中国裁判文书网爬虫分析
前言
本篇主要分析文书网爬虫思路,仅供个人学习之用,切勿用于任何商业用途。
分析一
中国裁判文书网首页地址:http://wenshu.court.gov.cn/
随便点击一下
搜索,进入:

进入第一个结果:
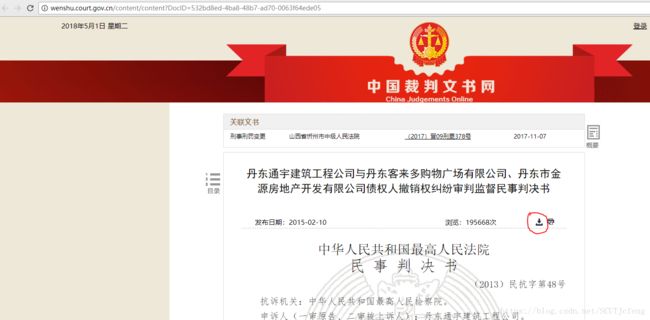
注意圆圈中的
下载按钮,点击下载,一个.docx格式的文档就安安稳稳的躺在你的电脑硬盘上了。

到这里初步分析结束,我们自然就想到了爬虫的内容:

分析二
- 网页地址:http://wenshu.court.gov.cn/content/content?DocID=532bd8ed-4ba8-48b7-ad70-0063f64ede05,从中提取出
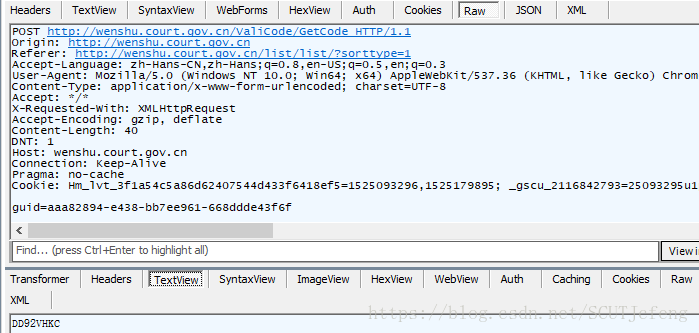
DocID,借助fiddler分析:


- 用到
post方法,post的3个参数DocID已经知道,剩下的htmlStr和htmlName暂时未知,不过很容易就能猜出来,也可以拷贝出来urldecode解码查看具体内容。
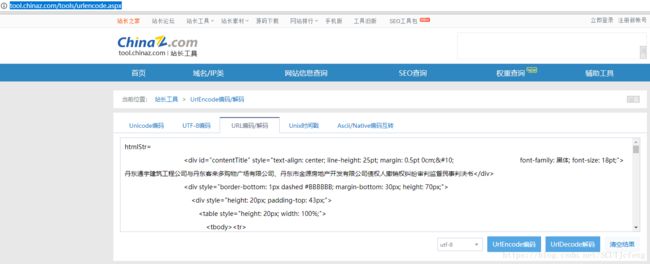
- 但是我们仍然不知道
htmlStr和htmlName的值怎么来的,接下来查看网页源代码,chrome按ctrl + u或者右键-查看网页源代码:
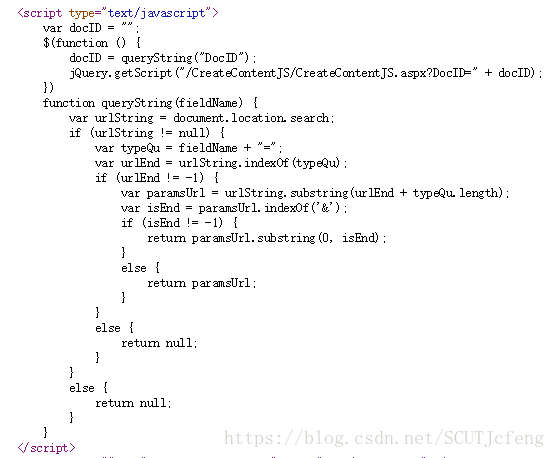
源网页是没有文档内容的,可以知道是异步加载,我们看到这样一段脚本,CreateContentJS,向一个地址请求信息
http://wenshu.court.gov.cn/CreateContentJS/CreateContentJS.aspx?DocID=532bd8ed-4ba8-48b7-ad70-0063f64ede05 ,抓包看看。
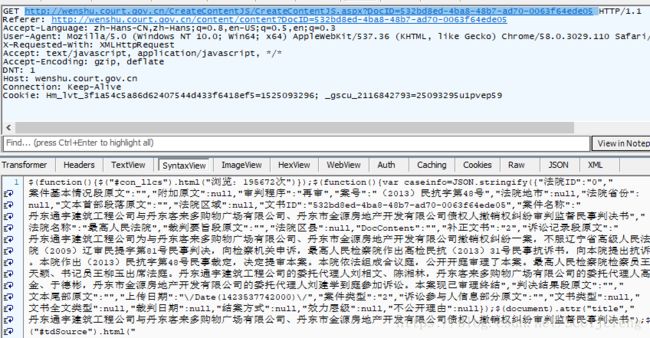
可以看到,请求的结果就包含了htmlStr和htmlName的值。然后,你需要对这串字符串进行处理,处理过程略过不提。 - 接下来要得到批量的
DocID,回到搜索结果中,同样查看网页源代码我们得知DocID也是异步加载,查看抓包结果:
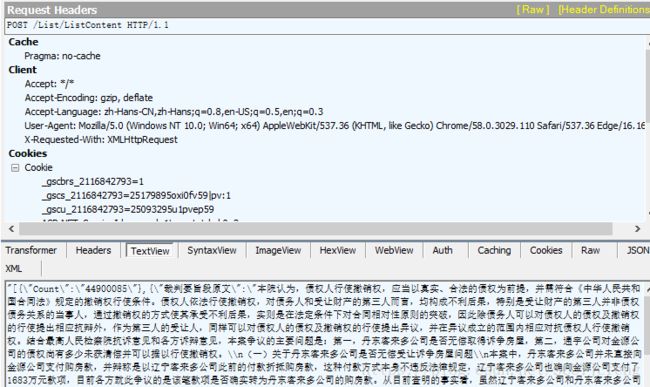
经过处理后,可以得到json数据:

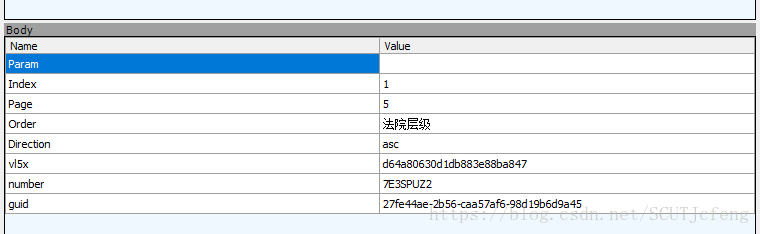
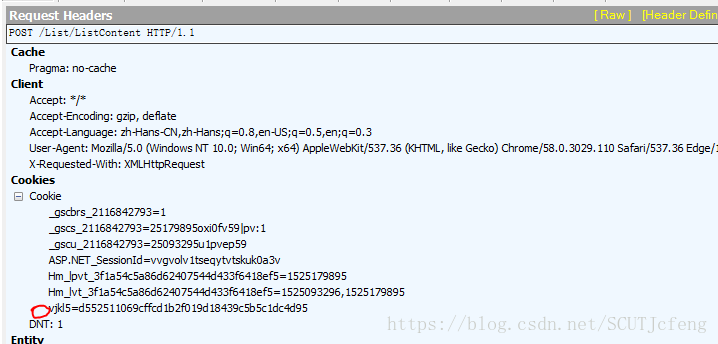
也是post方法,除了webform里的参数,还有cookies里面的vkl5也是不可缺少的参数,最后在讲。webform的参数中,index是页码,page是每页的数据,默认5条,最大20,下面说说vl5x,number和guid怎么来的。 - 先说
guid,由4可以知道,guid是在提交搜索post的过程中出现的,在搜索页源代码中可以看到,guid是通过一个叫createguid的函数生成的。

再看
number,在fiddler中通过抓包搜索number的值,可以看到:
number的值由guid的值可以得到。再看
vl5x,fiddler搜索结果显示在以下js中有出现:
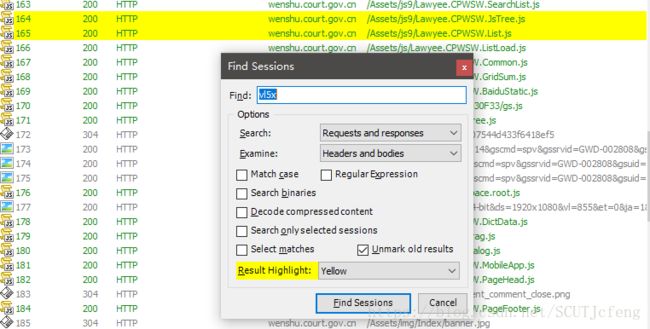
或者我们F12打开源代码,在source,ctrl + shift + f全局搜索vl5x:
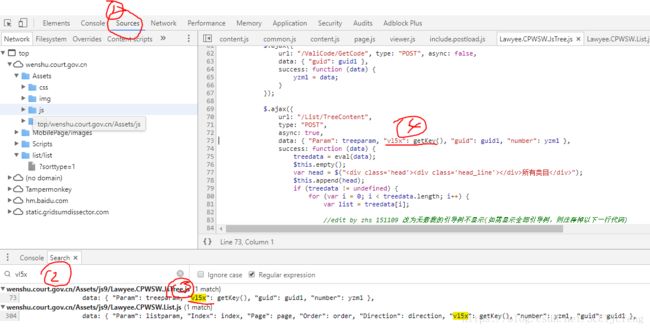
双击第一个结果,可以看到,vl5x是由getkey()方法产生的,继续搜索getkey(),

可以看到getkey()函数很复杂,所以我们需要解密:
第一个eval代入到第一行中,格式如eval(function(p, a, c, k, e, d){...}(...))如下:
eval(function (p, a, c, k, e, d) { e = function (c) { return (c < a ? "" : e(parseInt(c / a))) + ((c = c % a) > 35 ? String.fromCharCode(c + 29) : c.toString(36)) }; if (!''.replace(/^/, String)) { while (c--) d[e(c)] = k[c] || e(c); k = [function (e) { return d[e] } ]; e = function () { return '\\w+' }; c = 1; }; while (c--) if (k[c]) p = p.replace(new RegExp('\\b' + e(c) + '\\b', 'g'), k[c]); return p; }('7 8(2,4,3){5 6=3.9(\'|\');a(5 1=0;1<4;1++){2=2.f(e b(\'\\\\{\'+1+\'\\\\}\',\'c\'),6[1])}d 2}', 16, 16, '|i|str|strReplace|count|var|arrReplace|function|de|split|for|RegExp|g|return|new|replace'.split('|'), 0, {}))得到:
function de(str, count, strReplace) {
var arrReplace = strReplace.split('|');
for (var i = 0; i < count; i++) {
str = str.replace(new RegExp('\\{' + i + '\\}', 'g'), arrReplace[i])
}
return str
}接下来6个eval,代入上面这个de函数中,得到一堆函数,
再加上最后面这个几个:
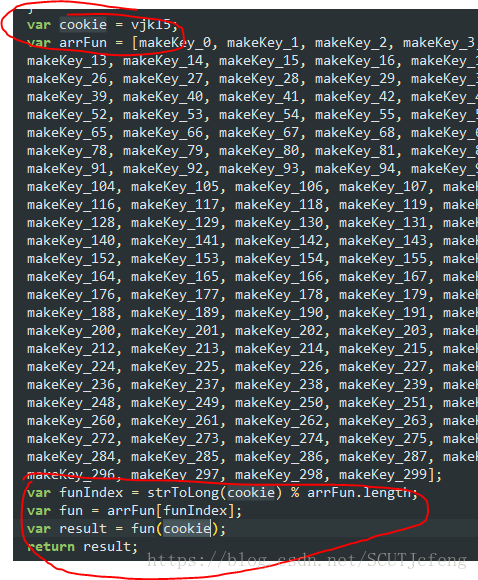
var fun = arrFun[funIndex];
var result = fun(cookie);
return result;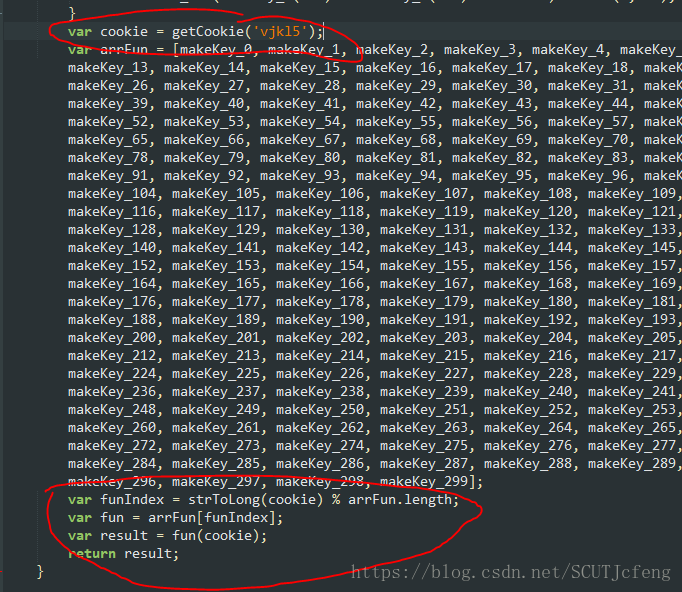
把上述得到的所有函数放到新建的一个文本文件里,可以看到最后面有cookie值,这个值等于vjkl5
vjkl5怎么得到呢,fiddler再次搜索一下,原来在这里:
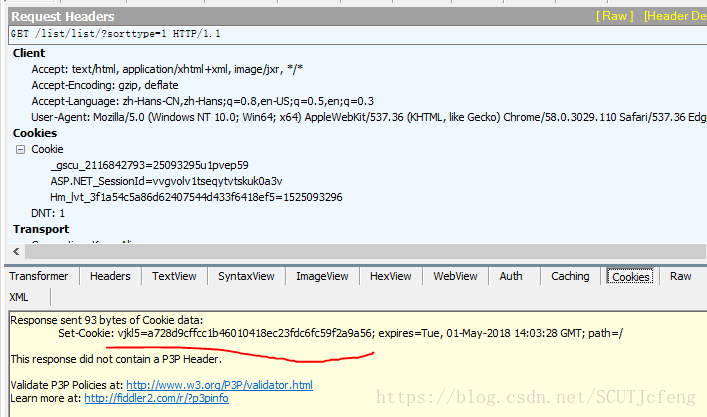
至此,所有参数已经讲解完毕。
回顾
guid
方法:createguid,脚本构造number
方法:post
URL:http://wenshu.court.gov.cn/ValiCode/GetCode
提交参数:guidvjkl5
方法:get
URL:http://wenshu.court.gov.cn/list/list/?sorttype=1
提交参数:None
在cookies找vl5x
方法:js
参数:vjkl5
工具:execjs
注意:将相关函数放到一个新建的js文本中,为了方便执行,我稍微修改了getKey(),增加了一个参数vjkl5,即:
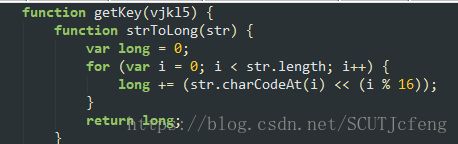
因此,我的call函数可以添加vjkl5参数,以得到vl5x的值。
DocID
方法:post
URL:http://wenshu.court.gov.cn/List/ListContent
提交参数:Param、Index、Page、Order、Direction(前面5个参数很简单)、vl5x、number、guid
提交Cookies:vjkl5
处理:得到的text需要处理成json格式,再提取DocIDhtmlStr和htmlName
方法:get
URL:http://wenshu.court.gov.cn/CreateContentJS/CreateContentJS.aspx
处理:re提取jsonHtmlData,execjs处理eval,返回jsonData,格式为json,Content的构造格式参考抓包得到的htmlStr,url编码后即为htmlStr,title即为htmlName,paperId即为DocID
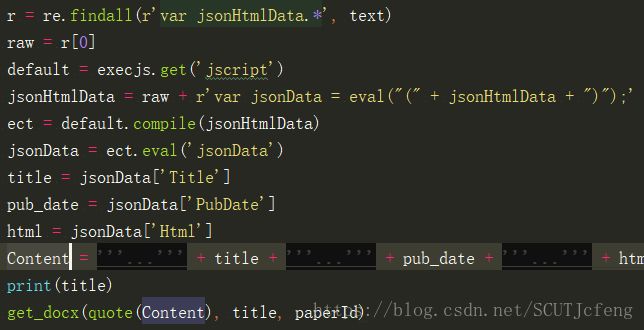
headers其它参数
Content-Type:application/x-www-form-urlencoded(部分请求需要)
User-Agent:只要不是默认就行docx文件
方法:post
URL:http://wenshu.court.gov.cn/Content/GetHtml2Word
下载代码参考:
with requests.post(url, data=data, headers=headers, stream=True) as r:
with open(unquote(unquote(htmlName)) + '.docx', 'wb') as f:
for chunk in tqdm(r.iter_content()):
f.write(chunk)工具:红色字体用到tqdm工具:
Tips:
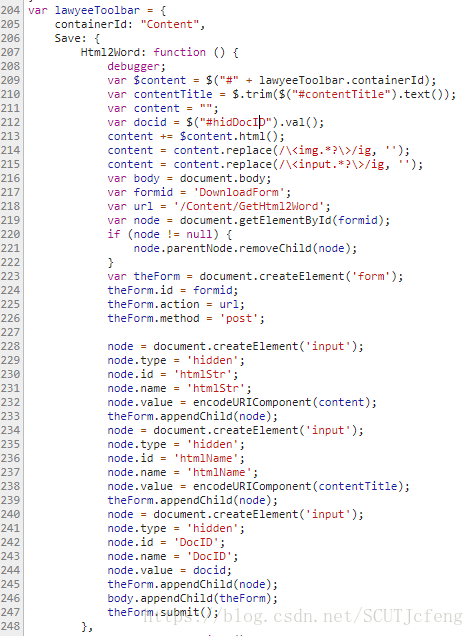
下载文档的按钮带有一个函数,
onclick="lawyeeToolbar.Save.Html2Word();",在Lawyee.CPWSW.Content.js中可以看到相关函数,从中可以看到函数对一些参数的预处理;
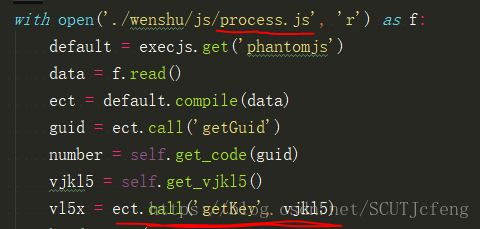
上面提到的我新建的
process.js文件,还包含了md5.js,decode64.js和jQuery.js里的一些函数,可以待程序运行报错缺某某函数的时候再到js源码中拷贝进去;关键词:
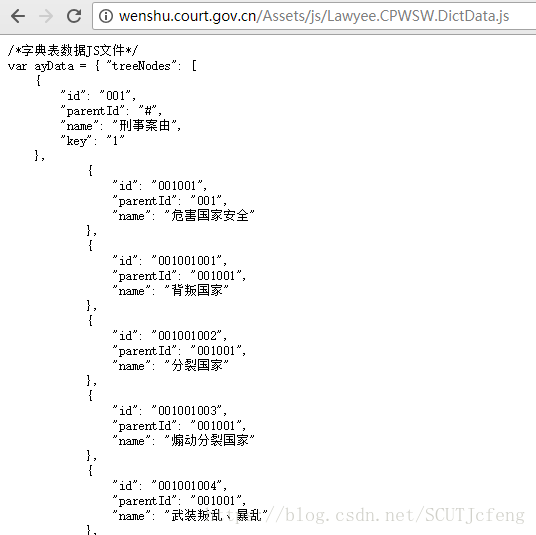
URL:http://wenshu.court.gov.cn/Assets/js/Lawyee.CPWSW.DictData.js
方法:get
提交参数:None
处理:得到的text需要处理成json格式,再提取关键词对应的id
关于
vl5x
形如eval(function(p,a,c,k,e,r){})的函数都是可以解密的。
第一行,格式化后省略{}内的内容:var aaaafun = function(p, a, c, k, e, d) {...}
第二行,省略()的内容:eval(aaaafun(...))
结合,先将第一行改成这样eval(function(p, a, c, k, e, d) {...}(这里暂时空着)),然后
将这里暂时空着替换成第二行...的内容,即变成:
eval(function (p, a, c, k, e, d) { e = function (c) { return (c < a ? "" : e(parseInt(c / a))) + ((c = c % a) > 35 ? String.fromCharCode(c + 29) : c.toString(36)) }; if (!''.replace(/^/, String)) { while (c--) d[e(c)] = k[c] || e(c); k = [function (e) { return d[e] } ]; e = function () { return '\\w+' }; c = 1; }; while (c--) if (k[c]) p = p.replace(new RegExp('\\b' + e(c) + '\\b', 'g'), k[c]); return p; }('7 8(2,4,3){5 6=3.9(\'|\');a(5 1=0;1<4;1++){2=2.f(e b(\'\\\\{\'+1+\'\\\\}\',\'c\'),6[1])}d 2}', 16, 16, '|i|str|strReplace|count|var|arrReplace|function|de|split|for|RegExp|g|return|new|replace'.split('|'), 0, {}))把上述代码放入https://wangye.org/tools/scripts/eval/,点击解码:
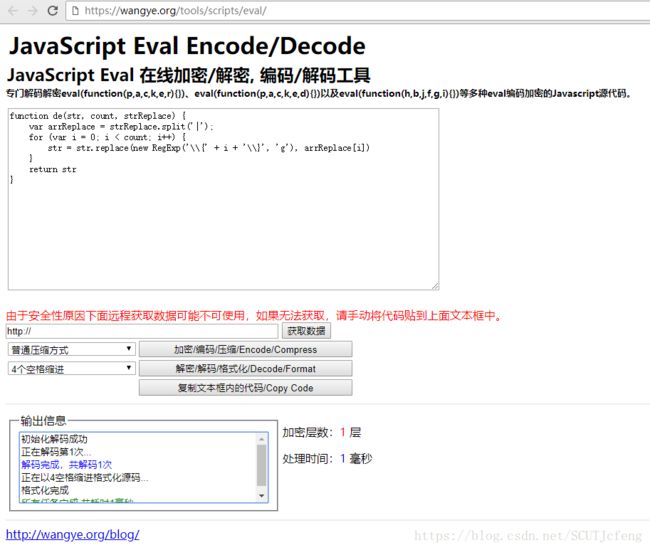
解码得到函数:
function de(str, count, strReplace) {
var arrReplace = strReplace.split('|');
for (var i = 0; i < count; i++) {
str = str.replace(new RegExp('\\{' + i + '\\}', 'g'), arrReplace[i])
}
return str
}接下来的推导类似,就不多讲了。
欢迎留言讨论。
以上。