【深度学习介绍系列之二】——深度强化学习:卷积神经网络
介绍深度学习强化学习中的卷积神经网络
卷积神经网络的大致介绍我们在前一篇文章深度强化学习(一)中已经说过了。本篇文章会详细介绍卷积神经网络的起源,发展和应用。本篇文章我们会从以下几个方面介绍:
1)神经网络是什么
2)卷积神经网络的起源与经典结构
3)卷积网络的发展
4)总结。
一,神经网络是什么
我们这里说的神经网络不是生物学上的神经网络,而是计算机模拟生物学的人工神经网络。所谓人工神经网络就是基于模仿生物大脑的结构和功能而构成的一种信息处理系统。粗略地讲,大脑是由大量神经细胞或神经元组成的(入图1.1)。每个神经元可看作是一个小的处理单元,这些神经元按某种方式连接起来,形成大脑内部的生理神经元网络。这种神经元网络中各神经元之间联结的强弱,按外部的激励信号做自适应变化,而每个神经元又随着所接收到的多个接收信号的综合大小而呈现兴奋或抑制状态。现已明确大脑的学习过程就是神经元之间连接强度随外部激励信息做自适应变化的过程,而大脑处理信息的结果则由神经元的状态表现出来。而人工神经网络就是模拟大脑的神经元组合方式进行信息处理。
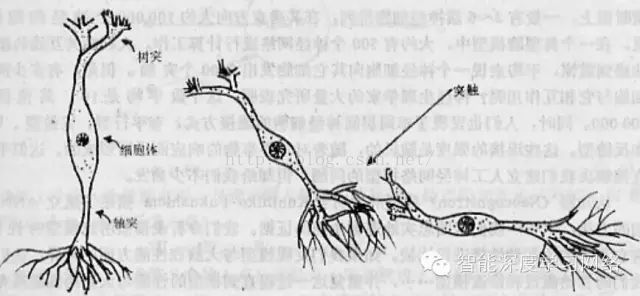
图1.1 大脑的神经元
上面废话了那么多,那现在来介绍下神经网络到底是怎样的。神经网络的基本单元就是神经元,跟大脑的神经元类似,处理输入的激励信号的。结构如图12所示。
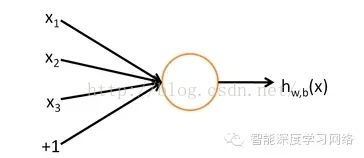
图1.2 神经元模型
这个“神经元”是一个以  及截距
及截距  为输入值的运算单元,其输出为
为输入值的运算单元,其输出为
 ,其中函数
,其中函数 被称为“激活函数”。
被称为“激活函数”。
在本教程中,我们选用sigmoid函数作为激活函数 可以看出,这个单一“神经元”的输入-输出映射关系其实就是一个逻辑回归(logistic regression)[逻辑回归将在后续的章节介绍]。其实激活函数也可以选择双曲正切函数(tanh)。函数图形如图1.3所示。
可以看出,这个单一“神经元”的输入-输出映射关系其实就是一个逻辑回归(logistic regression)[逻辑回归将在后续的章节介绍]。其实激活函数也可以选择双曲正切函数(tanh)。函数图形如图1.3所示。
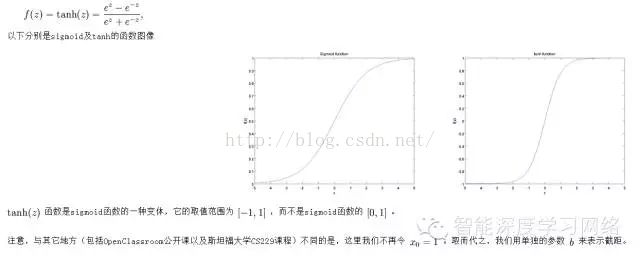
图1.3 sigmod函数和双曲正切函数图
介绍完单个神经元,现在该介绍神经网络了。所谓神经网络就是将许多个单一“神经元”联结在一起,这样,一个“神经元”的输出就可以是另一个“神经元”的输入。首先给大家展示一个简单的神经网络的图形,如图1.4所示。
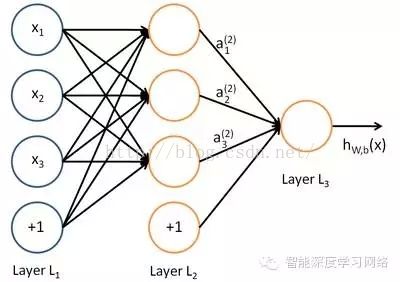
. 图1.4 神经网络图形
我们使用圆圈来表示神经网络的输入,标上“”的圆圈被称为偏置节点,也就是截距项。神经网络最左边的一层叫做输入层,最右的一层叫做输出层(本例中,输出层只有一个节点)。中间所有节点组成的一层叫做隐藏层,因为我们不能在训练样本集中观测到它们的值。同时可以看到,以上神经网络的例子中有3个输入单元(偏置单元不计在内),3个隐藏单元及一个输出单元。本例神经网络的计算步骤如下:W表示神经元节点间的输入权值,x表示神经元的输入,a是神经元的输出。

我们将上面的计算步骤叫作前向传播。
神经网络也可以有多个输出单元。比如,下面的神经网络有两层隐藏层:  及
及  ,输出层
,输出层  有两个输出单元
有两个输出单元
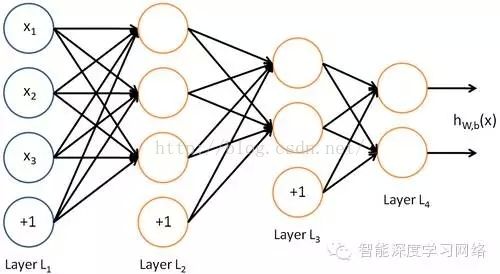
上面已经把神经网络构建好了,但是神经网络的参数应该怎么设置呢?这里的参数就是神经元之间的连接权值Wij。神经网络的参数训练是最重要的内容之一,因为参数决定了输入到输出的响应(映射)。一般我们先随机初始化w的值,然后根据训练样本集 来进行训练调整w值,让神经网络对训练样本输入的x响应结果f(x)逼近与样本的y值,当神经网络对所有样本都逼近的误差最小的时候,我们认为这个神经网络对于样本集的映射函数y=f(x)拟合好了。
来进行训练调整w值,让神经网络对训练样本输入的x响应结果f(x)逼近与样本的y值,当神经网络对所有样本都逼近的误差最小的时候,我们认为这个神经网络对于样本集的映射函数y=f(x)拟合好了。
上面废话了那么多,其实就是让输入x产生的f(x)尽量等于y,而调整参数的过程就是依据每次error = f(x)-y的误差来调整参数,使得error变小。从而我们把w的训练转换成了求取误差最小的目标。那神经网络里面到底具体怎么做的呢?采用反向传播算法BP。下面我们重点介绍反向传播算法:

J(w,b,x,y)表示的输出值和样本的平方误差,J(w,b)的第一项是一个均方差项。第二项是一个规则化项(也叫权重衰减项),其目的是减小权重的幅度,防止过度拟合。
我们需要做的就是让J误差最小,这里就变成了一个优化问题,求取最小值,即最优解。我们采用最快下降算法进行求解最小值。

其中 是学习速率。我们通过反复迭代,从最后一层的误差逐次向前传播来调整各层的权值W。反向传播算法的具体步骤如下:
是学习速率。我们通过反复迭代,从最后一层的误差逐次向前传播来调整各层的权值W。反向传播算法的具体步骤如下:

好了,神经网络的概念和结构以及如何进行参数训练求解已经大致说完了,下面接着介绍卷积神经网络吧。
二,卷积神经网络
卷积神经网络是人工神经网络的一种,已成为当前语音分析和图像识别领域的研究热点。它的权值共享网络结构使之更类似于生物神经网络,降低了网络模型的复杂度,减少了权值的数量。该优点在网络的输入是多维图像时表现的更为明显,使图像可以直接作为网络的输入,避免了传统识别算法中复杂的特征提取和数据重建过程。卷积网络是为识别二维形状而特殊设计的一个多层感知器,这种网络结构对平移、比例缩放、倾斜或者共他形式的变形具有高度不变性。
回想一下BP神经网络。BP网络每一层节点是一个线性的一维排列状态,层与层的网络节点之间是全连接的。这样设想一下,如果BP网络中层与层之间的节点连接不再是全连接,而是局部连接的。这样,就是一种最简单的一维卷积网络。如果我们把上述这个思路扩展到二维,这就是我们在大多数参考资料上看到的卷积神经网络。具体参看下图:

卷积网络在有监督方式下学会的,网络的结构主要有稀疏连接和权值共享两个特点,包括如下形式的约束:
1、 特征提取。每一个神经元从上一层的局部接受域得到突触输人,因而迫使它提取局部特征。一旦一个特征被提取出来, 只要它相对于其他特征的位置被近似地保留下来,它的精确位置就变得没有那么重要了。
2 、特征映射。网络的每一个计算层都是由多个特征映射组成的,每个特征映射都是平面形式的。平面中单独的神经元在约束下共享 相同的突触权值集,这种结构形式具有如下的有益效果:a.平移不变性。b.自由参数数量的缩减(通过权值共享实现)。
3、子抽样。每个卷积层后面跟着一个实现局部平均和子抽样的计算层,由此特征映射的分辨率降低。这种操作具有使特征映射的输出对平移和其他 形式的变形的敏感度下降的作用。

稀疏连接(Sparse Connectivity)
卷积网络通过在相邻两层之间强制使用局部连接模式来利用图像的空间局部特性,在第m层的隐层单元只与第m-1层的输入单元的局部区域有连接,第m-1层的这些局部 区域被称为空间连续的接受域。我们可以将这种结构描述如下:
设第m-1层为视网膜输入层,第m层的接受域的宽度为3,也就是说该层的每个单元与且仅与输入层的3个相邻的神经元相连,第m层与第m+1层具有类似的链接规则,如下图所示。
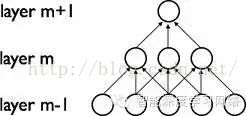
可以看到m+1层的神经元相对于第m层的接受域的宽度也为3,但相对于输入层的接受域为5,这种结构将学习到的过滤器(对应于输入信号中被最大激活的单元)限制在局部空间 模式(因为每个单元对它接受域外的variation不做反应)。从上图也可以看出,多个这样的层堆叠起来后,会使得过滤器(不再是线性的)逐渐成为全局的(也就是覆盖到了更 大的视觉区域)。例如上图中第m+1层的神经元可以对宽度为5的输入进行一个非线性的特征编码。
权值共享(Shared Weights)
在卷积网络中,每个稀疏过滤器hi通过共享权值都会覆盖整个可视域,这些共享权值的单元构成一个特征映射,如下图所示。

在图中,有3个隐层单元,他们属于同一个特征映射。同种颜色的连接权值是相同的,我们仍然可以使用梯度下降的方法来学习这些权值,只需要对原始算法做一些小的改动, 这里共享权值的梯度是所有共享参数的梯度的总和。我们不禁会问为什么要权重共享呢?一方面,重复单元能够对特征进行识别,而不考虑它在可视域中的位置。另一方面,权值 共享使得我们能更有效的进行特征抽取,因为它极大的减少了需要学习的自由变量的个数。通过控制模型的规模,卷积网络对视觉问题可以具有很好的泛化能力。
The Full Model
卷积神经网络是一个多层的神经网络,每层由多个二维平面组成,而每个平面由多个独立神经元组成。网络中包含一些简单元和复杂元,分别记为S-元 和C-元。S-元聚合在一起组成S-面,S-面聚合在一起组成S-层,用Us表示。C-元、C-面和C-层(Us)之间存在类似的关系。网络的任一中间级由S-层与C-层 串接而成,而输入级只含一层,它直接接受二维视觉模式,样本特征提取步骤已嵌入到卷积神经网络模型的互联结构中。
一般地,Us为特征提取层(子采样层),每个神经元的输入与前一层的局部感受野相连,并提取该局部的特征,一旦该局部特征被提取后,它与其他特征间的位置关系 也随之确定下来;Uc是特征映射层(卷积层),网络的每个计算层由多个特征映射组成,每个特征映射为一个平面,平面上所有神经元的权值相等。特征映射结构采用 影响函数核小的sigmoid函数作为卷积网络的激活函数,使得特征映射具有位移不变性。此外,由于 一个映射面上的神经元共享权值,因而减少了网络自由参数的个数,降低了网络参数选择的复杂度。卷积神经网络中的每一个特征提取层(S-层)都紧跟着一个 用来求局部平均与二次提取的计算层(C-层),这种特有的两次特征提取结构使网络在识别时对输入样本有较高的畸变容忍能力。
下图是一个卷积网络的实例,在博文”Deep Learning模型之:CNN卷积神经网络(二) 文字识别系统LeNet-5 “中有详细讲解:

图中的卷积网络工作流程如下,输入层由32×32个感知节点组成,接收原始图像。然后,计算流程在卷积和子抽样之间交替进行,如下所述:
第一隐藏层进行卷积,它由8个特征映射组成,每个特征映射由28×28个神经元组成,每个神经元指定一个 5×5 的接受域,这28×28个神经元共享5×5个权值参数,即卷积核;
第二隐藏层实现子 抽样和局部平均,它同样由 8 个特征映射组成,但其每个特征映射由14×14 个神经元组成。每个神经元具有一个 2×2 的接受域,一个可训练 系数,一个可训练偏置和一个 sigmoid 激活函数。可训练系数和偏置控制神经元的操作点;
第三隐藏层进行第二次卷积,它由 20 个特征映射组 成,每个特征映射由 10×10 个神经元组成。该隐藏层中的每个神经元可能具有和下一个隐藏层几个特征映射相连的突触连接,它以与第一个卷积 层相似的方式操作。
第四个隐藏层进行第二次子抽样和局部平均汁算。它由 20 个特征映射组成,但每个特征映射由 5×5 个神经元组成,它以 与第一次抽样相似的方式操作。
第五个隐藏层实现卷积的最后阶段,它由 120 个神经元组成,每个神经元指定一个 5×5 的接受域。
最后是个全 连接层,得到输出向量。
相继的计算层在卷积和抽样之间的连续交替,我们得到一个“双尖塔”的效果,也就是在每个卷积或抽样层,随着空 间分辨率下降,与相应的前一层相比特征映射的数量增加。卷积之后进行子抽样的思想是受到动物视觉系统中的“简单的”细胞后面跟着“复杂的”细胞的想法的启发而产生的。
下面回顾下卷积是怎样做的

再看看池化怎么做的:

三,最新的卷积神经网络结构
首先看下2014年CVPR的一个卷积神经网络的结构:

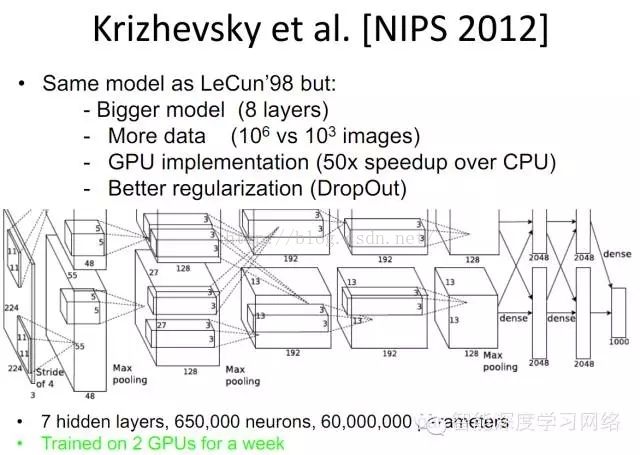
再看2102年结构:
四,总结
CNNs中这种层间联系和空域信息的紧密关系,使其适于图像处理和理解。而且,其在自动提取图像的显著特征方面还表现出了比较优的性能。在一些例子当中,Gabor滤波器已经被使用在一个初始化预处理的步骤中,以达到模拟人类视觉系统对视觉刺激的响应。在目前大部分的工作中,研究者将CNNs应用到了多种机器学习问题中,包括人脸识别,文档分析和语言检测等。为了达到寻找视频中帧与帧之间的相干性的目的,目前CNNs通过一个时间相干性去训练,但这个不是CNNs特有的。
特别声明:
上面大部分内容摘录与网上的各种教程,本人就是稍微编辑一下,给贴上来了,如有雷同,纯属正常。