应届生面试要点总结(8)简单算法
快速查找链表中间节点?只遍历一次。答案:建立两个指针,一个指针一次遍历两个节点,一个指针一次遍历一个节点,当快指针遍历到空节点时,慢指针直线链表的中间位置。
判断一个链表有无环,一个快指针(走两步),一个慢指针(走一步),都从头开始,若有环,则他们相撞(碰撞点x),若无环,则快指针遇到空则跳出循环。
有环则求环的长度:从碰撞点x开始,又走(一个走两步,一个走一步),当再次碰撞时,他们所走的次数为环的长度。
求连接点:碰撞点到连接点的距离等于头节点到连接点的距离。两个指针(都一次一步),一个从头节点走,一个从碰撞节点走,第一次碰撞就是连接点。
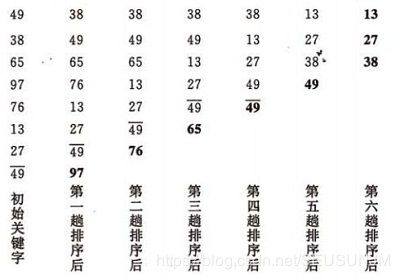
冒泡排序:对冒泡排序常见的改进方式是加入一个标志变量exchange,用于标志某一趟排序过程中是否有数据交换,若进行某一趟排序时并没有数据交换,说明数据已经按要求排好,可立即结束,避免不必要的比较。
public void maopao(int[] arr) {
int len = arr.length;
for (int i = 0; i < len - 1; i++) {
for (int j = 0; j < len - i - 1; j++) {
if (arr[j] > arr[j + 1]) // 把大的元素冒泡到后面
swap(arr, j, j + 1);
}
}
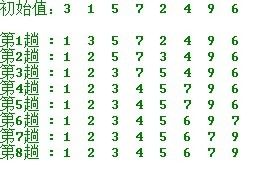
}选择排序:从n个记录中找出关键字最小的记录和第一个记录交换;从第二个记录开始的n-1个记录中再选出最小的与第二个交换,以此类推。
public void xuanze(int[] arr) {
for (int i = 0; i < a.length; i++) {
int temp = a[i];
int flag = i; // 将当前下标定义为最小值下标
for (int j = i + 1; j < a.length; j++) {
if (a[j] < temp) { // a[j] < temp 从小到大排序;a[j] > temp 从大到小排序
temp = a[j];
flag = j; // 如果有小于当前最小值的关键字将此关键字的下标赋值给flag
}
}
if (flag != i) {
a[flag] = a[i];
a[i] = temp;
}
}
}直接插入排序

public void zhijiecharu(int[] arr) {
int len = arr.length;
for (int i = 1; i < len; i++) {
for (int j = i; j > 0 && arr[j] < arr[j - 1]; j--) { // 有序相当于continue,无序相当于把小的元素不断往前换到相应的位置
swap(arr, j, j - 1);
}
}
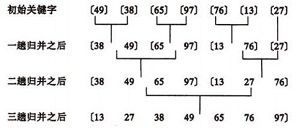
}归并排序
public void guibing(int[] arr) {
int len = arr.length;
mergesort(arr, 0, len - 1);
}
private void mergesort(int[] arr, int start, int end) {
if (start < end) {
int mid = (start + end) / 2;
mergesort(arr, start, mid);
mergesort(arr, mid + 1, end);
mergepaihaoxu(arr, start, mid, mid + 1, end);
}
}
private void mergepaihaoxu(int[] arr, int start1, int end1, int start2, int end2) {
int i = start1, j = start2;
int[] t = new int[end2 - start1 + 1];
int k = 0;
while (i <= end1 && j <= end2) {
if (arr[i] < arr[j]) {
t[k] = arr[i];
i++; k++;
} else {
t[k] = arr[j];
j++; k++;
}
}
while (i <= end1)
t[k++] = arr[i++];
while (j <= end2)
t[k++] = arr[j++];
for (int m = 0; m < t.length; m++)
arr[start1 + m] = t[m];
}快速排序


public static void quick(int[] numbers) {
if (numbers.length > 0) {
quickSort(numbers, 0, numbers.length - 1);
}
}
public static void quickSort(int[] numbers, int low, int high) {
if (low < high) {
int middle = getMiddle(numbers, low, high); // 将numbers数组进行一分为二
quickSort(numbers, low, middle - 1); // 对低字段表进行递归排序
quickSort(numbers, middle + 1, high); // 对高字段表进行递归排序
}
}
public static int getMiddle(int[] numbers, int low, int high) {
int temp = numbers[low]; //数组的第一个作为中轴
while (low < high) {
while (low < high && numbers[high] > temp) {
high--;
}
numbers[low] = numbers[high];//比中轴小的记录移到低端
while (low < high && numbers[low] < temp) {
low++;
}
numbers[high] = numbers[low]; //比中轴大的记录移到高端
}
numbers[low] = temp; //中轴记录到尾
return low; // 返回中轴的位置
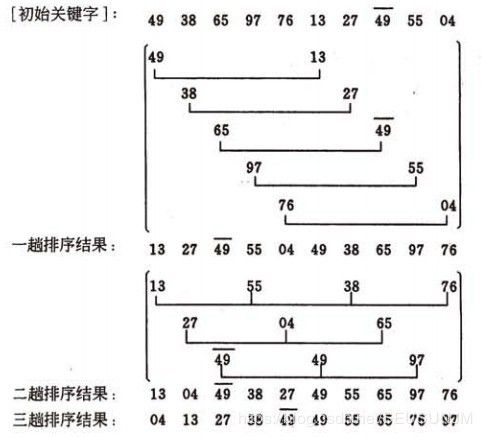
}希尔排序
public static void shell(int[] arrays) {
int incrementNum = arrays.length / 2; // 增量
while (incrementNum >=1) {
for (int i = 0; i < arrays.length; i++) { // 进行插入排序
for (int j = i; j < arrays.length - incrementNum; j = j + incrementNum) {
if (arrays[j] > arrays[j+incrementNum]) {
int temple = arrays[j];
arrays[j] = arrays[j+incrementNum];
arrays[j+incrementNum] = temple;
}
}
}
incrementNum = incrementNum / 2; // 设置新的增量
}
}堆排序
public static void adjustHeap(int[] a, int i, int len) {
int temp, j;
temp = a[i];
for (j = 2 * i; j < len; j *= 2) { // 沿关键字较大的孩子结点向下筛选
if (j < len && a[j] < a[j + 1])
++j; // j为关键字中较大记录的下标,哪个孩子值更大
if (temp >= a[j])
break;
a[i] = a[j];
i = j;
}
a[i] = temp;
}
public static void heapSort(int[] a) {
int i;
for (i = a.length / 2 - 1; i >= 0; i--) { // 先构建一个大顶堆
adjustHeap(a, i, a.length - 1);
}
for (i = a.length - 1; i >= 0; i--) { // 将堆顶记录和当前未经排序子序列的最后一个记录交换
int temp = a[0]; // 找到了最大的放到a[n - 1],再找出其他的最大的放到a[n - 2]…
a[0] = a[i];
a[i] = temp;
adjustHeap(a, 0, i - 1); // 将a中前i-1个记录重新调整为大顶堆
}
}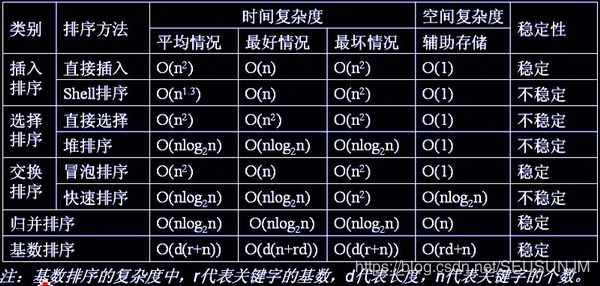
快排改进:和插入排序组合,由于快排在处理小规模数据的时候表现不好,因此在数据规模小到一定程度时,改用插入,具体小到何种程度(5-10)。中轴元素,可以取最左最右中间这三个位置的元素中的中间值。分成三堆,一方面避免相同元素,另一方面降低了子问题的规模(一堆小于一堆等于一堆大于)。
当n较小时,比如n<50,可以采用直接插入排序或直接选择排序。若文件初始状态基本有序,则应该使用直接插入,冒泡或随机的快排。
桶排序:把数组分组放在一个个的桶中,然后对每个桶里的进行排序。当n=m时,可以实现O(n),n个数字m个桶,缺点:空间复杂度高;待排序的元素要在某个范围。
内部排序:在内存中进行排序;外部排序:因排序的数量很大,一次不能容纳所有的排序记录,在排序工程中需要访问外存,归并。
两个栈实现队列:插入的元素方法stack1中,pop时,stack2不为空,则直接弹出stack2的栈顶,若stack2为空,则把stack1的元素全部弹入stack2,再pop出stack2的栈顶。
public class StackQueue {
Stack stack1 = new Stack();
Stack stack2 = new Stack();
public void push(int node) {
stack1.push(node);
}
public int pop() {
if (stack2.empty()) {
while(!stack1.empty())
stack2.push(stack1.pop());
}
return stack2.pop();
}
}
辗转相除法:用来求两个自然数的最大公约数(已知a,b,c为正数,若a除以b余数是c,则[a,b]=[b,c],其中[a,b]表示a和b的最大公约数)
public int gongyueshu(int a, int b) {
int c = a % b;
while (c != 0) {
a = b;
b = c;
c = a % b;
}
return b;
}
算法基本概念:输入,输出,有穷,确切,可行。
AOV网:用顶点表示活动,用弧表示活动间的优先关系,在网中,若顶点i到j有一条有向路径,则i为j前驱。对于一个AOV网,最早完成时间=最晚完成时间的点构成的路径称为关键路径。一个AOV网的拓扑排序可能不唯一。
对AOV网进行排序的基本思想:从AOV网中选择一个没有前驱的点输出;从AOV中去掉该点,并且删除去掉以该点结尾的弧;重复上述步骤,直到所有点输出或AOV网中不存在无前驱的点。
0-1背包问题
if (背包体积j < 物品i的体积)
f[i][j] = f[i - 1][j] // 背包装不下第i个物体,目前只能靠前i-1个物体装包
else
f[i][j] = max(f[i - 1][j], f[i - 1][j - Vi] + Wi) // Vi表示第i件物体的体积,Wi表示第i件物品的价值。
完全背包
f[i][j] = max{f[i - 1][v], f[i - 1][v - k * c[i]] + k * w[i]} (0 <= k*c[i] <= v)
for (int i = 1; i < n; i++) {
for (int j = 1; j <= v; j++) {
for (int k = 0; k * c[i] <= j; k++) {
if (c[i] <= j) // 如果能放下
f[i][j] = max{f[i - 1][j], f[i - 1][j - k * c[i]] + k * w[i]}; // 要么不取,要么取0件、取1件、取2件……取k件
else // 放不下的话
f[i][j] = f[i - 1][j]; // 继承前i个物品在当前空间大小时的价值
}
}
}
最短路
Floyed-Warshall算法 O(N^3)
(a)初始化:点i,j如果有边相连,则dis[i][j] = w[i][j]。如果不相连,则dis[i][j] = 0x7fffffff(int极限值),表示两点不相连(或认为相隔很远)。
(b)算法代码:
for(int k = 1; k <= n; k++) // 枚举中间点(必须放最外层)
for(int i = 1; i <= n; i++) // 枚举端点i
if(i != k)
for(int j = 1; j <= n; j++) // 枚举端点j
if(i != j && j != k && dis[i][j] > dis[i][k] + dis[k][j])
dis[i][j] = dis[i][k] + dis[k][j];
(c)算法结束:dis[i][j]得出的就是从i到j的最短路径。
Dijkstra迪杰斯特拉算法 O(N^2)
(a)初始化:dis[v] = oo (v != s); dis[s] = 0; pre[s] = 0;
(b)for(int i = 1; i <= n; i++)
1.在没有被访问过的点中找一个顶点u使得dis[u]是最小的。
2.u标记为已确定最短路径。
3.for与u相连的每个未确定最短路径的顶点v。
if(dis[u] + w[u][v] < dis[v]) {
dis[v] = dis[u] + w[u][v];
pre[v] = u;
}
(c)算法结束:dis[v] 为 s 到 v 的最短距离;pre[v]为 v 的前驱节点,用来输出路径。
求栈中元素最大值
常数时间:一个存储所有最大值的栈Sm。1. 当push入栈的元素大于当前最大元素,将该元素压入最大值栈Sm;2. Sm栈顶始终保存栈中当前的最大元素;3. 当前最大元素被pop出栈时,将Sm栈顶的对应最大元素也弹出栈。max操作即为获得Sm栈顶最大元素。
常数时间空间:变量Max保存当前最大元素值,初始值为最小整数m。
1. 当push入栈时,将(当前元素-Max)存入栈中,若当前元素小于Max,栈中元素为负数;若当前元素大于等于Max,栈中元素为非负数,将Max替换为当前元素。
2. 当pop出栈时,若栈中元素为负数,则将(栈中元素+Max)弹出栈;若栈中元素为非负数,则将Max弹出栈,并将Max替换为(Max-栈中元素)。
3. Max即为当前栈中最大元素值。
链表倒数第k个节点:设置两个指针,一个快指针、一个慢指针,快指针和慢指针开始时都指向链表第一个节点,然后让快指针向后走k-1个节点,再让满指针和快指针同时向后走,当快指针指向的下一个节点为空时,慢指针所指向的节点即为所求。
一个数的集合,里面只有一个数不同,其他都成对出现,怎么找?所有数异或。
KMP:https://blog.csdn.net/u011564456/article/details/20862555
DFS和BFS
public void searchTraversing(GraphNode node, List visited) {
if (visited.contains(node)) { // 判断是否遍历过
return;
}
visited.add(node);
for (int i = 0; i < node.edgeList.size(); i++) {
searchTraversing(node.edgeList.get(i).getNodeRight(), visited);
}
}
public void searchTraversing(GraphNode node) {
List visited = new ArrayList(); // 已经被访问过的元素
Queue q = new LinkedList(); // 用队列存放依次要遍历的元素
q.offer(node);
while (!q.isEmpty()) {
GraphNode currNode = q.poll();
if (!visited.contains(currNode)) {
visited.add(currNode);
for (int i = 0; i < currNode.edgeList.size(); i++) {
q.offer(currNode.edgeList.get(i).getNodeRight());
}
}
}
}
二分查找
public int recursionBinarySearch(int[] arr, int key, int low, int high) { // 递归
if (key < arr[low] || key > arr[high] || low > high) {
return -1;
}
int middle = (low + high) / 2; // 初始中间位置
if (arr[middle] > key) { // 比关键字大则关键字在左区域
return recursionBinarySearch(arr, key, low, middle - 1);
} else if (arr[middle] < key) { // 比关键字小则关键字在右区域
return recursionBinarySearch(arr, key, middle + 1, high);
} else {
return middle;
}
}
public int commonBinarySearch(int[] arr,int key) { // 循环
int low = 0;
int high = arr.length - 1;
int middle = 0; // 定义middle
if (key < arr[low] || key > arr[high] || low > high) {
return -1;
}
while (low <= high) {
middle = (low + high) / 2;
if (arr[middle] > key) { // 比关键字大则关键字在左区域
high = middle - 1;
} else if (arr[middle] < key) { // 比关键字小则关键字在右区域
low = middle + 1;
}else {
return middle;
}
}
return -1; // 最后仍然没有找到,则返回-1
}