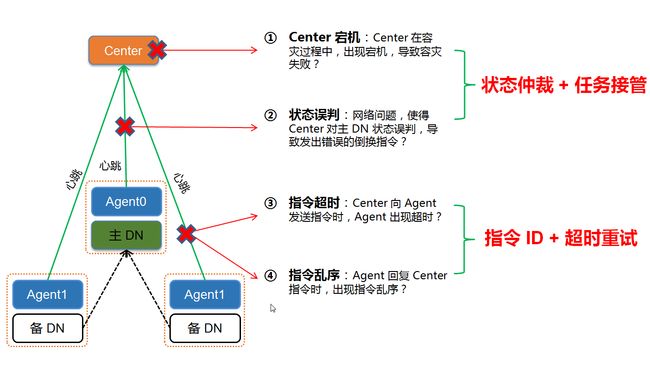
图 8 Tbase 灾备方案——Center、Agent 故障
通过 状态仲裁 和 任务接管 解决Center误容灾和 Center 容灾过程中发生宕机的问题,如下图图所示,分布式系统可以做如下操作:
1.节点异常:当 DN 节点异常后,Agent 采集节点状态信息,将异常状态上报给所有 Center。
2.状态仲裁:当 Master Center 收到节点状态异常后,不会立即发起容灾流程,而是向所有 Slave Center 发起状态仲裁请求。
3**.状态获取:**Slave Center 收到状态请求后,向 ZK 拉取节点状态,并回复给 Master Center。
4.启动容灾:当超过多半 Slave Center 认定该节点异常后,Master Center 发起容灾流程。
5.**执行容灾:**Master Center 生成容灾指令计划,并向各个 Agent 发起容灾指令,并监听 Agent 的指令执行状态,同时将容灾日志持久化到配置库。
6.Center 宕机:在容灾过程中,如果 Master Center 发生宕机,ZK 会发起选主流程,从 Slave Center 中选择一个新的 Master Center。
7.任务接管:新的 Master Center 选定后,会从配置库中拉取容灾日志,重新生成容灾指令计划,继续向 Agent 发送容灾指令,完成剩余容灾流程。
8.Center 重启:原 Master Center 宕机重启后,从 ZK 获取自身角色,发现已经被降级成 Slave,不再恢复容灾流程,自动转换成新的 Slave Center 运行,保证系统不会出现 Center 脑裂。
通过 状态仲裁 保证DN 状态的一致性,避免因Center对DN状态的误判,发起误容灾;通过 任务接管 确保在 Center 宕机 等故障场景下,容灾仍然能够继续执行;通过 ZK 选主,保证系统在任何时刻都只能够存在唯一的一个 Master Center,避免出现 Center 脑裂。
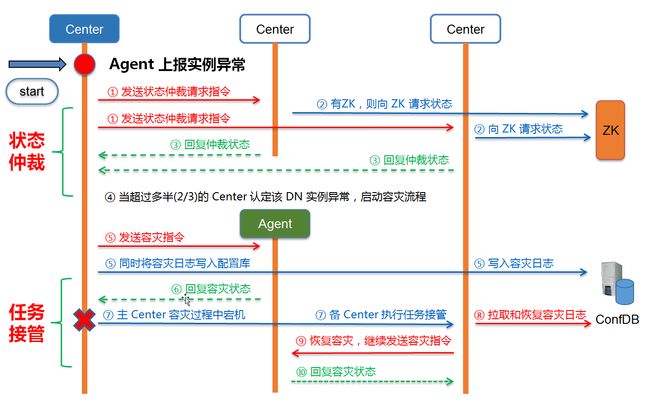
图 9 Tbase 灾备方案——状态仲裁 + 任务接管
引入* 超时重试* 和 指令 ID 解决 Agent、Center 网络消息超时和消息乱序的问题,如上图所示,具体流程如下:
1.**超时重试:**Center 发送指令给 Agent 后,会监听指令的执行状态,超过一定时间没有收到 Agent 的回复,执行指令重试。
2**.指令 ID:**Center 在下发每一条指令的时候,会对指令进行编码,赋予一个全局递增的唯一 ID 号,一起下发给 Agent,Agent 在回复 Center 执行状态时,必须将原来的指令 ID 一起回复给 Center。
3.ID 递增:当 Center 收到 Agent 回复后,根据需要选择继续监听,还是下发下一个指令,如果下发下一个指令,Center 首先将指令 ID 递增,然后再下发指令。
4.消息过滤:递增 ID,一方面表示 ,Center 更新了本身的任务状态,另一方面表示,针对 Agent 回复的消息,如果 ID 小于Center 当前的 ID 号,则 Center 不予处理,直接过滤即可。
通过 超时重试 确保在网络抖动等异常情况下,Center 仍然能够正常发送指令计划;通过 指令 ID 确保 Center 能够时时更新自身的任务状态,忽略 Agent 反馈的过期消息,防止由于网络问题导致 Agent 回复的消息出现指令乱序。

图 10 Tbase 灾备方案——超时重试 + 指令 ID
5、分布式系统的冷备系统
当然,还有一种极少见但仍然会存在的异常情况,即整个数据库集群彻底故障。此时,为了进一步保障分布式系统的数据可靠性,建议在现有高可用容灾的基础上,仍然部署冷备系统。而 Tbase基于PITR特性开发了自动冷备系统,在 Tbase 运行过程中,定期将存量数据和增量数据备份到 HDFS。这样,在诸如磁盘不可修复损坏等极端场景下, Tbase 仍然能够执行数据恢复。
而为了提升冷备效率,同时降低冷备对业务资源的占用,Tbase 的将冷备流程下放到数据节点的备机执行,同时对冷备的上传机制进行了优化,实现 Tbase 的冷备和增备不落盘透写 HDFS,以减少本地磁盘 I/O压力,同时还能做到对网络资源灵活控制,进一步降低系统负载。
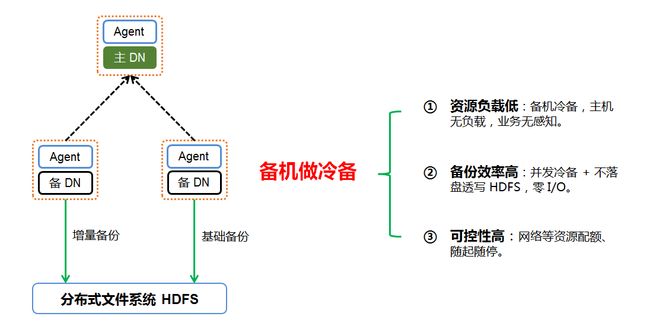
图 11 Tbase 冷备系统
6、最后再说一句
目前,Tbase 已经支持在专有云(私有化)中部署,且很好的兼容PostgreSQL协议,解决了存储成本、数据倾斜、在线扩容、分布式事务、跨节点JOIN等敏感问题,目前Tbase已经在微信支付、电子政务大厅、公安等系统上稳定运行。
相关阅读
一站式满足电商节云计算需求的秘诀
电商月将至,腾讯云DCDB助力电商企业应对支付洪峰
为什么 SQL 正在击败 NoSQL,这对未来的数据意味着什么
此文已由作者授权腾讯云技术社区发布,转载请注明文章出处
原文链接:https://cloud.tencent.com/community/article/566868