从0开始,用Go实现Lexer和Parser
前言
在 2019年第五届 Gopher China 大会上,来自英语流利说的何源进行了题为《从0开始用Go实现Lexer和Parser》的演讲。主要介绍了如何用 Go 实现 Lexer & Parser,主要涵盖 Go Channel、Goroutine、 Lexical、Scanning、AST 等方面的内容,并概述 DSL 的实践经验,希望通过该分享,让大家了解自己实现 Lexer & Parser 并非难事。
以下为演讲实录。
No.0
背景
懂你英语是专属人工智能老师,它是英语流利说在 2016 年推出的一款基于 AI 的英语学习软件。由于它是一个语言学习或教育类的软件,在后面需要内容的支撑,因此需要有 CMS (Content Managment System) 系统,用于录入各种各样的题目。系统下会有各种选项,大家可以想象一下,当时基于这个界面上我们想录10万道题大概是什么体验。
No.1
挑战
2016 年我们刚开始推出这个东西(懂你英语 ), 当时的环境是一方面我们的产品在 MVP 阶段,变化非常快;另一方面课程内容复杂,Debug 流程非常长;并且表单录入大量内容的效率非常低下。
还有一点就是产品中的题目内容需要经常变化。我们经常需要通过用户的反馈和数据来改动这些内容,从而进行快速迭代产品,要做到这样需要版本控制(version control)和 rollback。
教研课程开发也需要一些比较成熟的工具支持,毕竟在2015、2016年的时候英语流利说还是个创业公司,公司里面的工具其实没有那么成熟,跟百度、阿里相比还是有一点差距的。
那么,没有什么问题是工程师不能解决的,如果有,那就2个工程师,加一个前端一个后端。我们是怎么把它解决呢?一般把大象放冰箱需要3步,同理在开始之前我想说一下有哪些可以走,我们希望达成怎样的目的。
第一,网页结构上要灵活,我们不再受限于 Form 表单框来说明题型是怎样的,但也要带有一定的约束,不能说直接让教研的同学随便给一个文档过来 Parse。
第二,在内容发布之前需要引入 CI 检查机制。大家不在教育行业的话,不知道内容生产者对于字符集、不同的输入法全角切换有多糟糕,80%用手机的人输入时对全角、半角没怎么注意,所以我们需要在这地方引入 CI 检查和强制校验。
第三是使用标记语言代替表单录入,如 md 语言,减轻前端工程师的工作量。我们也教会教研用 git 来管理内容,写代码和写课程内容的人都是文字工作者,但是可能写代码的思维能力较强一点。
最后形成录入流程自动化,我们现在录入课程的过程是从 git push 完之后是走 CI ,打个 tag 后再 deploy。
我们最终形成的就是这样的一个界面,由于其他原因,前面的 preview 没有做太多的优化,大家可以多关注右边内容的界面。我们在 atom 里面做最基本的语法高亮,通过 Parser 可以实时的 preview 之后走发布流程,提高了很多的效率。
提到 git,大家可以先看一下这个图,大概意思就是这个 git 怎么用。我们教研的妹子也就会问工程师类似的问题。

对于后端来说,就是把一些内容进行抽象化处理,大部分时间做的事情就是把一种格式转成另一种格式,而这就是 Lexer 和 Parser 做的事情。既然确定了目标,我们就准备加油干。

No.2
三步走
第一步:写一个 Lexer 将教研写的文件变成语法树来方便解析词法;
第二步:写一个 Parser,将 course 的文件转化成 pb(Protocol Buffer) 文件;
第三步:把 Lexer 和 Parser 串起来。
定义格式
我们第一步先定义格式,这里可以简单说一下不同的几种格式类型。
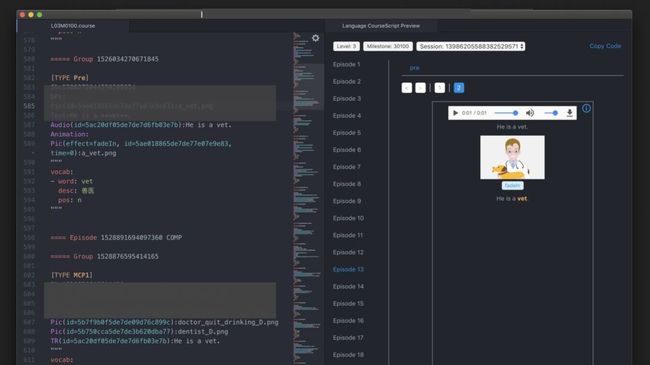
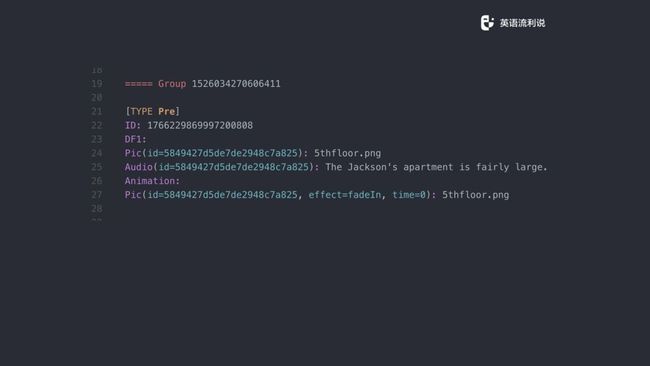
这是我们一个典型 Activity 的格式,上面有一个 Group,是所谓的层次结构,我们可以简单地忽略。下面的 Type 开始从 21 行和 27 行是主要内容,前面有一个 ID,DF1 是固定的显示模式,还有 Pic 、Audio 和 Animation,后面对应的是属性和内容。刚开始这个 ID 是没有填充的,后面会自动填充。
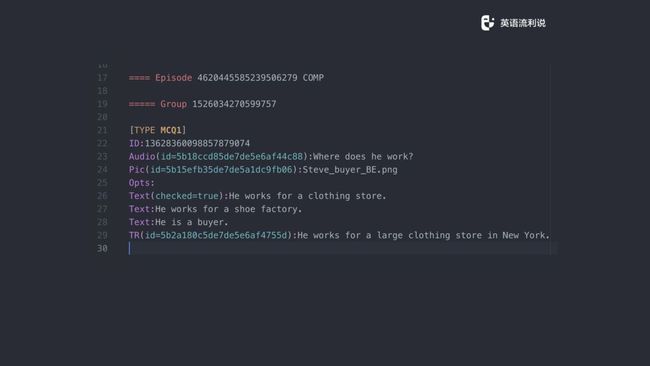
我们再看另一个,跟前面一样,不同的题型固定不变的都是 Type,然后 ID,再到后面的 Audio 等等,还有大家可以看这里引入了具体的 Opts 。所以其实也是主要分为三个部分,Title 一部分,第二 ID、Audio等等是一部分,然后是后面 Attributes,这个是它的属性,最后是内容,基本上就这么几部分。
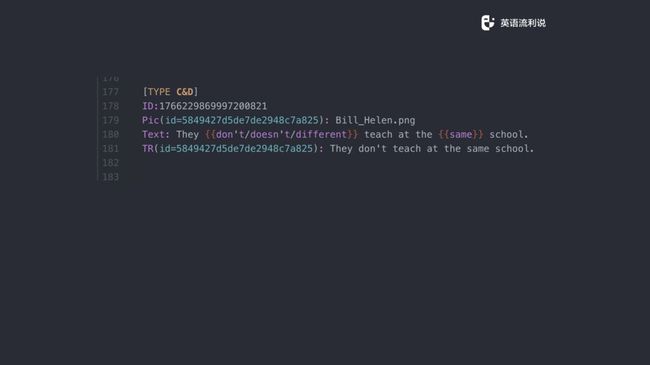
然后这是另一个题型,我们引入一些新的东西。我们需要在一些句子里面有多个选项,我们想表示它有多少词可选,然后采取了这样的写法,实际上在设计过程中我们想了很多东西。最终看上去大概就是这样的一个模式,type、id,这边还有一些行内的选项。
定义语法
我们知道了要做成什么样的格式之后,就开始定义语法。定义语法之前,我们需要知道语法和原语言是有很多标记的,我们选了其中一种语法范式--扩展巴科斯-瑙尔范式(EBNF, Extended Backus–Naur Form)来作为符号表示的方法。写出来大概是这个样子。

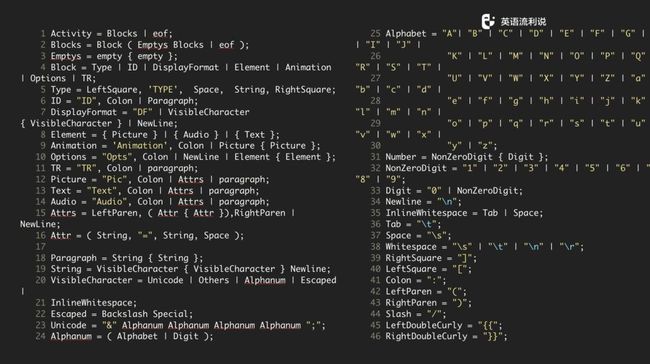
No.3
实现
如果你在公司里只有一两个人看得懂这个东西,那说明这个方案可能不是一个很好的方案,既然这样,我们需要想一下有哪些合理的实现方式?这里列出三种方式:
用 goyacc 工具,它就是一个黑盒子,你完全不知道里面发生什么,也不知道怎么改。
既然是一个简单的语法解析,那正则表达式也是一个可选项
Use states, actions, and a switch statement。
我现在说一下如果使用现有工具所带来的问题。第一个是很难 debug,但 debug 往往非常重要的。如果给你这样一个东西让你跑,你甚至不知道后面写了什么,就会很没有信心继续写下去。第二,你可能要多学一种语言,你搞懂这种语言大概也需要花蛮久的时间。实现出来之后,有可能性能不及预期,因为你不知道里面发生什么,优化比较难做。而且用工具实现不适合 MVP 产品迭代,如果你从底层开始一直写下去的话,你才会知道在哪个地方改和优化。

如果用正则,这里有一个问题,也是经典的名句:“有些人认为有些东西可以用正则来解决,这时候就是两个问题了”。首先正则本身就是一个问题。不到万不得已还是建议大家不要用正则,如果用正则,一定是要直接写在启动的时候的。

然后如果我们用 Golang 的思维解决这个问题的话应该要怎么做呢?Golang 可以很方便的做一些前后端解耦、并发的事情,我们先把这个问题留在这里,大家可以带着这个问题去看一下后面的思路怎么解决。
对于我们这个产品来讲就是这几种,前面是 Keyword,像 type、id 可以认为都是 keyword,后面是 Content,Content 可以是任意的文本或者是 string 都可以,后面还会有一些特殊标记,这个特殊标记是特殊解析的。还有 Attributes,属性会有多个或者有多组。再用 Golang 的方式想的话,其实这样的一个文本就是一长串的 char 组成的 string。

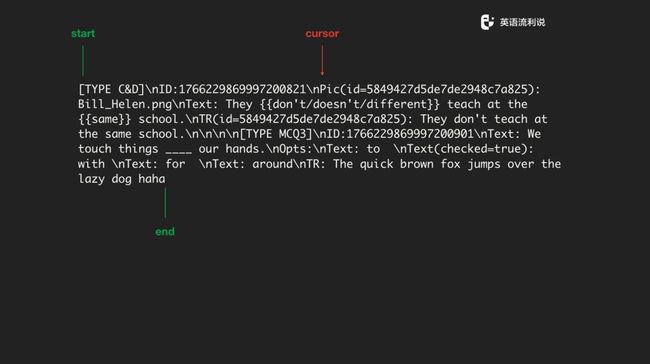
我们 parse 一段文本的时候,就用 start 和 end 标记一个开始与结束,然后在中间放一个光标来回左右移。大家知道 string 底层是一个 slice ,通过下标的来回移动读取字符,所以只用读一遍文本,后面操作上基本上都可以解决。
No.4
state machine
其实再仔细一想这就是状态机。为什么是状态机?比如说拿到一个 type,这是一个 state 或者说是一个 keyword,判断为需要进入的一个状态,然后就执行一种 action 来处理,一但遇到了右方括号就作为结尾标记,就把这段文本作为一整段交给后面的 state 进行处理。
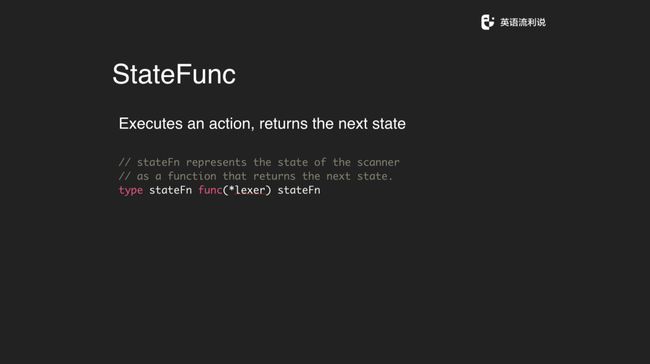
如果是 state machine 的话,我们就需要定义一个 statefunc 的方法。它就是 Executes an action, returns the next state,传递一个 lexer 进去函数之后再定义下一步怎么做。我们拿到这个 state 之后就直接 run 就好了,让它 run 到结束。比如说从文件开头一直跑,跑到最后这个 state 是空的,然后就执行 lexer 进去赋值,还蛮简单的。

No.5
token item
前面说了一些 keyword,如 type、id 的关键词,那我们就先定义 token,token 就两个字段,一个是 typ 还有它存的 val。这里的 typ 就是 itemType,如前面展示的一段文本里的 “Type” 本身就是一个 typ,ID 也是一个 typ。我们也保存一下 token item 的位置和行,这更多的是为了方便输出错误,注意这个 pos 不是在一段文本行里的位置而是在整个文本里面的位置。
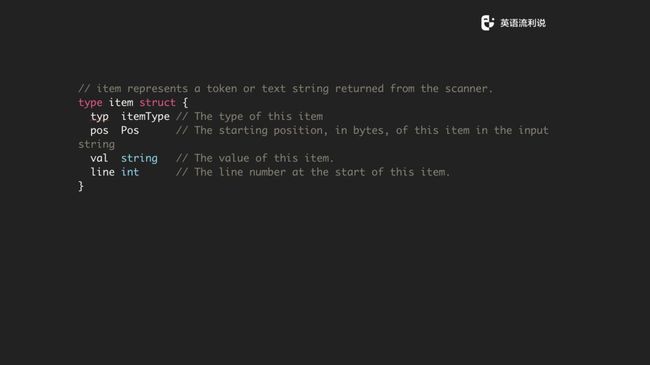
定义了一堆的常量,比如说 Error 是常见的,还有左括号、右括号,这些都是用于解析的。这个我没有全部写出来。

这里有一个技巧,当定义 item 的时候需要插入一些特殊空格符号,比如说我们需要在 itemComma 下面,定义一个 itemKeyword。然后在 keyword start 和 end 的时候,通过这个常量,在以后 parse 的时候很容易判断你的 keyword 在哪个区间。大于多少是所有的 keyword,小于多少也是所有的keyword。这里因为它太长了所以我没有写出来,这是一个小技巧。
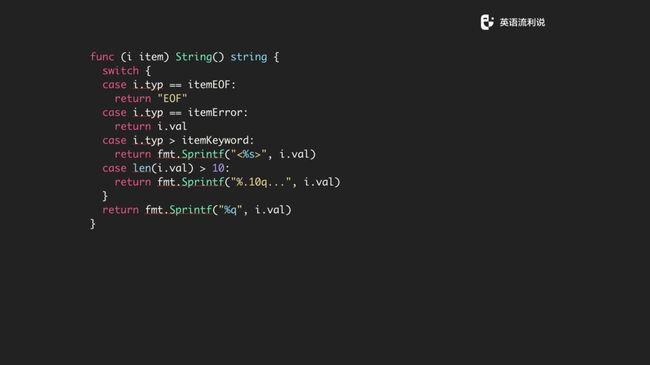
你也想把它打印出来大概是这样子的,实现一个 string 的方法,拿具体的一个例子来讲,比如大家可以看到这里有一个 itemkeyword,如果是item 的 typ 大于这个就当成 keyword 处理这么打印,如果大于10就截掉,最后如果都没有前面的状态,我们就直接打印出它就好了。
No.6
lexer
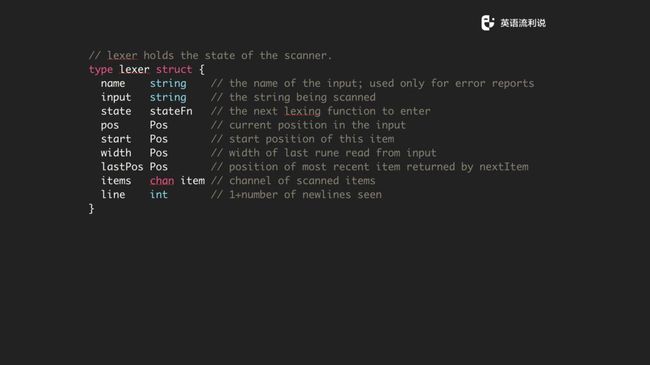
我们接下来讲 lexer 是怎么处理。Lexer 很简单,它有 input、state func,然后一些位置信息,最后一个 items 是需要注意的,因为它是一个 channel。它的处理思路是当 scan 完所有内容后,会将所有内容放到 channel 中,再交给 parser 进行处理。Lexer 会有一个方法创建一个 lexer,然后它其实做的是 init,把具体的参数和内容给你然后直接 l.run。
run 是怎么做的?就是直接跑。所有文件是有一个 top 的关键词,是我们拿到的第一个关键词,拿到之后就直接跑,直到 state 为 nil 后,就把 channel 关闭,整个流程就结束了。


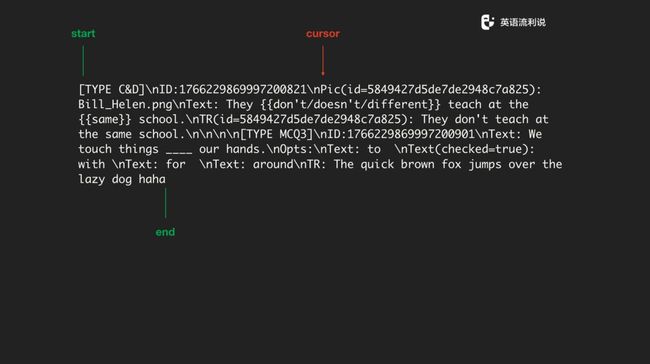
还是以上面的这段文本为例,我们从 type 开始一直 scan ,然后一个 token、一个 token 地做分析,分析完之后我们去建一个 lexer,然后塞到 channel 里面,每一个 run 一遍,这些基本上就 OK 了。
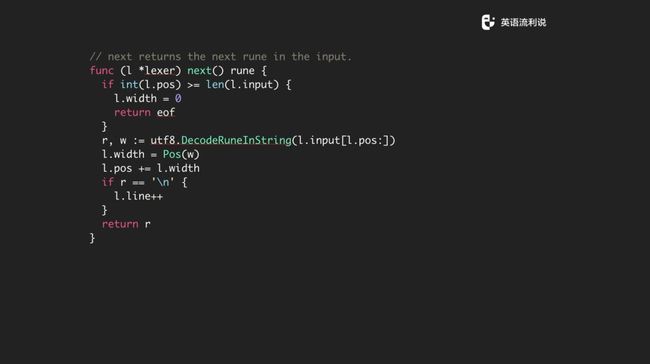
当然有一些辅助的函数帮助你,比如说你移动光标下一个是什么,然后把行数加一下,把位置标记一下,把所有的信息传到下一个 state 里面。
我们还会有一些函数,比如 peek,peek 意思是说我拿到下一个但是我不消费下一个。还有 backup,经常有一个情况是你走着走着有一个结尾标记,这意味着我在下一个结束的时候需要把这个位置重置往前走。current 是当前位置的一个信息,这也很简单。
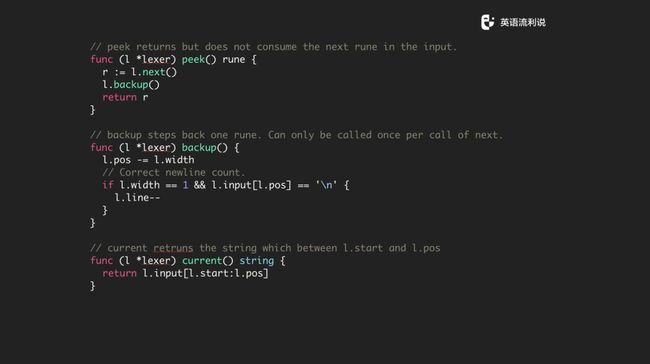
还有 ignore 和 skip 方法,具体的作用看代码也很容易明白。
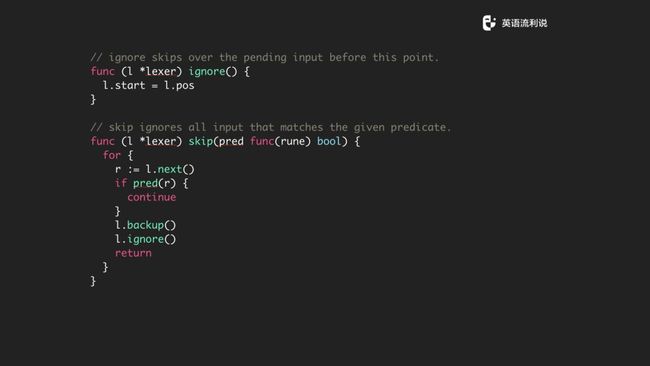
最后还有 emit 这个函数,还是比较重要的。在 emit 数据的时候,经过了一系列的处理,里面的 t、l.start、l.current()、l.line 其实组成了一个 item ,然后放到 items 这个 channel 里面,这个就是大部分的去 lexer 的过程。


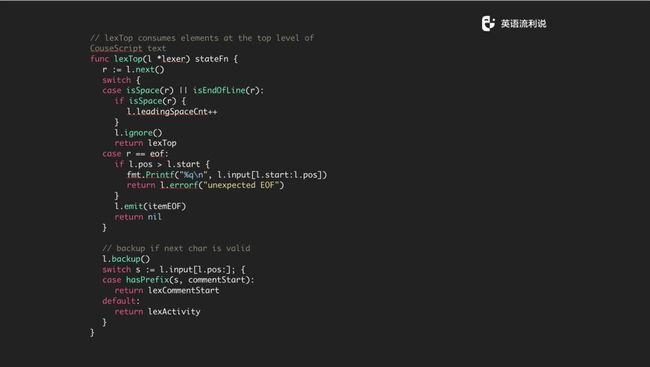
这里再多说一下,把 l.run 来说一下,这个也很简单,拿到第一个 stateFn 一直跑,一直跑到结束。
我们做了一个最前面的判断,我们可能会遇到第一行是个 comment,或者是 Activity,这里做的就是先拿到第一个行,然后判断是不是一个 Space 还是最后一个行,如果不是则忽略掉,然后返回去执行 lexTop。top 指的是最上面一直解析下来的过程,如果下面我们拿到的是符合条件的话,我们要么是执行 lexCommentStart,要么是执行 lexActivity。
然后关于 comment 和 activity 也是很简单。支持两个斜杠是 comment ,把 text 放到 emit 函数里面。再看 activity,如果是 keyword,再看看是不是前面列出来的那行 keyword item 再往后导是否为 letter,最后回到 lexContent 继续处理,下面的步骤也是如此。
如果这些都不符合,那我们认为它是比较 top 的文件或者最上面的再回到前面去,这实际上在一整串的 string 就是来回导然后合理地解析。
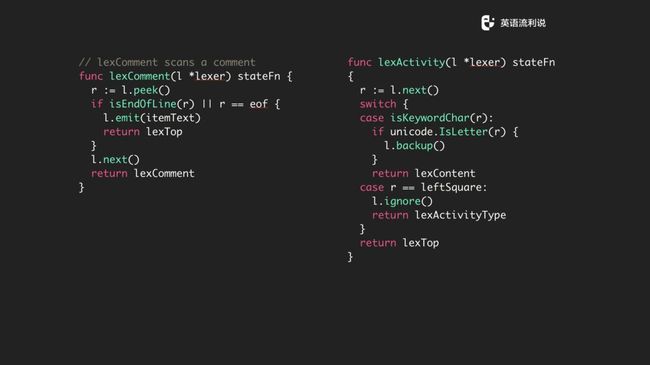
下面是关于一下 keyword 的判断函数,比如是否为 keyword,是否出现在句首等等。
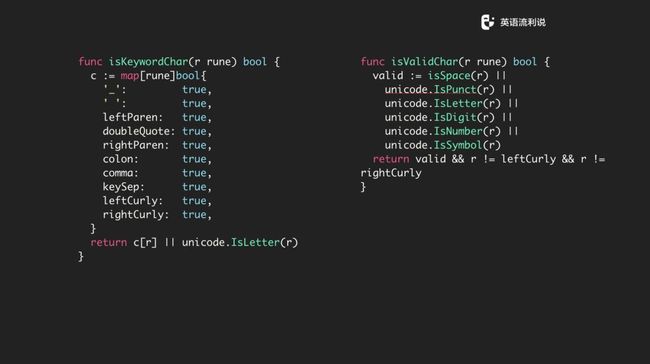
写 lexer 的时候,也需要写一个 debug 函数,可以把当前的信息打出来,当前的名字、行号以及格式是什么样都可以自己传。

当然还有 errorf,你可以把当前解析到的当成一个 error,你如果解析的时候发现了一个 error,那可以先把它当成一个 item,而不是马上中断解析。因为你可以并发解析很多文件,这时候你可以暂时忽略这部分的 error,继续往下传,直到解析完后再进行 error 处理。

lexer 基本上就是这样子的,总结一下,我们去 scan 一个 text 文本,将内容传到 channel,channel 里(收集)一个个的 item,然后这个 items 通过一个个 goroutine 去 run (最后)交给 parser 来处理。
No.7
parser
parser 其实也是很简单,核心有两个东西,一个是定义 AST,语法树是怎么组织的,另一个是如果将 Lex item 变成 AST Node,其实就做这两个事情,但是细节的事情还是蛮多的。
先定义一个 node,node 是语法树的节点。我们有很多的 node,不同的 node 代表不同的 item。Node 接口中有 Type 方法,返回对应的 Node 节点。Position 方法则返回节点当前的位置,String 就是节点中存储的文本,主要用于校验和获取节点对应的文本。
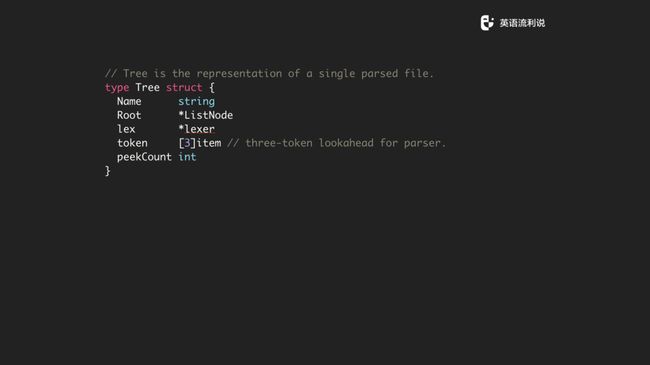
最重要的是这是一颗树,每个 node 里面有一个对树的引用,整个文件就是一个树。

树的结构也很简单,因为我们是支持多个文件去解析,所以是一个 list node,还有持一个 lexer 对象和 token。可以看到 token 是三个 item,选择三个的原因是需要我们需要知道当前、上一个和下一个来作为一个 context 上下文来帮助 parser 进行解析处理,当然你可以留更多。还有一个是 peekCount,你需要知道整个过程 peek 多少次,更多的是用于性能优化。
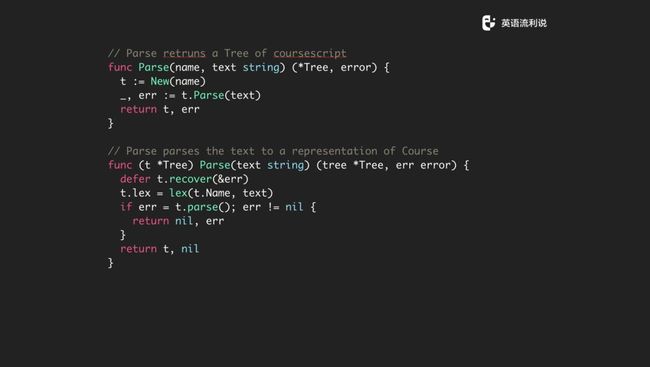
我们就开始 Parse,给一个 text 文本,返回一颗树,在这个树上实现 Parse 的方法,基本上也就是调 lex 方法,对 lex 进行处理,然后再调用外面 parse 的方法,看看有没有 error,如果有就返回,如果没有就这样。
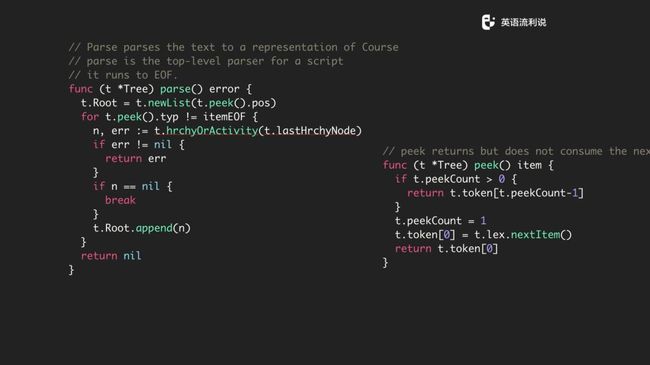
下面 tree 的 parser 方法也是这样,先通过 peek 方法建一个 list 去迭代,如果碰到 itemEof,说明文件处理结束了。中间还有一个 hrchyOrActivity 方法,用于区分层级,可以理解为不同层级的节点,一级一级往下走。走完之后我们得到一个大的数组,最终 append 到 t.Root 中。
这里可以看下 activity 方法,在调用时会传一个 parent 过来,是因为每一个 activityNode 都归属于某一个 HrchyNode,对于整个文件来说是单独存在的,如果只有单个 activityNode ,那 parent 为空也是没有什么问题的。
我们先定义一下 activityNode,跟前面的套路一样的,调用 t.Next() 会返回下一个 item,这里大家可以看到有一行是 item.type 是不是小于 keyword 或者等于 eof 的判断,直到等于 itemkType 的时候,你再执行 expect 方法,然后继续执行判断操作。
在 expect 方法执行完后,会得到一个 item,这时候调用 newActivity 方法将一些信息传进去,最后 return t.parseResource,获得一个有对应信息的 activityNode,而 parseResource 方法就是将 activity 转化为 Node。

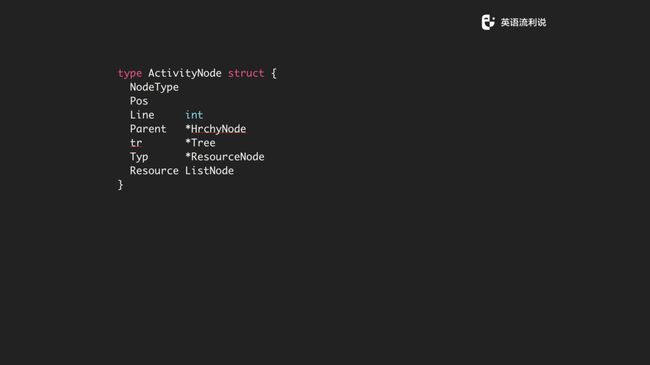
activity node 是这样定义的,它的主要参数是 HrchyNode、Tree、ResourceNode、 ListNode。
上面说到的 expect 函数,用于确定传入的 itemType 与目标 type是否一致。下面的 newActivity 方法则是生成一个 ActivityNode 对象,为对象的属性一一赋值。

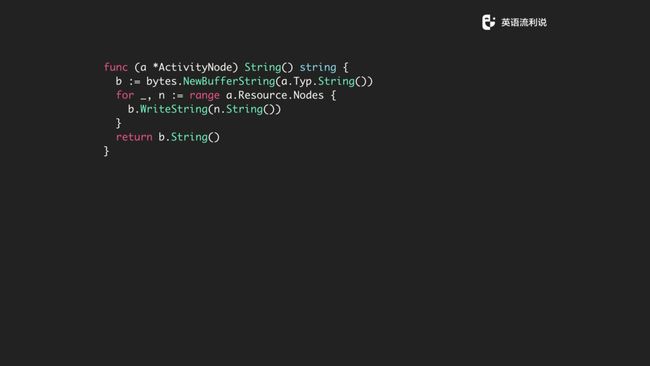
在这里我们也对 ActivityNode 写了一个 String 方法,用来打印该节点的信息,这里用到 StringBuffer 提高一些字符串拼接的效率。
No.8
testing
最后一个问题就是测试,大家可能想当我们写一个 Lexer、Parser 的时候,从这儿看很简单,其实细节的工作非常多,(确保这些细节的部分没问题的) 关键在于我们怎么样写测试。我们当时的思路有两个,其中一个是针对每一条规则写测试,然后针对每个文件,不同的样例文件写测试。我们分为三个部分,一个是 Lexer、一个 Parser,还有整个文件的测试。
lexer
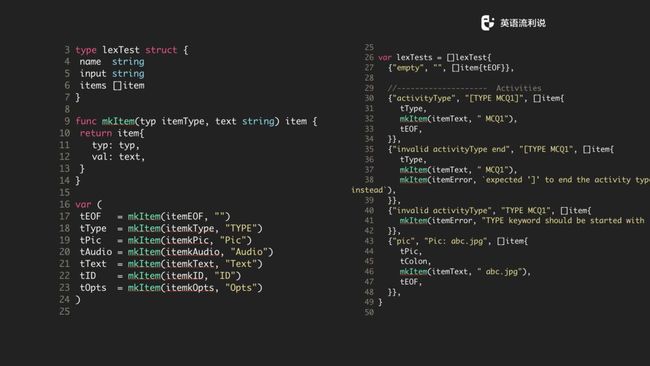
Lexer 测试是比较简单的,比如说我们在测试的时候,传递 name、input、items,再给一段 string 文本,看看是否解析到想要的格式和item。
在测试的时候,我们通过一些辅助方法,比如说 mkItem,collect 方法来做这些事情。再来说一下右边的测试用例。
比如说第一个 “Type MCQ1” 我们是怎么解析的,预期里它完成解析分三个 item ,type 这个字段我们是需要的。还有一个是 itemText 叫MCQ1,还有一个是 eof,最后一个是 eof 是因为本来 input 文本就是这么短的一段,所以它的解析的最后肯定是 eof。
比如说下一个 MCQ1,如果没有结尾的话,这时候是应该报错的,会报一个 "expected '[' ..." 告诉你说是 error。我们通过这一条条规则进行验证,如果这些规则都能验证通过,那将一整个由规则合起来的文本放到 channel 来处理一般来说也不会有什么问题。
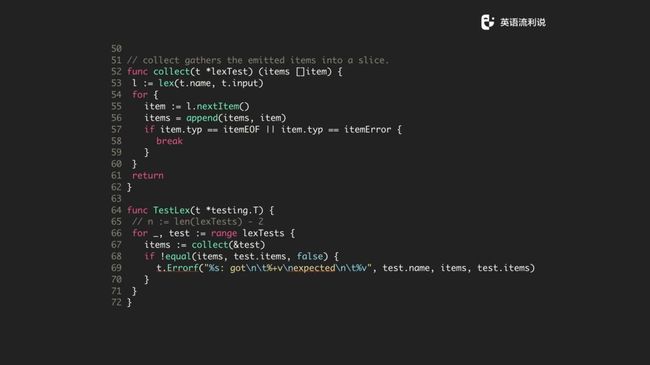
当然,我们也做了一些简单的封装,比如说 collect 直接把 text 封装成一个一个的 item,然后 append 到 items,通过 nextItem 方法去找到下一个 item,知道 item 为 eof 或者 error。
parser
Parser 的测试其实思路也差不多,总的来说就是我们传递一个 input 进去,看能不能成功地 parse 返回。parse 之后的结果是不是我们想要的格式和 AST。
其实 AST 在底层是一个相对比较复杂的东西,所以我们在测试的时候,采用了一种不太严谨的方法,但从目前的效果来看,还是有效的。可以看下面我标红的地方,思路就是我们通过编写的 String 方法,将节点信息打印出来,再与我们输入的文本做对比,看 parse 的结果是否一致,如果不一致则表示 parse 的过程中是存在问题的。
我们还会有一些示例文件来去做测试,比如说会把当前大概 100 多个题型全部放在文件里面或者不同的业务会分多个文件去跑 CI 测试,由于这是内部的东西,所以不好放出来给大家看,所以我们基本上跑三个测试,一个是Lexer 测试,Parser 的测试,还有是整个文件的测试。
总结
这就是前面的 Lexer 和 Parser 怎么样去写的一个过程。第一个是 state Machine,读取整个文本作为一个 string,然后通过 lexer 处理成多个 string,再封装成 item 放到 channel 里进行处理。这个 channel 再去解析,解析完之后再转成一个 AST 树。
结论是在整个过程中,写起来还是比较有意思的。通过 Golang,可以将 lexer 和 parser 的工作进行解耦的同时,也可以进行并发处理。其中还用到了 channel 进行数据交互,在 channel 中取数据时可以确保数据的有序性。其实整个过程上并没什么太难的东西,更多的是很细节的东西需要我们去处理。
Go很棒,这是无所质疑的,但是我想要说的是,如果是万不得已不要自己写 parser,因为需要注意的 case 很多,你也需要去想业务场景以及通过测试来保证解析过程的正确性。我们其实在里面加了一些方法,比如说把树的结构打印出来,保证测试覆盖度等等,降低编写 parser 的难度。但是如果从头开始写,比如尝试写一个 sql 的解释器,在开始的时候还是要费一点头发的。
所以说非万不得已,不要自己写 Parser,因为很多的业务场景有些方案可以解决。现在我们写完之后,对我们来说(带来的好处)是显而易见的,我们可以支持上百道题型,只要有内容就可以很好的录入,通过 git 等工具来优化整个自动化流程,对教研的产出和质量是完全有品控的。
Q & A
提问:我想问一下你们给教研设计用来录用文本的特点,它能支持嵌套结构或者是整个目录吗?
何源:我这里主要讲的 activity,我们本身是支持嵌套层级,而且是任意嵌套层级。我可以给两个建议,第一个建议不要用嵌套 JSON,因为 JSON 是没有 schema 校验的,不同语言表现是不一样的。
提问:你这个是属于素材是吗?
何源:我们校验后的素材可能是图片、文本、音频,我们最后是把图片、文本组织起来。
提问:组织起来的话会有多少章节。
何源:这就是我跟你说的层级结构,你的层级结构是通过定义好的模式。我们稍后再探讨一下。
重磅活动预告
Gopher Meetup 广州站即将开启。来自小鹏汽车、腾讯、早安科技、PingCAP的大咖讲师带来 Go 开发领域的一线实践经验分享,尽在10月26日,小鹏汽车总部销售展厅!
报名请戳:阅读原文

Go中国
扫码关注
国内最具规模和生命力的 Go 开发者社区