<
大名鼎鼎的AlexNet,2012年ImageNet比赛的冠军,可以说是近年深度学习浪潮的开山之作,发表在了2012年的NIPS上.
作者Alex Krizhevsky,也是Hinton大佬的学生
ImageNet Classification with Deep Convolutional Neural Networks
Abstract
- 性能: 在包含1000个类别,120万张图片的ImageNet LSVRC-2010训练了一个神经网络,在test data上达到了SOTA的效果,top-1, top-5 error达到了37.5%, 17%
- 网络结构:包含5个卷积层(部分包含max-pooling),3个全连接层,最后接一个1000类的softmax做归一化.
- 其他细节贡献:
- 实现了convolution的GPU版本
- 在全连接层使用了Dropout来避免overfitting.
Introduction
更大的数据集,更强的学习能力的模型
为什么要更大的数据集?
现在主流识别任务的方法都是基于machine-learning的,要提升这类方法的性能,需要很大的数据集,学到更强表达能力的模型,并且使用一些更好的技术去避免模型的Overfitting(机器学习绕不开的问题)
现有的数据集都很小,在这种小的数据集上,比如Mnist手写数字识别任务,模型得到的结果甚至已经比人还好。但是真实世界的场景远比这复杂,因此我们需要更大的数据集(对数据集大小提出要求),比如ImageNet。
为什么要更强学习能力的模型 - 为什么选择CNN?
即使是有了ImageNet这样庞大的数据集,识别任务也不可能被完全的解决,模型同样需要有一些很强的先验知识来补充数据当中没有的东西(对模型的选择提出了更高的要求)
-
Convolutional neural networks的优势
- 容量可调 : 可以通过修改网络的Depth, breadth来调整网络的大小(学习能力)
- 对自然图像有准确的先验假定 : stationarity of statistics and locality of pixel dependencies(统计上的平稳性和像素依赖的位置性)
- 和类似结构的feedforward网络相比,CNN有更少的链接和参数,可以更好的学习,又不会损失太多的性能
因此CNN其实有吸引人的特点,Convolution这种Local的结构也非常的高效
GPU版本的Convolution实现让CNN训练加快,ImageNet标注数据的出现让模型避免了过度的Overfitting
Contributions
- 在ILSVRC-2010,ILSVRC-2012比赛中,利用相应的ImageNet的子集训练了一个CNN网络获得了冠军。
- 完成了Convolution,其他层的GPU版本实现,并训练了一个神经网络。
- 网络包含一些小的Feature,能提升训练速度和性能
- 即使是在这么大的数据集上,我们的网络参数量也有可能会Overfitting,因此采用了一些技术来避免Overfitting
- 提出了一个5卷积-3全连接的CNN网络,表示卷积层不能少,少了性能会降
作者也解释了一下网络模型和训练受限于GPU的发展,有更好的GPU可以加快训练(这是不是也是没尝试更深的网络的原因呢?)
ImageNet Dataset
介绍了以下ImageNet和ILSVRC比赛,没啥好说的。
主要关注以下网络数据输入的预处理
数据预处理
图像Resize
ImageNet的图像是不同分辨率的,而AlexNet只能接收固定大小的图像(因为全连接层的参数直接和输入数据量相关)
因此需要对图片进行预处理,做法是downsample到固定256*256的大小
具体的Downsample做法:
给定一张图像,按短边resize到256的比例resize整个图像,然后crop这张图像中心的256*256的patch.
去均值
没啥好说的,会计算所有像素的RGB均值,做去均值的操作,输入数据就是原始的RGB值
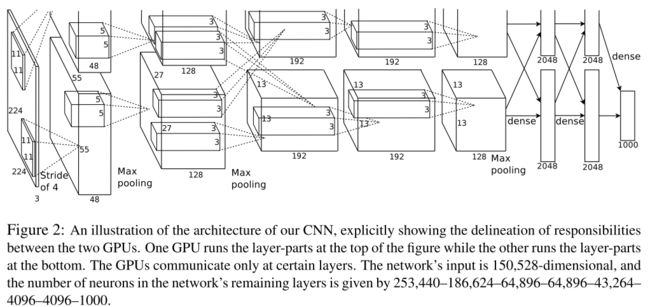
Netwotrk Architecture
整体网络结构包含5 conv + 3 fc层,网络结构如下图:
Noval Features to improve performance
作者也提出了一些新的点去帮助加快训练,提升性能
ReLU Nonlinearity
第一个最重要的也就是ReLU激活函数,如下
传统的激活函数tanh和sigmoid,作为软饱和的激活函数,一旦落入饱和区,梯度更新会趋向于0,导致梯度消失,变得很难训练。
而ReLU作为一种在负半轴抑制,正半轴是线性的激活函数,这种结构表达了非线性的筛选能力,又能解决梯度消失的问题,是一种比较好的选择(也有问题,神经元死亡)
当然上面这段都是自己加上去的,在这篇文章里作者并没有过多分析,而是直接替换了Relu, 认为在CNN中运用Relu可以加快训练速度。
作者用4层的神经网络在CIFAR-10数据集上训练比较了tanh和Relu分别作为激活函数的训练速度,发现要达到25% train error,Relu激活函数花费更少的时间,如下图:

因此在更大的网络和数据集上,我们应该也可以得到类似的结论,因此作者认为在更复杂的CNN中用Relu替代tanh和sigmoid可以显著加快网络训练。
Training on Multiple GPUs
Multi-GPUs的训练,可以加快速度,属于工程问题,这里不提了。
Local Response Normalization
局部相应归一化层,作者认为做这样的归一化可以提升性能,把top1,top5 error分别降低了1.4%和1.2%
思想就是对于一个卷积层的输出,考虑各个channel通道的每个像素位置,单个channel通道上的每个像素位置的值,根据该像素位置在所有通道上的平方和来做归一化,公式如下:

Overlapping Pooling
Pooling的时候,会有stride,kernel_size两个参数。
如果kernel_size = stride,就是Non-Overlapping的Pooling
如果kernel-size > stride,就是Overlapping的Pooling,Pooling后的图像上,每个像素点与附近的像素点之间是有信息的Overlap的。
作者发现这种Overlapping的Pooling可以增加准确率,top1,top5 error各自降低了0.4%,0.3%个点。
作者认为这种Overlapping的Pooling在训练的时候可以轻微降低Overfitting
Overall Architecture
看一下整个网络结构,这里好像因为分了Multi-GPUs还特地把网络分开来了。。真蛋疼,我们就当做一个网络,统一的参数看
这里结合了一下Caffe版本的具体Code看,会比较清楚:
Alexnet_train_prototxt
- input: 224x224x3的输入图像,前面说预处理是256x256,为什么?其实是因为后面做data augmentation最终得到224x224的图,所以前面的256x256是保证可以做crop,真正的网络输入还是224x224x3
- conv1_relu_lrn_maxpooling: 单个kernel的size=11x11x3,stride=4,kernel数量96个,后面接relu,lrn,和3x3 stride=2的max-pooling.
- conv2_relu_lrn_maxpooling: 单个kernel的size=5x5x96,stride=1,kernel数量256个,后面接relu,lrn,和3x3 stride=2的max-pooling.
- conv3_relu: 单个kernel的size=3x3x256,stride=1,kernel数量384个,后面接relu
- conv4_relu: 单个kernel的size=3x3x384,stride=1,kernel数量384个,后面接relu
- conv5_relu_maxpooling: 单个kernel的size=3x3x384,stride=1,kernel数量256个,后面接relu,和3x3 stride=2的max-pooling
- fc6_4096_relu_dropout:将上一层得到的结果拉成1xn的向量,过全连接层输出1x4096的向量,过relu,训练时候过ratio=0.5的dropout
- fc7_4096_relu_dropout:同理,过全连接层输出1x4096的向量,过relu,训练时候过ratio=0.5的dropout
- fc8_1000:过全连接输出1x1000的向量,再过softmax就可以得到归一化的1x1000的向量,每个点代表属于对应label的概率。一般实现的时候train把softmax和交叉熵损失函数放在一起,test的时候用softmax得到归一化概率。
可以看到网络结构如果抛开那些细节的话,就是11x11,5x5,3x3,3x3,4x4卷积,4096全连接,4096全连接,1000分类概率。
以现在的眼光看,对于图像级的分类问题,不太好的地方在哪里呢?
主要是前面的卷积层有优化的地方,我们一般叫做CNN特征提取层,AlexNet这样5层的CNN特征提取,能提取出较好地对于图像分类问题的feature吗?
对于分类问题,最后用全连接可以考虑全局的信息,但是也破坏了相应的localization的信息,是不是有弊端呢?
Reducing Overfitting
机器学习问题无法避免Overfitting,但是好的模型要尽可能有较好的泛化能力,因此模型如何减缓Overfitting是很重要的一部分。
作者也提出了一些减少Overfitting的办法。
Data Augmentation
数据增广大概是从数据角度我们最常考虑的办法,做法是对原图做一些简单的变化。
这里其实可以有两种做法
- 事先增广好,存在磁盘里:好处是降低训练时候的运算(虽然是在CPU上的),坏处是会增大磁盘的存储量
- 在训练的同时增广:好处是降低了磁盘的存储量,坏处是可能有一些CPU运算的开销。
作者似乎选的是第二种.
增广的方式
随机Crop+水平翻转:在256x256的图像上随机Crop得到224x224的图像,并且得到他水平翻转的图像,这样2048倍增加了数据集的量,不做的话会Overfitting.问题是,这样怎么对256x256的图像做test,作者的做法是提取图像的中心patch+四个角落patch,再做水平翻转,得到一共10个patch分别过网络,得到这些patch预测得到的概率的平均值,最大的平均值对应的类别为图像的分类结果。
-
PCA Jittering:先计算RGB通道的均值和方差,进行归一化,然后在整个训练集上计算协方差矩阵,进行特征分解,得到特征向量和特征值(这里其实就是PCA分解),在分解后的特征空间上对特征值做随机的微小扰动,根据下式计算得到需要对R,G,B扰动的值,把它加回到RGB上去,作者认为这样的做法可以获得自然图像的一些重要属性,把top-1 error又降低了1%
PCA Jittering也算是比较常见的一种Data Augmentation的做法

Dropout
作者认为一种好的避免过拟合的做法是做模型的Ensemble,类似传统机器学习里的做法,但是网络的Ensemble会耗费大量的资源,因此比较好的做法是在训练的时候,在网络内部实现Ensemble。
作者用了他人提到的一种dropout的方法,通过50%的概率随机地在训练的时候将神经元的输出置为0,让他对forward和backward失效。
这样可以使得每次训练的时候,网络都会sample出一个model,但是所有sample出来的model共享一个全局的model。作者认为这种方法可以减少复杂系统下神经元之间的依赖性,因为我们不希望一个神经元依赖于某个特定的神经元。
这样可以强迫网络在后面其他部分的神经元每次都在随机变化的情况下,卷积部分可以学到更加鲁邦的feature
在测试的时候,会打开所有全连接层的神经元,但是会对输出乘0.5,这是取了预测分布的几何平均,是一种比较合理的实现方案。
作者在FC6,FC7用了全连接,显著地降低了Overfitting,但是会使得网络的训练时间增加到两倍。
Details of learning
一些基本的参数
batch_size=128, 用的SGD, momentum给了0.9, weight_decay给了0.0005
参数初始化
所有的层用高斯随机初始化,mean=0, var=0.01
conv2,4,5和fc层的bias初始化为1,这样做加速了网络早起的训练(给了Relu正的输入),其它层的bias初始化为0
学习率调整策略
base_lr给的是0.01,一旦在validation集上不下降了就降低10倍,在结束前最多降低三次。
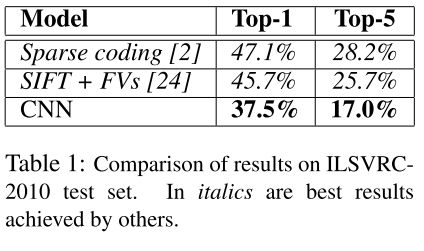
Result
结果没啥好说的,下图是在ILSVRC-2010上的结果,比传统方法都好了,开启了深度学习刷榜的年代。
我的总结
AlexNet作为CNN在图像领域应用,并取得显著成功的开山之作,以现在的眼光来看还是有很多值得借鉴的点。
比如
- Relu作为激活函数解决tanh,sigmoid这些软激活函数落入饱和区会梯度消失的问题,加快训练速度,现在还是最主流的激活函数。
- 提出Dropout在全连接层的时候,在单个网络内部模拟模型的ensemble,降低神经元之间的关联性,加强了耦合度,在降低Overfitting的同时而不增加参数量, 虽然现在因为全卷积网络的出现在一些问题里用的越来越少了。
- 提出了Data Augmentation的方法,random crop, flip, PCA Jittering现在都还是比较主流的做法,都被沿用了下来。
- 像overlapping pooling,是现在网络标准的pooling做法。
- 提出了这样一个conv,relu,maxpooling...conv,relu,maxpooling......fc,fc的分类网络框架,单层看作为局部特征的提取,全局看是一个低维到高维空间的映射,fc做高维信息的整合来做分类,是后面分类网络非常主流的一个框架。
当然也有一些以现在的眼光去看值得改进的地方,
1.比如LRN后来就很少用了。
2.网络结构设计上一些细节处现在也有更好的做法,比如用小kernel替代大的kernel
3.AlexNet整体还是比较浅的,深度网络现在可以越做越深。不知道当时没做深有没有硬件的限制。。
Anyway,深度学习的浪潮因为AlexNet的出现正式到来。