管道容量以及管道底层缓冲区如何组织
一.管道容量:管道容量分为pipi capacity 和 pipe_buf .这两者的区别在于pipe_buf定义的是内核管道缓冲区的大小,这个值的大小是由内核设定的,这个值仅需一条命令就可以查到;而pipe capacity指的是管道的最大值,即容量,是内核内存中的一个缓冲区。
pipe_buf: 命令:ulimit -a
在终端输入该命令就会出现如下一表:
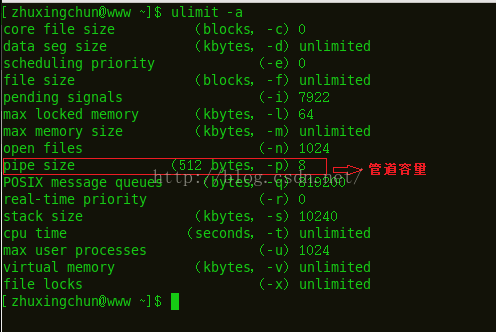
管道容量 sizeof(pipe_buf)= 512 bytes* 8 = 4kb
pipi capacity:
当管道满的时候 O_NONBLOCK disable: write调用阻塞,直到有进程读走数据
O_NONBLOCK enable:调用返回-1,errno值为EAGAIN
pipi capacity的大小需要写一段程序去检测,代码如下所示:
-
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #define ERR_EXIT(m) \
- do { \
- perror(m); \
- exit(EXIT_FAILURE); \
- } while(0)
- int main(int argc, char *argv[])
- {
- int pipefd[2];
- if (pipe(pipefd) == -1)
- ERR_EXIT("pipe error");
- int ret;
- int count = 0;
- int flags = fcntl(pipefd[1], F_GETFL);
- fcntl(pipefd[1], F_SETFL, flags | O_NONBLOCK); // 设置为非阻塞
- while (1)
- {
- ret = write(pipefd[1], "A", 1);
- if (ret == -1)
- {
- printf("err=%s\n", strerror(errno));
- break;
- }
- count++;
- }
- printf("count=%d\n", count); //管道容量
- return 0;
- }

由此图可知 pipe capacity的大小为 65536
二.管道缓冲区
1、管道(pipe)
管道是进程间通信的主要手段之一。一个管道实际上就是个只存在于内存中的文件,对这个文件的操作要通过两个已经打开文件进行,它们分别代表管道的两端。管道是一种特殊的文件,它不属于某一种文件系统,而是一种独立的文件系统,有其自己的数据结构。根据管道的适用范围将其分为:无名管道和命名管道。
● 无名管道
主要用于父进程与子进程之间,或者两个兄弟进程之间。在Linux系统中可以通过系统调用建立起一个单向的通信管道,且这种关系只能由父进程来建立。因此,每个管道都是单向的,当需要双向通信时就需要建立起两个管道。管道两端的进程均将该管道看做一个文件,一个进程负责往管道中写内容,而另一个从管道中读取。这种传输遵循“先入先出”(FIFO)的规则。
● 命名管道
命名管道是为了解决无名管道只能用于近亲进程之间通信的缺陷而设计的。命名管道是建立在实际的磁盘介质或文件系统(而不是只存在于内存中)上有自己名字的文件,任何进程可以在任何时间通过文件名或路径名与该文件建立联系。为了实现命名管道,引入了一种新的文件类型——FIFO文件(遵循先进先出的原则)。实现一个命名管道实际上就是实现一个FIFO文件。命名管道一旦建立,之后它的读、写以及关闭操作都与普通管道完全相同。虽然FIFO文件的inode节点在磁盘上,但是仅是一个节点而已,文件的数据还是存在于内存缓冲页面中,和普通管道相同。
管道通讯如下图:
管道通讯带来的问题:管道容量不像其他文件一样不加检索的增长
1.使用单个固定缓冲区也会带来问题,比如在写管道时可能变满,当这种情况发生时,随后对管道的write()调用将默认地被阻塞,等待某些数据被读取,以便腾出足够的空间供write()调用写。
2.读取进程也可能工作得比写进程快。当所有当前进程数据已被读取时,管道变空。当这种情况发生时,一个随后的read()调用将默认地被阻塞,等待某些数据被写入,这解决了read()调用返回文件结束的问题。
注意,从管道读数据是一次性操作,数据一旦被读,它就从管道中被抛弃,释放空间以便写更多的数据。
管道的结构:在Linux 中,管道的实现并没有使用专门的数据结构,而是借助了文件系统的file 结构和VFS 的索引节点inode。通过将两个 file 结构指向同一个临时的 VFS 索引节点,而这个 VFS 索引节点又指向一个物理页面而实现的。如下图所示。
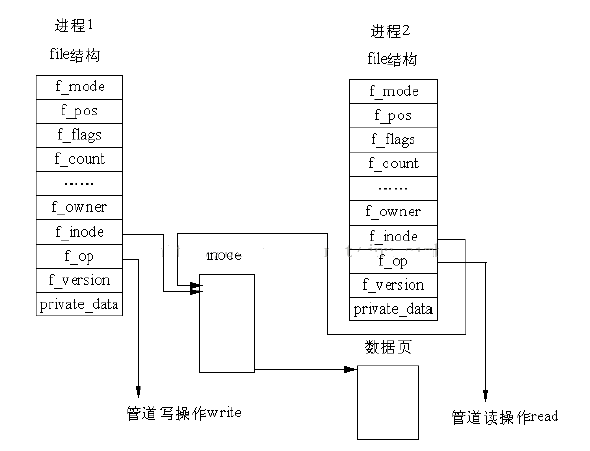
注意,在管道中的数据始终以和写数据相同的次序来进行读,这表示lseek()系统调用对管道不起作用。
转载出处:http://blog.csdn.net/csdnldsg/article/details/51813366
.png)
一,关于匿名管道
匿名管道的通信步骤
(1)父进程调用pipe开辟管道,得到两个文件描述符指向管道的两端;
管道的5个特性:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
|
#include
#include
#include
#include
#include
#include
int
main
(
)
{
int
_pipe
[
2
]
;
int
ret
=
pipe
(
_pipe
)
;
if
(
-
1
==
ret
)
{
printf
(
"creat pipe error! errno code is:%d\n"
,
errno
)
;
return
1
;
}
pid_t
id
=
fork
(
)
;
if
(
id
<
0
)
{
printf
(
"fork error!\n"
)
;
return
2
;
}
else
if
(
0
==
id
)
//child
{
close
(
_pipe
[
0
]
)
;
//close read fd
int
i
=
0
;
char
*
_mesg_c
=
NULL
;
while
(
i
<
10
)
{
_mesg_c
=
"i am a child!"
;
write
(
_pipe
[
1
]
,
_mesg_c
,
strlen
(
_mesg_c
)
+
1
)
;
sleep
(
1
)
;
i
++
;
}
close
(
_pipe
[
1
]
)
;
//close write fd
exit
(
1
)
;
}
else
//father
{
close
(
_pipe
[
1
]
)
;
char
_mesg
[
100
]
;
int
j
=
0
;
while
(
j
<
100
)
{
memset
(
_mesg
,
'\0'
,
sizeof
(
_mesg
)
)
;
ssize_t
ret
=
read
(
_pipe
[
0
]
,
_mesg
,
sizeof
(
_mesg
)
)
;
printf
(
"%s:code is:%d\n"
,
_mesg
,
ret
)
;
j
++
;
}
if
(
waitpid
(
id
,
NULL
,
0
)
<
0
)
{
return
3
;
}
}
return
0
;
}
|
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
#include
#include
#include
#include
#include
int
main
(
)
{
int
_pipe
[
2
]
;
int
ret
=
pipe
(
_pipe
)
;
if
(
-
1
==
ret
)
{
printf
(
"creat pipe error! errno code is:%d\n"
,
errno
)
;
return
1
;
}
pid_t
id
=
fork
(
)
;
if
(
id
<
0
)
{
printf
(
"fork error!"
)
;
return
2
;
}
else
if
(
0
==
id
)
//child
{
close
(
_pipe
[
0
]
)
;
//close read fd
int
i
=
0
;
char
*
_mesg_c
=
NULL
;
while
(
i
<
20
)
{
if
(
i
<
10
)
{
_mesg_c
=
"i am a child!"
;
write
(
_pipe
[
1
]
,
_mesg_c
,
strlen
(
_mesg_c
)
+
1
)
;
}
sleep
(
1
)
;
i
++
;
}
close
(
_pipe
[
1
]
)
;
//close write fd
}
else
//father
{
close
(
_pipe
[
1
]
)
;
char
_mesg
[
100
]
;
int
j
=
0
;
while
(
j
<
10
)
{
memset
(
_mesg
,
'\0'
,
sizeof
(
_mesg
)
)
;
int
ret
=
read
(
_pipe
[
0
]
,
_mesg
,
sizeof
(
_mesg
)
)
;
printf
(
"%s:code is:%d\n"
,
_mesg
,
ret
)
;
j
++
;
}
if
(
waitpid
(
id
,
NULL
,
0
)
<
0
)
{
return
3
;
}
}
return
0
;
}
|
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
#include
#include
#include
#include
#include
int
main
(
)
{
int
_pipe
[
2
]
;
int
ret
=
pipe
(
_pipe
)
;
if
(
-
1
==
ret
)
{
printf
(
"creat pipe error! errno code is:%d\n"
,
errno
)
;
return
1
;
}
pid_t
id
=
fork
(
)
;
if
(
id
<
0
)
{
printf
(
"fork error!"
)
;
return
2
;
}
else
if
(
0
==
id
)
//child
{
close
(
_pipe
[
0
]
)
;
//close read fd
int
i
=
0
;
char
*
_mesg_c
=
NULL
;
while
(
i
<
20
)
{
if
(
i
<
10
)
{
_mesg_c
=
"i am a child!"
;
write
(
_pipe
[
1
]
,
_mesg_c
,
strlen
(
_mesg_c
)
+
1
)
;
}
sleep
(
1
)
;
i
++
;
}
}
else
//father
{
close
(
_pipe
[
1
]
)
;
char
_mesg
[
100
]
;
int
j
=
0
;
while
(
j
<
3
)
{
memset
(
_mesg
,
'\0'
,
sizeof
(
_mesg
)
)
;
int
ret
=
read
(
_pipe
[
0
]
,
_mesg
,
sizeof
(
_mesg
)
)
;
printf
(
"%s:code is:%d\n"
,
_mesg
,
ret
)
;
j
++
;
}
close
(
_pipe
[
0
]
)
;
sleep
(
10
)
;
if
(
waitpid
(
id
,
NULL
,
0
)
<
0
)
{
return
3
;
}
}
return
0
;
}
|
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
#include
#include
#include
#include
#include
int
main
(
)
{
int
_pipe
[
2
]
;
int
ret
=
pipe
(
_pipe
)
;
if
(
-
1
==
ret
)
{
printf
(
"creat pipe error! errno code is:%d\n"
,
errno
)
;
return
1
;
}
pid_t
id
=
fork
(
)
;
if
(
id
<
0
)
{
printf
(
"fork error!"
)
;
return
2
;
}
else
if
(
0
==
id
)
//child
{
close
(
_pipe
[
0
]
)
;
//close read fd
int
i
=
0
;
char
*
_mesg_c
=
NULL
;
while
(
1
)
{
_mesg_c
=
"i am a child!"
;
write
(
_pipe
[
1
]
,
_mesg_c
,
strlen
(
_mesg_c
)
+
1
)
;
// sleep(1);
i
++
;
printf
(
"%d\n"
,
i
)
;
}
}
else
//father
{
close
(
_pipe
[
1
]
)
;
sleep
(
1
)
;
if
(
waitpid
(
id
,
NULL
,
0
)
<
0
)
{
return
3
;
}
}
return
0
;
}
|
命名管道:
一 .概念
二:命名管道实现函数:mkfifo
函数原型:
#include
#include
int mkfifo(const char* pathname,mode_t mode)
函数调用成功都返回0,失败都返回-1
示例:
umask(0);
if (mkfifo("/tmp/fifo",S_IFIFO|0666) == -1)
{
perror("mkfifo error!");
exit(1);
}
三:注意
“S_IFIFO|0666”指明创建一个命名管道且存取权限为0666,即创建者、与创建者同组的 用户、其他用户对该命名管道的访问权限都是可读可写( 这里要注意umask对生成的
管道文件权限的影响 )。
命名管道创建后就可以使用了,命名管道和管道的使用方法基本是相同的。只是使用命 名管道时,必须先调用open()将其打开。因为命名管道是一个存在于硬盘上的文件,而管道
是存在于内存中的特殊文件。
需要注意的是,调用open()打开命名管道的进程可能会塞。但如果同时用读写方式 (O_RDWR)打开,则一定不会导致阻塞;如果以只读方式(O_RDONLY)打开,则调 用open()函数的进程将会被阻塞直到有写方打开管道;同样以写方式(O_WRONLY)打开 也会阻塞直到有读方式打开管道。
write:
.png)
Read:
然后运行两个文件,就可以实现进程间的通信(这里不贴图了)。
匿名实现机制:
实现细节:
关于管道的读写
管道实现的源代码在fs/pipe.c中,在pipe.c中有很多函数,其中有两个函数比较重要,即管道读函数pipe_read()和管道写函数pipe_wrtie()。管道写函数通过将字节复制到 VFS 索引节点指向的物理内存而写入数据,而管道读函数则通过复制物理内存中的字节而读出数据。当然,内核必须利用一定的机制同步对管道的访问,为此,内核使用了锁、等待队列和信号。
当写进程向管道中写入时,它利用标准的库函数write(),系统根据库函数传递的文件描述符,可找到该文件的 file 结构。file 结构中指定了用来进行写操作的函数(即写入函数)地址,于是,内核调用该函数完成写操作。写入函数在向内存中写入数据之前,必须首先检查 VFS 索引节点中的信息,同时满足如下条件时,才能进行实际的内存复制工作:
* 内存中有足够的空间可容纳所有要写入的数据;
* 内存没有被读程序锁定。
如果同时满足上述条件,写入函数首先锁定内存,然后从写进程的地址空间中复制数据到内存。否则,写入进程就休眠在 VFS 索引节点的等待队列中,接下来,内核将调用调度程序,而调度程序会选择其他进程运行。写入进程实际处于可中断的等待状态,当内存中有足够的空间可以容纳写入数据,或内存被解锁时,读取进程会唤醒写入进程,这时,写入进程将接收到信号。当数据写入内存之后,内存被解锁,而所有休眠在索引节点的读取进程会被唤醒。
pipe_read()
1.获取索引节点的i_sem信号量 //我要读了
2.判断缓冲区 是否 空 ,或阻塞 //空不空啊?
阻塞: a .调用prepare_wait() 把当前进程(cur)加到等待队列
b.释放索引节信号量
c.调用 schedule()
d.cur一旦被唤醒,从等待队列中删除 。拷贝所有请求字节 //读
3.释放索引节点的i_sem信号量 //我读完了
4.唤醒管道中所有的写者进程 //你来写吧
5.返回 已经拷贝的字节数目 //读了这么多
1.获取索引节点的i_sem信号量 //我要写了
2.检查是否至少有一个读进程, //有没有人正在读啊
如果不是,向当前进程发送 SIGPIPE信号,释放i_sem信号量 ,并返回-EPIPE
3.判断是否有足够的写空间, //满不满啊?
是,则向缓冲区 拷贝数据。如果不是非阻塞,释放索引节点并返回—EAGAIN; 如果不是且阻塞, 将当前写操作放入等待队列,释放信号量 ,调用schedule(),一旦被唤醒,返回 3 操作。
4.写入 所有请求的字节 //不满就写
5.释放索引节点信号量 //我写完了
6.唤醒所有等待队列的读进程 //快来读吧